






网络请求库概述
作为一名爬虫初学者,熟练使用各种网络请求库是一项必备的技能。利用这些网络请求库,我们可以通过非常简单的操作来进行各种协议的模拟请求。我们不需要深入底层去关注如何建立通信与数据如何传输,只需要调用各种网络请求库封装好的方法。Python提供了很多功能强大的网络请求库,如urllib、requests、httpx、aiohttp、websocket等,下文中会对这些库做一一介绍。

urllib
安装与介绍
安装
urllib是Python的内置请求库,不需要再额外安装。
介绍
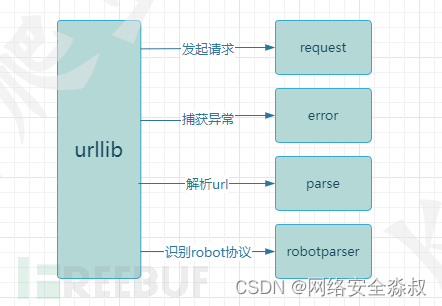
urllib库包含四个模块:
urllib.request:向目标url发起请求并读取响应信息。
urllib.error:负责异常处理,捕获urllib.request抛出的异常。
urllib.parse:解析url,提供了一些url的解析方法。
urllib.robotparser:解析网站robots.txt文件,判断网站是否允许爬虫程序进行采集。
使用方法
请求与响应
使用到了urllib.request模块中的urlopen方法来打开一个url并获取响应信息。urlopen默认返回的是一个HTTPResponse对象,可以通过read方法得到它的明文信息。
import urllib.request
response = urllib.request.urlopen('http://httpbin.org/get')
print(response) #打印:<http.client.HTTPResponse object at 0x0000013D85AE6548>
print(response.read().decode('utf-8')) #响应信息
print(response.status) #返回状态码
print(response.getheaders()) #返回响应头信息
设置请求头与参数
当请求需要设置请求头时,就需要用到urllib.request模块中的另一个方法Request,它允许传递如下几个参数:
def __init__(self, url, data=None, headers={},origin_req_host=None, unverifiable=False,method=None)
url:目标url
data:请求参数,默认为None
headers:请求头信息,字典类型
origin_req_host:请求的主机地址
unverifiable:设置网页是否需要验证
method:请求方式
from urllib import request,parse
url = 'https://httpbin.org/post' #目标URL
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
} #请求头信息
params = {
'test':'test01' #请求参数
}
data = bytes(parse.urlencode(params),encoding='utf-8') #解析为bytes类型
res = request.Request(url,data=data,headers=headers,method='POST') #实例化Request
response = request.urlopen(res) #发起请求
print(response.read().decode('utf-8')) #响应信息
异常捕获
在发起请求时,可能会因为网络、url错误、参数错误等问题导致请求异常,程序报错。为了应对这种情况,我们需要添加异常处理功能。
from urllib import request,error
try:
response = request.urlopen('http://httpbin.org/get')
except error.HTTPError as e: #捕获异常
print(e) #打印异常信息
requests
requests是Python爬虫开发中最常使用到的库,它提供了简单易用的API,使得在Python中发送HTTP请求变得非常容易,它比urllib模块更加简洁,使用更加方便。
安装与介绍
安装
requests是Python的第三方库,使用 pip install requests进行安装
介绍
requests包含了许多模块,这里只介绍主要模块:
requests:主模块,提供了HTTP请求方法。
requests.session:会话模块,提供了Session类,用于多个请求中共享请求信息。
requests.adapters:适配器模块,提供了不同协议的适配器类,用于处理不同协议的请求。
requests.cookie:Cookie模块,用于处理cookie信息。
requests.exceptions:异常处理模块,用于处理请求中会出现的各种异常。
requests.status_codes:状态码模块,提供了HTTP状态码常量和状态码解释。
使用方法
请求与响应
import requests #导入requests模块
get_response = requests.get('http://httpbin.org/get') #发送get请求
post_response = requests.post('http://httpbin.org/post') #发送post请求
print(get_response) #<Response [200]>
print(post_response) #<Response [200]>
requests库发送请求非常简单,并支持多种请求方式,如:get、post、put、delete等。发起请求后requests会返回一个Response对象,可以使用多种方法来解析Response对象。
import requests
response = requests.get('http://httpbin.org/get')
print(response.status_code) #返回响应状态码
print(response.encoding) #返回响应信息的编码
print(response.text) #返回响应的文本信息
print(response.content) #返回响应的字节信息
print(response.json()) #将JSON响应信息解析为字典,如果响应数据类型不为JSON则会报错
