







下面是我在学习HTML和CSS的时候整理的一些笔记,有兴趣的可以看下:

进阶阶段
进阶阶段,开始攻 JS,对于刚接触 JS 的初学者,确实比学习 HTML 和 CSS 有难度,但是只要肯下功夫,这部分对于你来说,也不是什么大问题。
JS 内容涉及到的知识点较多,看到网上有很多人建议你从头到尾抱着那本《JavaScript高级程序设计》学,我是不建议的,毕竟刚接触 JS 谁能看得下去,当时我也不能,也没那样做。
我这部分的学习技巧是,增加次数,减少单次看的内容。就是说,第一遍学习 JS 走马观花的看,看个大概,去找视频以及网站学习,不建议直接看书。因为看书看不下去的时候很打击你学下去的信心。
然后通过一些网站的小例子,开始动手敲代码,一定要去实践、实践、实践,这一遍是为了更好的去熟悉 JS 的语法。别只顾着来回的看知识点,眼高手低可不是个好习惯,我在这吃过亏,你懂的。
1、JavaScript 和 ES6
在这个过程你会发现,有很多 JS 知识点你并不能更好的理解为什么这么设计,以及这样设计的好处是什么,这就逼着让你去学习这单个知识点的来龙去脉,去哪学?第一,书籍,我知道你不喜欢看,我最近通过刷大厂面试题整理了一份前端核心知识笔记,比较书籍更精简,一句废话都没有,这份笔记也让我通过跳槽从8k涨成20k。

2、前端框架
前端框架太多了,真的学不动了,别慌,其实对于前端的三大马车,Angular、React、Vue 只要把其中一种框架学明白,底层原理实现,其他两个学起来不会很吃力,这也取决于你以后就职的公司要求你会哪一个框架了,当然,会的越多越好,但是往往每个人的时间是有限的,对于自学的学生,或者即将面试找工作的人,当然要选择一门框架深挖原理。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
以 Vue 为例,我整理了如下的面试题。

- [9.3split(string[, maxsplit]) | re.split(pattern, string[, maxsplit])](#93splitstring_maxsplit__resplitpattern_string_maxsplit_84)
- [9.4 findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags])](#94_findallstring_pos_endpos__refindallpattern_string_flags_86)
- [9.5 finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags])](#95_finditerstring_pos_endpos__refinditerpattern_string_flags_88)
- [9.6 sub(repl, string[, count]) | re.sub(pattern, repl, string[, count])](#96_subrepl_string_count__resubpattern_repl_string_count_90)
- [9.7 subn(repl, string[, count]) |re.sub(pattern, repl, string[, count])](#97_subnrepl_string_count_resubpattern_repl_string_count_92)
+ [十、re.match函数](#rematch_94)
+ - [10.1 实例 1](#101__1_107)
- [10.2 实例 2](#102__2_121)
+ [十一、re.search方法](#research_143)
+ - [11.1 实例一](#111__151)
- [11.2 实例二](#112__159)
+ [十二、search和match区别](#searchmatch_180)
+ - [12.1 实例](#121__182)
+ [十三、检索和替换](#_207)
+ - [13.1 实例](#131__217)
+ [十四、正则表达式修饰符 - 可选标志](#___256)
+ [十五、正则表达式模式](#_259)
+ [十六、正则表达式实例](#_272)
一、前言
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
在python中使用正则表达式,需要引入re模块;下面介绍下该模块中的一些方法;
二、compile和match
2.1 compile
re模块中compile用于生成pattern对象,再通过调用pattern实例的match方法处理文本最终获得match实例;通过使用match获得信息;
import re
# 将正则表达式编译成Pattern对象
pattern = re.compile(r'rlovep')
# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
m = pattern.match('rlovep.com')
if m:
# 使用Match获得分组信息
print(m.group())
### 输出 ###
# rlovep
re.compile(strPattern[, flag]):这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。第二个参数flag是匹配模式,取值可以使用按位或运算符’|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)M(MULTILINE): 多行模式,改变’^‘和’$'的行为;S(DOTALL): 点任意匹配模式,改变’.'的行为;L(LOCALE): 使预定字符类\w \W \b \B \s \S取决于当前区域设定;U(UNICODE): 使预定字符类\w \W \b \B \s \S \d \D取决于unicode定义的字符属性;X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
2.2 Match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
string: 匹配时使用的文本。re: 匹配时使用的Pattern对象。pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
三、group([group1, …])
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
四、groups([default])
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
4.1 groupdict([default])
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
五、start([group])
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
六、end([group])
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
七、span([group])
返回(start(group), end(group))。
八、expand(template)
将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、 \g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达 \1之后是字符’0’,只能使用\g<1>0。
九、pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
pattern: 编译时用的表达式字符串。flags: 编译时用的匹配模式。数字形式。groups: 表达式中分组的数量。groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内。
实例方法[ | re模块方法]:
9.1 match(string[, pos[, endpos]]) | re.match(pattern, string[, flags])
这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符’$'。
9.2 search(string[, pos[, endpos]]) | re.search(pattern, string[, flags])
这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。 pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
9.3split(string[, maxsplit]) | re.split(pattern, string[, maxsplit])
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
9.4 findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串。
9.5 finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags])
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
9.6 sub(repl, string[, count]) | re.sub(pattern, repl, string[, count])
使用repl替换string中每一个匹配的子串后返回替换后的字符串。 当repl是一个字符串时,可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。 当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。 count用于指定最多替换次数,不指定时全部替换。
9.7 subn(repl, string[, count]) |re.sub(pattern, repl, string[, count])
返回 (sub(repl, string[, count]), 替换次数)。
十、re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:re.match(pattern, string, flags=0)
函数参数说明:
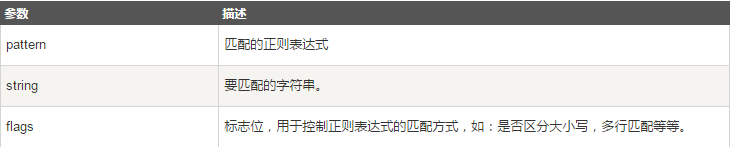
匹配成功re.match方法返回一个匹配的对象,否则返回None。
可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。

