







多进程应该避免共享资源。在多线程中,我们可以比较容易地共享资源,比如使用全局变量或者传递参数。在多进程情况下,由于每个进程有自己独立的内存空间,以上方法并不合适。此时我们可以通过共享内存和Manager的方法来共享资源。
但这样做提高了程序的复杂度,并因为同步的需要而降低了程序的效率。 5、Python
里面如何拷贝一个对象?
标准库中的copy模块提供了两个方法来实现拷贝。一个方法是copy,它返回和参数包含内容一样的对象。使用deepcopy方法,对象中的属性也被复制。
6、介绍一下except的用法和作用?
Python的except用来捕获所有异常,因为Python里面的每次错误都会抛出一个异常,所以每个程序的错误都被当作一个运行时错误。
7 、Python中pass语句的作用是什么?
pass语句什么也不做,一般作为占位符或者创建占位程序,pass语句不会执行任何操作。
8、Python解释器种类以及特点?
Python是一门解释器语言,代码想运行,必须通过解释器执行,Python存在多种解释器,分别基于不同语言开发,每个解释器有不同的特点,但都能正常运行Python代码,以下是常用的五种Python解释器:
CPython:当从Python官方网站下载并安装好Python2.7后,就直接获得了一个官方版本的解释器:Cpython,这个解释器是用C语言开发的,所以叫CPython,在命名行下运行python,就是启动CPython解释器,CPython是使用最广的Python解释器。 IPython:IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的,好比很多国产浏览器虽然外观不同,但内核其实是调用了IE。
PyPy:PyPy是另一个Python解释器,它的目标是执行速度,PyPy采用JIT技术,对Python代进行动态编译,所以可以显著提高Python代码的执行速度。
Jython:Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
IronPython:IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
在Python的解释器中,使用广泛的是CPython,对于Python的编译,除了可以采
用以上解释器进行编译外,技术高超的开发者还可以按照自己的需求自行编写Python解释器来执行
Python代码,十分的方便! 9、列举布尔值为
False的常见值?
0, [] , () , {} , '' , False , None 10、字符串、列表、元组、字典每个常用的
5个方法?
字符串:repleace,strip,split,reverse,upper,lower,join.....
列表:append,pop,,remove,sort,count,index.....
元组:index,count,__len__(),__dir__()
字典:get,keys,values,pop,popitems,clear,,items..... 11、lambda表达式格式以及应用场景?
表达式格式:lambda后面跟一个或多个参数,紧跟一个冒号,以后是一个表达式。冒号前是参数,冒号后是返回值。例如:lambda x : 2x
应用场景:经
常与一些内置函数
相结合使用,
比如说
map(),filter(),sorted(),reduce()等
12、pass的作用?
①空语句do nothing;
②保证格式完整;
③保证语义完整。 13、arg
和 \*kwarg作用?
万能参数,解决了函数参数不固定的问题
\*arg:会把位置参数转化为tuple
\*\*kwarg:会把关键字参数转化为dict
14、is和==的区别?
is:判断内存地址是否相等; ==:判断数值是否相等。
15、简述Python的深浅拷贝以及应用场景?
copy():浅copy,浅拷贝指仅仅拷贝数据集合的第一层数据 deepcopy():深copy,深拷贝指拷贝数据集合的所有层
16、Python垃圾回收机制?
python采用的是引用计数机制为主,标记-清除和分代收集(隔代回收、分代回收)两种机制为辅的策略 计数机制:
Python的GC模块主要运用了引用计数来跟踪和回收垃圾。在引用计数的基础上,还可以通过“标记-清除”
解决容器对象可能产生的循环引用的问题。通过分代回收以空间换取时间进一步提高垃圾回收的效率。 标记-清除:
标记-清除的出现打破了循环引用,也就是它只关注那些可能会产生循环引用的对象。
缺点:该机制所带来的额外操作和需要回收的内存块成正比。隔代回收:
原理:将系统中的所有内存块根据其存活时间划分为不同的集合,每一个集合就成
为一个“代”,
垃圾收集的频率随着“代”的存活时间的增大而减小。也就是说,活得越长的对象,就越不可能是垃圾,
就应该减少对它的垃圾收集频率。那么如何来衡量这个存活时间:通常是利用几次垃圾收集动作来衡量,
如果一个对象经过的垃圾收集次数越多,可以得出:该对象存活时间就越长。 17、python的可变类型和不可变类型?