print(response.headers) #返回响应头信息
print(response.cookies) #返回响应cookie
设置请求头与参数
request(self,method,url,params=None,data=None,headers=None,cookies=None,files=None,auth=None,timeout=None,allow_redirects=True,proxies=None,hooks=None,stream=None,verify=None,cert=None,json=None)
requests中设置请求头可以通过headers参数来设置,headers是一个字典类型,键为请求头的字段名,值为对应请求头的值。
请求参数可以通过params方法进行设置,类型为字典。键为参数名,值为对应参数的值。
在网络请求中,携带的参数可以分为两个类型,它们在python中对应的字段名如下:
查询字符串参数:params
请求载荷:data/json
查询字符串参数params是拼接在url中的参数,常用于get请求,作为查询参数使用。而data与json一般使用与post请求中,它是要发送到服务器的实际数据。
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
params = {'key':'value'}
data = {'username':'user','passowrd':'password'}
get_response = requests.get(url,params=params,headers=headers)
post_response = requests.post(url,data=data,headers=headers)
Session的使用
当一个网站我们需要多次请求时,如我需要登录 -> 请求个人页面,在面对这种场景时,我们可以使用到Session方法。因为通过requests发送到的请求是独立,我们请求登录接口与请求个人页面之间是没有联系的,我们需要请求登录接口后获取它返回的cookie,然后设置cookie进行下一次请求。每次请求后都需要设置一次cookie,如果请求流程更多的话那么过程就会显得很繁琐。使用Session方法就能更好的模拟一次请求流程,不需要频繁的设置cookie。
Session的作用类似于浏览器中的cookie与缓存,它可以用于在多次请求中维护一些状态信息,避免重复发送相同的信息和数据,使用Session可以优化HTTP请求的性能与可维护性,它的使用也非常简单。
import requests
session = requests.Session() #创建session对象
session.get('http://httpbin.org/cookies/set/username/test') #发起请求,模拟一次登录
response = session.get('http://httpbin.org/cookies') #获取cookie
print(response.text) #{"cookies": {"username": "test"}}
异常捕获
requests.exceptions 中提供了一系列请求异常。
ConnectTimeout:连接超时
ReadTimeout:服务器在指定时间内没有应答
ConnectionError:未知的服务器
ProxyError:代理异常
URLRequired:无效URL
TooManyRedirects:重定向过多
MissingSchema:URL缺失,如缺少:http/https
InvalidSchema:提供的URL方案无效或不受支持
InvalidURL:提供的URL不知何故无效
InvalidHeader:提供的请求头无效
InvalidProxyURL:提供的代理URL无效
ChunkedEncodingError:服务器声明了编码分块,但发送了无效分块
ContentDecodingError:无法对响应信息解码
StreamConsumedError:此响应内容已被使用
RetryError:自定义重试逻辑错误
UnrewindableBodyError:请求在尝试倒带正文时遇到错误
HTTPError:出现HTTP错误
SSLError:发生SSL错误
Timeout:请求超时
httpx
前面讲到了requests库,它功能强大、使用简单,并且提供session会话模块,似乎requests库已经可以满足所有的应用场景了。但是requests也有一些致命的缺点:
-
同步请求,不支持异步,requests默认使用同步请求,在网络请求中同步请求到导致性能问题。
-
不支持HTTP2.0,如今已经有少部分网站采用HTTP2.0协议来进行数据传输,面对这类网站无法使用requests。
而httpx是一个基于异步IO的Python3的全功能HTTP客户端库,旨在提供一个快速、简单、现代化的HTTP客户端,它提供同步与异步API,而且支持HTTP1.1和HTTP2.0。并且httpx功能也很齐全,requests支持的功能httpx也基本同样支持。因此,在爬虫开发中使用httpx也是一个非常不错的选择。
安装与介绍
安装
httpx是Python的第三方库,使用 pip install httpx进行安装
如果需要httpx支持https2.0,则需要安装它的可选依赖项, pip install httpx[http2]
介绍
httpx是建立在requests的成熟可用性之上的,提供的模块与requests大同小异,因此不做介绍。
使用方法
httpx用法与requests基本一致,这里主要介绍httpx的Client实例。
httpx Client
Client作用与requests的session方法一致,但用法有些区别。
常见用法是使用上下文管理器,这样可以确保在请求完成后能够正确清理连接。
import httpx
with httpx.Client() as client:
response = client.get('https://httpbin.org/get')
print(response) #<Response [200 OK]>
在设置请求头、传递参数时也有新的写法。
import httpx
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'}