10.1 实例 1
#!/usr/bin/python
# -\*- coding: UTF-8 -\*-
import re
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配
以上实例运行输出结果为:
(0, 3)
None
10.2 实例 2
#!/usr/bin/python3
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.\*) are (.\*?) .\*', line, re.M|re.I)
if matchObj:
print ("matchObj.group() : ", matchObj.group())
print ("matchObj.group(1) : ", matchObj.group(1))
print ("matchObj.group(2) : ", matchObj.group(2))
else:
print ("No match!!")
以上实例执行结果如下:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
十一、re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:re.search(pattern, string, flags=0)
函数参数说明:
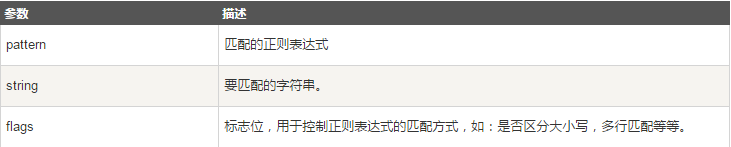
匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。

11.1 实例一
下面是我在学习HTML和CSS的时候整理的一些笔记,有兴趣的可以看下:
进阶阶段
进阶阶段,开始攻 JS,对于刚接触 JS 的初学者,确实比学习 HTML 和 CSS 有难度,但是只要肯下功夫,这部分对于你来说,也不是什么大问题。
JS 内容涉及到的知识点较多,看到网上有很多人建议你从头到尾抱着那本《JavaScript高级程序设计》学,我是不建议的,毕竟刚接触 JS 谁能看得下去,当时我也不能,也没那样做。
我这部分的学习技巧是,增加次数,减少单次看的内容。就是说,第一遍学习 JS 走马观花的看,看个大概,去找视频以及网站学习,不建议直接看书。因为看书看不下去的时候很打击你学下去的信心。
然后通过一些网站的小例子,开始动手敲代码,一定要去实践、实践、实践,这一遍是为了更好的去熟悉 JS 的语法。别只顾着来回的看知识点,眼高手低可不是个好习惯,我在这吃过亏,你懂的。
1、JavaScript 和 ES6
在这个过程你会发现,有很多 JS 知识点你并不能更好的理解为什么这么设计,以及这样设计的好处是什么,这就逼着让你去学习这单个知识点的来龙去脉,去哪学?第一,书籍,我知道你不喜欢看,我最近通过刷大厂面试题整理了一份前端核心知识笔记,比较书籍更精简,一句废话都没有,这份笔记也让我通过跳槽从8k涨成20k。
2、前端框架
前端框架太多了,真的学不动了,别慌,其实对于前端的三大马车,Angular、React、Vue 只要把其中一种框架学明白,底层原理实现,其他两个学起来不会很吃力,这也取决于你以后就职的公司要求你会哪一个框架了,当然,会的越多越好,但是往往每个人的时间是有限的,对于自学的学生,或者即将面试找工作的人,当然要选择一门框架深挖原理。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
以 Vue 为例,我整理了如下的面试题。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