不可变类型(数字、字符串、元组、不可变集合);
可变类型(列表、字典、可变集合)。
18、Python里面search()和match()的区别?
match()函数只检测RE是不是在string的开始位置匹配,search()会扫描整个
string查找匹配, 也就是说match()
只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,
match()就返回none
19、用Python匹配HTML tag的时候,<.*>和<.*?>有什么区别?
前者是贪婪匹配,会从头到尾匹配 xyz,而后者是非贪婪匹配,只匹配到第一个 >。
20、Python里面如何生成随机数? import random;
random.random();
### 2021年最新Python面试题及答案
1、Python里面如何拷贝一个对象?(赋值,浅拷贝,深拷贝的区别)
答:赋值(=),就是创建了对象的一个新的引用,修改其中任意一个变量都会影响到另一个。
浅拷贝:创建一个新的对象,但它包含的是对原始对象中包含项的引用(如果用引用的方式修改其中一个对象,另外一个也会修改改变){1,完全切片方法;2,工厂函数,如list();3,copy模块的copy()函数}
深拷贝:创建一个新的对象,并且递归的复制它所包含的对象(修改其中一个,另外一个不会改变){copy模块的()函数}
2、Python里面match()和search()的区别?
答:re模块中match(pattern,string[,flags]),检查string的开头是否与pattern匹配。
re模块中research(pattern,string[,flags]),在string搜索pattern的第一个匹配值。
>
>
> >
> >
> > >
> > > print(‘super’, ‘superstition’).span())
> > > (0, 5)
> > > print(‘super’, ‘insuperable’))
> > > None
> > > print(‘super’, ‘superstition’).span())
> > > (0, 5)
> > > print(‘super’, ‘insuperable’).span())
> > > (2, 7)
> > > 3、有没有一个工具可以帮助查找python的bug和进行静态的代码分析?
> > > 答:PyChecker是一个python代码的静态分析工具,它可以帮助查找python代码的bug, 会对代码的复杂度和格式提出警告
> > > Pylint是另外一个工具可以进行codingstandard检查
> > > 4、简要描述Python的垃圾回收机制(garbage collection)。
> > > 答案
> > > 这里能说的很多。你应该提到下面几个主要的点:
> > > Python在内存中存储了每个对象的引用计数(reference count)。如果计数值变成0,那么相应的对象就会小时,分配给该对象的内存就会释放出来用作他用。
> > > 偶尔也会出现引用循环(reference cycle)。垃圾回收器会定时寻找这个循环,并将其回收。举个例子,假设有两个对象o1和o2,而且符合 == o2和 == o1这两个条件。如果o1和o2没有其他代码引用,那么它们就不应该继续存在。但它们的引用计数都是1。
> > > Python中使用了某些启发式算法(heuristics)来加速垃圾回收。例如,越晚创建的对象更有可能被回收。对象被创建之后,垃圾回收器会分配它们所属的代(generation)。每个对象都会被分配一个代,而被分配更年轻代的对象是优先被处理的。
> > > 5、什么是lambda函数?它有什么好处?
> > > 答:lambda 表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数
> > > lambda函数:首要用途是指点短小的回调函数
> > > lambda [arguments]:expression
> > > a=lambdax,y:x+y
> > > a(3,11)
> > > 6、请写出一段Python代码实现删除一个list里面的重复元素
> > > 答:
> > > 1,使用set函数,set(list)
> > > 2,使用字典函数,
> > > a=[1,2,4,2,4,5,6,5,7,8,9,0]
> > > b={}
> > > b=(a)
> > > c=list())
> > > c
> > > 7、用Python匹配HTML tag的时候,<.*>和<.*?>有什么区别?
> > > 答:术语叫贪婪匹配( <.*> )和非贪婪匹配(<.*?> )
> > > 例如:
> > > test
> > > <.*> :
> > > test
> > > <.*?> :
> > > 8、如何在一个function里面设置一个全局的变量?