params = {'key':'value'}
with httpx.Client(headers=headers,params=params) as client:
response = client.get('https://httpbin.org/get')
print(response)
aiohttp
aiohttp是基于Python异步IO的HTTP客户端/服务器库,它与httpx相似,同样支持HTTP1.1和HTTP2.0协议,aiohttp是基于asyncio实现的,它支持WebSocket协议。
安装
aiohttp是Python的第三方库,使用 pip install aiohttp进行安装
使用
import aiohttp
import asyncio
async def main():
async with aiohttp.ClientSession() as session:
async with session.get('https://httpbin.org/get') as response:
print(response) #<ClientResponse(https://httpbin.org/get) [200 OK]>
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
aiohttp不支持同步,需要与asyncio一起使用,与前文中讲到的库对比,aiohttp显得异常复杂,requests两行代码就能完成的功能aiohttp却需要5行。为什么aiohttp代码如此冗余我们却要使用它呢?因为aiohttp是异步的,它的api旨在充分利用非阻塞网络操作,在实例代码中,请求将阻塞三次,这为事件循环提供了三次切换上下文的机会。aiohttp可以实现单线程并发IO操作,它在处理大量网站请求时的速度远超于requests,但在涉及到文件读写操作时,它发挥的作用就没有预期的那么大,因此aiohttp库的使用需要爬虫开发者自行斟酌。
websocket
Python websocket库是专门用于创建WebSocket服务的库。WebSocket是一种在客户端与服务端之间进行双向通信的协议,服务端可以向客户端推送数据,客户端也可以向服务端推送数据,这样就能实现数据的及时通信,它与HTTP协议一样,由socket实现。WebSocket通常使用在直播、弹幕等场景中。
安装
websocket是Python的内置库,不需要手动安装。当你在运行下文中的实例时,如果报错cannot import name 'WebSocketApp' from 'websocket',你可以卸载现有的websocket库,安装websocket-client==0.53.0版本的包。
使用
websocket用于客户端与服务端通信,爬虫开发中一般只会进行客户端的开发,所有这里只介绍客户端的开发。
使用WebSocketApp可以快速的建立一个Websocket连接。
from websocket import WebSocketApp
def on_message(ws, message): #接收到消息时执行
print(message)
def on_error(ws, error): #异常时执行
print(error)
def on_close(ws): #关闭连接时执行
print("WebSocket closed")
def on_open(ws): #开启连接时执行
ws.send("Hello, WebSocket!") #发送信息
if __name__ == "__main__":
ws = WebSocketApp("ws://echo.websocket.org/",
on_message=on_message,
on_error=on_error,
on_close=on_close)
ws.on_open = on_open
ws.run_forever()
可以看到websocket提供了四个模块:
on_message:接收服务器推送来的数据
on_error:连接异常时会触发on_error
on_close:连接关闭时触发on_close
on_open:连接开启时触发on_open
归纳
上文中讲到了urllib、requests、httpx、aiohttp、websocket这五个库的使用,这五个库基本能够满足爬虫开发中的请求需求。urllib是python的内置库,使用起来较为繁琐,可以只做了解。requests是爬虫开发中最常使用的库,功能齐全,使用简单,需要认真学习。httpx在requests的基础上支持异步处理、HTTP2.0与Websocket协议,requests的功能httpx都支持,但在性能方面httpx弱于其他请求库,httpx也需要爬虫初学者好好学习。aiohttp用于编写异步爬虫,开发效率低于其它库,但是执行效率远高与其它库,也是一个需要好好掌握的请求库。websocket是专门用于Websocket协议的库,使用也较为简单,可以在需要时再做了解。
题外话
初入计算机行业的人或者大学计算机相关专业毕业生,很多因缺少实战经验,就业处处碰壁。下面我们来看两组数据:
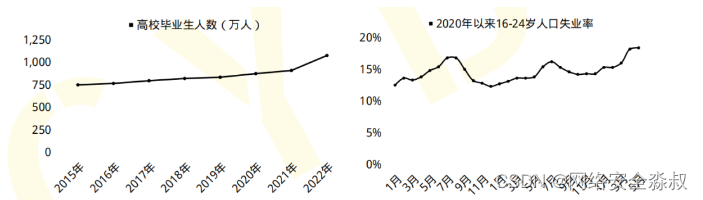
- 2023届全国高校毕业生预计达到1158万人,就业形势严峻;
- 国家网络安全宣传周公布的数据显示,到2027年我国网络安全人员缺口将达327万。
一方面是每年应届毕业生就业形势严峻,一方面是网络安全人才百万缺口。
6月9日,麦可思研究2023年版就业蓝皮书(包括《2023年中国本科生就业报告》《2023年中国高职生就业报告》)正式发布。
2022届大学毕业生月收入较高的前10个专业
本科计算机类、高职自动化类专业月收入较高。2022届本科计算机类、高职自动化类专业月收入分别为6863元、5339元。其中,本科计算机类专业起薪与2021届基本持平,高职自动化类月收入增长明显,2022届反超铁道运输类专业(5295元)排在第一位。
具体看专业,2022届本科月收入较高的专业是信息安全(7579元)。对比2018届,电子科学与技术、自动化等与人工智能相关的本科专业表现不俗,较五年前起薪涨幅均达到了19%。数据科学与大数据技术虽是近年新增专业但表现亮眼,已跻身2022届本科毕业生毕业半年后月收入较高专业前三。五年前唯一进入本科高薪榜前10的人文社科类专业——法语已退出前10之列。