> > > 答:解决方法是在function的开始插入一个global声明:
> > > def f()
> > > global x
> > > 9、编程用sort进行排序,然后从最后一个元素开始判断
> > > a=[1,2,4,2,4,5,7,10,5,5,7,8,9,0,3]
> > > ()
> > > last=a[-1]
> > > for i inrange(len(a)-2,-1,-1):
> > > if last==a[i]:
> > > del a[i]
> > > else:last=a[i]
> > > print(a)
> > > 10、下面的代码在Python2中的输出是什么?解释你的答案
> > > def div1(x,y):
> > > print “%s/%s = %s” % (x, y, x/y)
> > >
> > >
> > >
> >
> >
> >
>
>
>
def div2(x,y):
print "%s2)
div2(5,2)
div2(5.,2.)
另外,在Python3中上面的代码的输出有何不同(假设代码中的print语句都转化成了Python3中的语法结构)?
在Python2中,代码的输出是:
5/2 = 2
2 =
52结果是
注意你可以通过下面的import语句来覆盖Python2中的这一行为
from **future** import division
还要注意“双斜杠”(//)操作符将会一直执行整除,忽略操作数的类型。这就是为什么/即使在Python2中结果也是
但是在Python3并没有这一行为。两个操作数都是整数时,也不执行整数运算。在Python3中,输出如下:
5/2 =
2 =
5//2 = 2
/ =







### Python基础知识笔试
一、单选题(2.5分\*20题)
1. ```
下列哪个表达式在Python中是非法的? B
A. x = y = z = 1
B. x = (y = z + 1)
C. x, y = y, x
D. x += y
2. python my.py v1 v2 命令运行脚本,通过 from sys import argv如何获得v2的参数值? C
A. argv[0]
B. argv[1]
C. argv[2]
D. argv[3]
3. 如何解释下面的执行结果? B
print 1.2 - 1.0 == 0.2
False
A. Python的实现有错误
B. 浮点数无法精确表示
C. 布尔运算不能用于浮点数比较
D. Python将非0数视为False
4. 下列代码执行结果是什么? D
x = 1
def change(a):
x+= 1
print x
change(x)
A. 1
B. 2
C. 3
D. 报错
5. 下列哪种类型是Python的映射类型? D
A. str
B. list
C. tuple
D. dict
6. 下述字符串格式化语法正确的是? D
A. ‘GNU’s Not %d %%’ % ‘UNIX’
B. ‘GNU’s Not %d %%’ % ‘UNIX’
C. ‘GNU’s Not %s %%’ % ‘UNIX’
D. ‘GNU’s Not %s %%’ % ‘UNIX’
7. 在Python 2.7中,下列哪种是Unicode编码的书写方式?C
A. a = ‘中文’
B. a = r‘中文’
C. a = u’中文’
D. a = b’中文’
8. 下列代码的运行结果是? D
print ‘a’ < ‘b’ < ‘c’
A. a
B. b
C. c
D. True
E. False
9. 下列代码运行结果是? C
a = ‘a’
print a > ‘b’ or ‘c’
A. a
B. b
C. c
D. True
E. False
10. 下列哪种不是Python元组的定义方式? A
A. (1)
B. (1, )
C. (1, 2)
D. (1, 2, (3, 4))
11. a与b定义如下,下列哪个是正确的? B
a = ‘123’
b = ‘123’
A. a != b
B. a is b
C. a == 123
D. a + b = 246
12. 下列对协程的理解错误的是? D
A. 一个线程可以运行多个协程
B. 协程的调度由所在程序自身控制
C. Linux中线程的调度由操作系统控制
D. Linux中协程的调度由操作系统控制
13. 下列哪种函式参数定义不合法? C
A. def myfunc(*args):
B. def myfunc(arg1=1):
C. def myfunc(*args, a=1):
D. def myfunc(a=1, args):
14. 下列代码执行结果是? A
[ii for i in xrange(3)]
A. [1, 1, 4]
B. [0, 1, 4]
C. [1, 2, 3]
D. (1, 1, 4)
15. 一个段代码定义如下,下列调用结果正确的是?A
def bar(multiple):
def foo(n):
return multiple ** n
return foo
A. bar(2)(3) == 8
B. bar(2)(3) == 6
C. bar(3)(2) == 8
D. bar(3)(2) == 6
16. 下面代码运行结果? C
a = 1
try:
a += 1
except:
a += 1
else:
a += 1
finally:
a += 1
print a
A. 2
B. 3
C. 4
D. 5
17. 下面代码运行后,a、b、c、d四个变量的值,描述错误的是? D
import copy
a = [1, 2, 3, 4, [‘a’, ‘b’]]
b = a
c = copy.copy(a)
d = copy.deepcopy(a)
a.append(5)
a[4].append(‘c’)
A. a == [1,2, 3, 4, [‘a’, ‘b’, ‘c’], 5]
B. b == [1,2, 3, 4, [‘a’, ‘b’, ‘c’], 5]
C. c == [1,2, 3, 4, [‘a’, ‘b’, ‘c’]]
D. d == [1,2, 3, 4, [‘a’, ‘b’, ‘c’]]
18. 有如下函数定义,执行结果正确的是? A
def dec(f):
n = 3
def wrapper(*args,**kw):
return f(*args,**kw) * n
return wrapper
@dec
def foo(n):
return n * 2
A. foo(2) == 12
B. foo(3) == 12
C. foo(2) == 6
D. foo(3) == 6
19. 有如下类定义,下列描述错误的是? D
class A(object):
pass
class B(A):
pass
b = B()
A. isinstance(b, A) == True
B. isinstance(b, object) == True
C. issubclass(B, A) == True
D. issubclass(b, B) == True
20. 下列代码运行结果是? C
a = map(lambda x: x**3, [1, 2, 3])
list(a)
A. [1, 6, 9]
B. [1, 12, 27]
C. [1, 8, 27]
D. (1, 6, 9)
二、多选题(5分5题)
21. Python中函数是对象,描述正确的是? ABCD
A. 函数可以赋值给一个变量
B. 函数可以作为元素添加到集合对象中
C. 函数可以作为参数值传递给其它函数
D. 函数可以当做函数的返回值
22. 若 a = range(100),以下哪些操作是合法的? ABCD
A. a[-3]
B. a[2:13]
C. a[::3]
D. a[2-3]
23. 若 a = (1, 2, 3),下列哪些操作是合法的? ABD
A. a[1:-1]
B. a3
C. a[2] = 4
D. list(a)
24. Python中单下划线_foo与双下划线__foo与__foo__的成员,下列说法正确的是?ABC
A. _foo 不能直接用于’from module import ’
B. __foo解析器用_classname__foo来代替这个名字,以区别和其他类相同的命名
C. __foo__代表python里特殊方法专用的标识
D. __foo 可以直接用于’from module import ’
25. __new__和__init__的区别,说法正确的是? ABCD
A. new__是一个静态方法,而__init__是一个实例方法
B. new__方法会返回一个创建的实例,而__init__什么都不返回
C. 只有在__new__返回一个cls的实例时,后面的__init__才能被调用
D. 当创建一个新实例时调用__new,初始化一个实例时用__init
三、填空题(5分5题)
26. 在Python 2.7中,执行下列语句后,显示结果是什么? 答:0 0.5
from future importdivision
print 1//2, 1/2
27. 在Python 2.7中,执行下列语句后的显示结果是什么? 答:none 0
a = 1
b = 2 * a / 4
a = “none”
print a,b
28. 下列语句执行结果是什么? 答:[1, 2, 3, 1, 2, 3, 1, 2, 3]
a = [1, 2, 3]
print a3
29. 下列语句的执行结果是什么? 答:3
a = 1
for i in range(5):
if i == 2:
break
a += 1
else:
a += 1
print a
30. 下列代码的运行结果是多少? 答:4
def bar(n):
m = n
while True:
m += 1
yield m
b = bar(3)
print b.next()
附录:Python常见面试题精选
一、 基础知识(7题)
题01:Python中的不可变数据类型和可变数据类型是什么意思?
难度: ★☆☆☆☆【参考答案】
不可变数据类型是指不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象(一个地址)。数值型、字符串string和元组tuple都属于不可变数据类型。
可变数据类型是指允许变量的值发生变化,即如果对变量执行append、+=等操作,只会改变变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化。不过对于相同的值的不同对象,在内存中会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。列表list和字典dict都属于可变数据类型。
题02:请简述Python中is和==的区别。
难度:★★☆☆☆ 【参考答案】
Python中的对象包含三个要素:id、type和value。is比较的是两个对象的id。==比较的是两个对象的value。
题03:请简述function(args, **kwargs)中的 args, kwargs分别是什么意思?