“没有网络安全就没有国家安全”。当前,网络安全已被提升到国家战略的高度,成为影响国家安全、社会稳定至关重要的因素之一。
网络安全行业特点
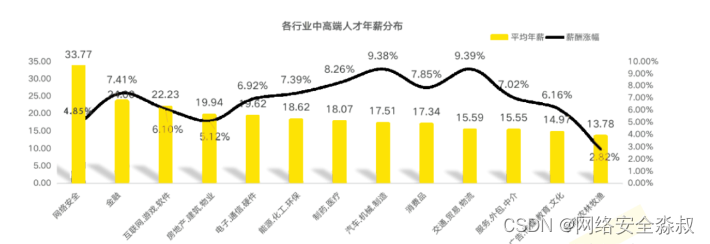
1、就业薪资非常高,涨薪快 2021年猎聘网发布网络安全行业就业薪资行业最高人均33.77万!
2、人才缺口大,就业机会多
2019年9月18日《中华人民共和国中央人民政府》官方网站发表:我国网络空间安全人才 需求140万人,而全国各大学校每年培养的人员不到1.5W人。猎聘网《2021年上半年网络安全报告》预测2027年网安人才需求300W,现在从事网络安全行业的从业人员只有10W人。
行业发展空间大,岗位非常多
网络安全行业产业以来,随即新增加了几十个网络安全行业岗位︰网络安全专家、网络安全分析师、安全咨询师、网络安全工程师、安全架构师、安全运维工程师、渗透工程师、信息安全管理员、数据安全工程师、网络安全运营工程师、网络安全应急响应工程师、数据鉴定师、网络安全产品经理、网络安全服务工程师、网络安全培训师、网络安全审计员、威胁情报分析工程师、灾难恢复专业人员、实战攻防专业人员…
职业增值潜力大
网络安全专业具有很强的技术特性,尤其是掌握工作中的核心网络架构、安全技术,在职业发展上具有不可替代的竞争优势。
随着个人能力的不断提升,所从事工作的职业价值也会随着自身经验的丰富以及项目运作的成熟,升值空间一路看涨,这也是为什么受大家欢迎的主要原因。
从某种程度来讲,在网络安全领域,跟医生职业一样,越老越吃香,因为技术愈加成熟,自然工作会受到重视,升职加薪则是水到渠成之事。
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图 
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。

2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要保存下方图片,微信扫码即可前往获取

3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要保存下方图片,微信扫码即可前往获取

4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
因篇幅有限,仅展示部分资料,需要保存下方图片,微信扫码即可前往获取

最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要保存下方图片,微信扫码即可前往获取
















 1714
1714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