难度:★★☆☆☆ 【参考答案】
*args和kwargs主要用于函数定义的参数。Python语言允许将不定数量的参数传给一个函数,其中args表示一个非键值对的可变参数列表,kwargs则表示不定数量的键值对参数列表。注意:*args和kwargs可以同时在函数的定义中,但是args必须在**kwargs前面。
题04:请简述面向对象中__new__和__init__的区别。
难度: ★★★☆☆【参考答案】
(1)__new__至少要有一个参数cls,代表当前类,此参数在实例化时由Python解释器自动识别。
(2) __new__返回生成的实例,可以返回父类(通过super(当前类名, cls)的方式)__new__出来的实例,
或者直接是对象的__new__出来的实例。这在自己编程实现__new__时要特别注意。
(3) __init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一
些其它初始化的动作,init__不需要返回值。
(4) 如果__new__创建的是当前类的实例,会自动调用__init,通过返回语句里面调用的__new__函
数的第一个参数是cls来保证是当前类实例,如果是其他类的类名,那么实际创建并返回的就是其他类的实例,也就不会调用当前类或其他类的__init__函数。
题05:Python子类继承自多个父类时,如多个父类有同名方法,子类将继承自哪个方法?
难度:★☆☆☆☆
【参考答案】
Python语言中子类继承父类的方法是按照继承的父类的先后顺序确定的,例如,子类A继承自父类B、C,且B、C中具有同名方法Test(),那么A中的Test()方法实际上是继承自B中的Test()方法。
题06:请简述Python中如何避免死锁?
难度:★☆☆☆☆
【参考答案】
死锁是指不同线程获取了不同的锁,但是线程间又希望获取对方的锁,双方都在等待对方释放锁,这种相互等待资源的情况就是死锁。Python语言可以使用threading.Condition对象,基于条件事件通知的形式去协调线程的运行,即可避免死锁。
题07:什么是排序算法的稳定性?常见的排序算法如冒泡排序、快速排序、归并排序、堆排
序、Shell排序、二叉树排序等的时间、空间复杂度和稳定性如何?
难度:★★★☆☆
【参考答案】
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
常见排序算法的时间、空间复杂度和稳定性如下表所示。
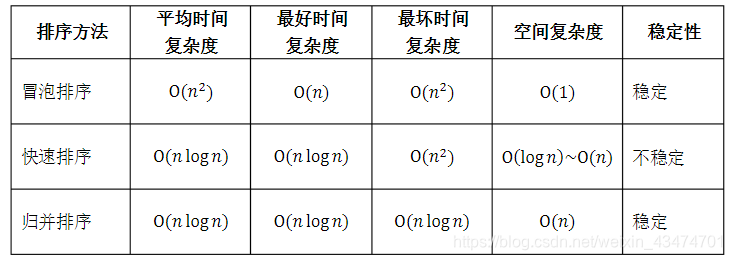
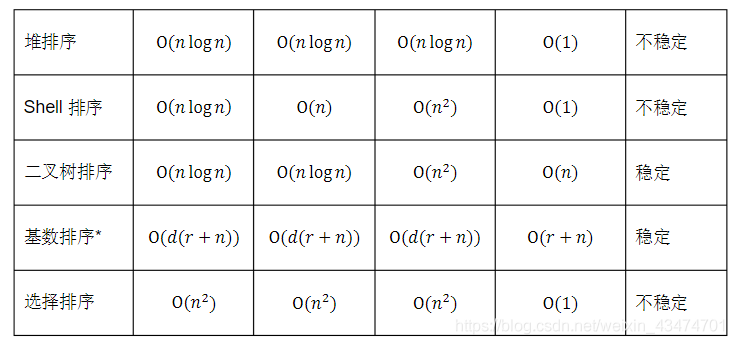
*基数排序的复杂度中,r表示关键字的基数,d表示长度,n表示关键字的个数。
二、 字符串与数字(7题)
题08:字符串内容去重并按字母顺序排列。
难度:★☆☆☆☆
令 s = “hfkfdlsahfgdiuanvzx”,试对 s 去重并按字母顺序排列输出 “adfghiklnsuvxz”。
【参考答案】
s = "hfkfdlsahfgdiuanvzx"
s = list(set(s)) s.sort(reverse=False) print("".join(s))
题09:判断两个字符串是否同构。
难度:★★☆☆☆
字符串同构是指字符串s中的所有字符都可以替换为t中的所有字符。在保留字符顺序的同时,必须用另一个字符替换所有出现的字符。不能将s中的两个字符映射到t中同一个字符,但字符可以映射到自身。试判定给定的字符串s和t是否同构。 例如: s = “add” t = “apple” 输出 False s = “paper” t = “title”
输出
True 【参考答案】
print(len(set(s)) == len(set(t)) == len(set(zip(s, t))))
题10:使用Lambda表达式实现将IPv4的地址转换为int型整数。
难度:★★★☆☆
例如:ip2int(“192.168.3.5”) 输出:
3232236293
【参考答案】
ip2int = lambda x:sum([256\*\*j\*int(i) for j,i in enumerate(x.split('.')[::-1])])
题11:罗马数字使用字母表示特定的数字,试编写函数romanToInt(),输入罗马数字字符
串,输出对应的阿拉伯数字。
难度:★★★☆☆
【参考答案】
罗马数字中字母与阿拉伯数字的对应关系如下:
M:1000,CM:900,D:500,CD:400,C:100,XC:90,L:50,XL: 40,X:10,IX:9,V:5,VI:4,I:1
def romanToInt(s):
table = {'M':1000, 'CM':900, 'D':500, 'CD':400, 'C':100, 'XC':90, 'L':50, 'XL': 40, 'X':10, 'IX':9, 'V':5, 'VI':4, 'I':1} result = 0
for i in range(len(s)):
if i > 0 and table[s[i]] > table[s[i-1]]: result += table[s[i]] result -= 2 \* table[s[i-1]] else:
result += table[s[i]] return result
题12:判断括号是否成对。
难度:★★★☆☆
给定一个只包含字符“(”“)”“{”“}”“[”和“]”的字符串,试编写函数isParenthesesValid(),输入该字符串,确定输入的字符串是否有效。括号必须以正确的顺序关闭,例如“()”和“()[]{}”都是有效的,但“(]”和“([]]”不是。
【参考答案】
def isParenthesesValid(s): pars = [None]
parmap = {')': '(', '}': '{', ']': '['} for c in s:
if c in parmap:
if parmap[c] != pars.pop(): return False else:
pars.append(c) return len(pars) == 1
题13:编写函数输出count-and-say序列的第n项。
难度:★★★★☆
count-and-say序列是一个整数序列,其前五个元素如下: 1 11 21
1211 111221
1读作“1”或11。11读作“两个1”或21。21读作“一个2,然后一个1”或1211。即下一项是将上一项“读出来”再写成数字。
试编写函数CountAndSay(n),输出count-and-say序列的第n项。 【参考答案】
def CountAndSay(n): ans = "1" n -= 1 while n > 0: res = "" pre = ans[0] count = 1
for i in range(1, len(ans)): if pre == ans[i]: count += 1 else:
res += str(count) + pre pre = ans[i] count = 1 res += str(count) + pre ans = res
n -= 1 return ans
题14:不使用sqrt
函数,试编写squareRoot()函数,输入一个正数,输出它的平方根的整
数部分
难度:★★★★☆ 【参考答案】
def squareRoot(x): result = 1.0
while abs(result \* result - x) > 0.1: result = (result + x / result) / 2
return int(result)
三、 正则表达式(4题)
题15:请写出匹配中国大陆手机号且结尾不是4和7的正则表达式。
难度:★☆☆☆☆ 【参考答案】
import re
tels = [“159********”, “14456781234”, “12345678987”, “11444777”] for tel in tels:
print(“Valid”) if (re.match(r"1\d{9}[0-3,5-6,8-9]", tel) != None) else print(“Invalid”)
题16:请写出以下代码的运行结果。
难度:★★☆☆☆
import re
str = '<div class="nam">中国</div>'
res = re.findall(r'<div class=".\*">(.\*?)</div>',str) print(res)
结果如下: 【参考答案】
['中国 ']
题17:请写出以下代码的运行结果。
难度:★★★☆☆
import re
match = re.compile('www\....?').match("www.baidu.com") if match:
print(match.group()) else:
print("NO MATCH")
【参考答案】
www.bai
题18:请写出以下代码的运行结果。
难度:★★☆☆☆
import re
example = "<div>test1</div><div>test2</div>" Result = re.compile("<div>.\*").search(example)
print("Result = %s" % Result.group())
【参考答案】
Result =
test1
test2
四、 列表、字典、元组、数组、矩阵(9题)
题19:使用递推式将矩阵转换为一维向量。
难度:★☆☆☆☆ 使用递推式将 [[ 1, 2 ], [ 3, 4 ], [ 5, 6 ]]
转换为
[1, 2, 3, 4, 5, 6]。 【参考答案】
a = [[1, 2], [3, 4], [5, 6]] print([j for i in a for j in i])
题20:写出以下代码的运行结果。
难度:★★★★☆
def testFun():
temp = [lambda x : i\*x for i in range(5)]
return temp
for everyLambda in testFun(): print (everyLambda(3))
结果如下: 【参考答案】
12 12 12 12 12
题21:编写Python程序,打印星号金字塔。
难度:★★★☆☆
编写尽量短的Python程序,实现打印星号金字塔。例如n=5时输出以下金字塔图形:
*
*** ***** ******* *********
参考代码如下: 【参考答案】
n = 5
for i in range(1,n+1):
print(' '\*(n-(i-1))+'\*'\*(2\*i-1))
题22:获取数组的支配点。
难度:★★★☆☆
支配数是指数组中某个元素出现的次数大于数组元素总数的一半时就成为支配数,其所在下标称为支配点。编写Python
函数FindPivot(li),输入数组,输出其中的支配点和支配数,若数组中不存在支配数,输出None。
例如:[3,3,1,2,2,1,2,2,4,2,2,1,2,3,2,2,2,2,2,4,1,3,3]中共有23个元素,其中元素2出现了12次,其支配点和支配数组合是(18, 2)。 【参考答案】
def FindPivot(li): mid = len(li)/2 for l in li: count = 0 i = 0 mark = 0 while True: if l == li[i]: count += 1 temp = i i += 1
if count > mid: mark = temp
return (mark, li[mark]) if i > len(li) - 1: break
题23:将函数按照执行效率高低排序
难度:★★★☆☆
有如下三个函数,请将它们按照执行效率高低排序。
def S1(L_in):
l1 = sorted(L_in)
l2 = [i for i in l1 if i<0.5] return [i\*i for i in l2]
def S2(L_in):
l1 = [i for i in L_in if i<0.5] l2 = sorted(l1)
return [i\*i for i in l2]
def S3(L_in):
l1 = [i\*i for i in L_in] l2 = sorted(l1)
return [i for i in l2 if i<(0.5\*0.5)]
【参考答案】
使用cProfile库即可测试三个函数的执行效率:
import random import cProfile
L_in = [random.random() for i in range(1000000)]
cProfile.run('S1(L\_in)') cProfile.run('S2(L\_in)') cProfile.run('S3(L\_in)')
从结果可知,执行效率从高到低依次是S2、S1、S3。
题24:螺旋式返回矩阵的元素
难度:★★★★★
给定m×n个元素的矩阵(m行,n列),编写Python
函数spiralOrder(matrix),以螺旋顺序返回矩阵的所有元素。
例如,给定以下矩阵: [[ 1, 2, 3 ], [ 4, 5, 6 ], [ 7, 8, 9 ]]
应该返回[1,2,3,6,9,8,7,4,5]
【参考答案】
def spiralOrder(matrix):
if len(matrix) == 0 or len(matrix[0]) == 0: return [] ans = []
left, up, down, right = 0, 0, len(matrix) - 1, len(matrix[0]) - 1 while left <= right and up <= down: for i in range(left, right + 1): ans += matrix[up][i], up += 1
for i in range(up, down + 1): ans += matrix[i][right], right -= 1
for i in reversed(range(left, right + 1)): ans += matrix[down][i], down -= 1
for i in reversed(range(up, down + 1)): ans += matrix[i][left], left += 1
return ans[:(len(matrix) \* len(matrix[0]))]
题25:矩阵重整
难度:★★★★☆
对于一个给定的二维数组表示的矩阵,以及两个正整数r和c,分别表示所需重新整形矩阵的行数和列数。reshape函数生成一个新的矩阵,并且将原矩阵的所有元素以与原矩阵相同的行遍历顺序填充进去,将该矩阵重新整形为一个不同大小的矩阵但保留其原始数据。对于给定矩阵和参数的reshape操作是可以完成且合法的,则输出新的矩阵;否则,输出原始矩阵。请使用Python语言实现reshape函数。 例如:
输入
r, c 输出
说明
nums = [[1,2], [3,4]] r = 1,c =
4 [[1,2,3,4]]
行遍历的是[1,2,3,4]。新的重新形状矩阵是1 * 4矩阵,使用前面的列表逐行填充。
nums = [[1,2], [3,4]]
r = 2,c =
4
[[1,2], [3,4]]
无法将2 * 2矩阵重新整形为2 * 4矩阵。所以输出原始矩阵。
注意:给定矩阵的高度和宽度在[1,100]范围内。给定的r和c都是正数。
【参考答案】
def matrixReshape(nums, r, c): """
if r \* c != len(nums) \* len(nums[0]): return nums m = len(nums) n = len(nums[0])
ans = [[0] \* c for _ in range(r)] for i in range(r \* c):
ans[i / c][i % c] = nums[i / n][i % n] return ans
题26:查找矩阵中第k个最小元素。
难度:★★★★☆
给定n×n矩阵,其中每行每列元素均按升序排列,试编写Python函数kthSmallest(matrix, k),找到矩阵中的第k个最小元素。
注意:查找的是排序顺序中的第k个最小元素,而不是第k个不同元素。 例如: 矩阵= [[1,5,9], [10,11,13], [12,13,15]] k = 8,应返回13。
【参考答案】
import heapq
def kthSmallest(matrix, k): visited = {(0, 0)}
heap = [(matrix[0][0], (0, 0))]
while heap:
val, (i, j) = heapq.heappop(heap) k -= 1 if k == 0: return val
if i + 1 < len(matrix) and (i + 1, j) not in visited:
heapq.heappush(heap, (matrix[i + 1][j], (i + 1, j))) visited.add((i + 1, j))
if j + 1 < len(matrix) and (i, j + 1) not in visited: heapq.heappush(heap, (matrix[i][j + 1], (i, j + 1))) visited.add((i, j + 1))
题27:试编写函数largestRectangleArea(),求一幅柱状图中包含的最大矩形的面积。
难度:★★★★★ 例如对于下图:
输入:[2,1,5,6,2,3] 输出:10
【参考答案】
def largestRectangleArea(heights): stack=[] i=0 area=0
while i<len(heights):
if stack==[] or heights[i]>heights[stack[len(stack)-1]]: # 递增直接入栈
stack.append(i) else: # 不递增开始弹栈
curr=stack.pop() if stack == []: width = i else:
width = i-stack[len(stack)-1]-1 area=max(area,width\*heights[curr]) i-=1 i+=1
while stack != []: curr = stack.pop() if stack == []: width = i else:
width = len(heights)-stack[len(stack)-1]-1 area = max(area,width\*heights[curr]) return area
五、 设计模式(3
题)
题28:使用Python语言实现单例模式。
难度:★★★☆☆
【参考答案】
class Singleton(object):
def \_\_new\_\_(cls, \*args, \*\*kw): if not hasattr(cls, '\_instance'): orig = super(Singleton, cls)
cls._instance = orig.\_\_new\_\_(cls, \*args, \*\*kw) return cls._instance
题29:使用Python语言实现工厂模式。
难度:★★★★☆
编写适当的Python程序,完成以下功能: 1. 定义基类Person,含有获取名字,性别的方法。 2. 定义Person类的两个子类Male和Female,含有打招呼的方法。 3. 定义工厂类,含有getPerson方法,接受两个输入参数:名字和性别。 4. 用户通过调用getPerson方法使用工厂类。
【参考答案】
class Person:
def \_\_init\_\_(self): self.name = None self.gender = None
def getName(self): return self.name
def getGender(self): return self.gender
class Male(Person):
def \_\_init\_\_(self, name): print("Hello Mr." + name)
class Female(Person):
def \_\_init\_\_(self, name): print("Hello Miss." + name)
class Factory:
def getPerson(self, name, gender): if(gender == 'M'): return Male(name) if(gender == 'F'): return Female(name)
if __name__ == '\_\_main\_\_': factory = Factory()
person = factory.getPerson("Huang", "M")
题30:使用Python语言实现观察者模式。
总结
大厂面试问深度,小厂面试问广度,如果有同学想进大厂深造一定要有一个方向精通的惊艳到面试官,还要平时遇到问题后思考一下问题的本质,找方法解决是一个方面,看到问题本质是另一个方面。还有大家一定要有目标,我在很久之前就想着以后一定要去大厂,然后默默努力,每天看一些大佬们的文章,总是觉得只有再学深入一点才有机会,所以才有恒心一直学下去。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】















 1610
1610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









