高考结束,赶紧学一学怎么选择心仪的大学
背景
- 高考结束,广大考生即将参加志愿填报
- 市面上的志愿推荐软件和程序没办法聚合院校数据,需要单独点击推荐高校查看高校信息,难以做数据分析
方法
- 爬取gaokao.cn各高校个专业大类近五年录取分数以及位次信息
['编码', '年份','学校', '省', '市', '性质', '是否985', '是否211', '是否双一流', 'level',
'录取批次', '生源地', '学科属性', '学科分类层级1', '学科分类层级2', '专业', '最低分', '最低位次',]
- 将爬取数据保存到Excel
- 使用Excel的筛选功能选取符合自己预设条件的院校
编码思路
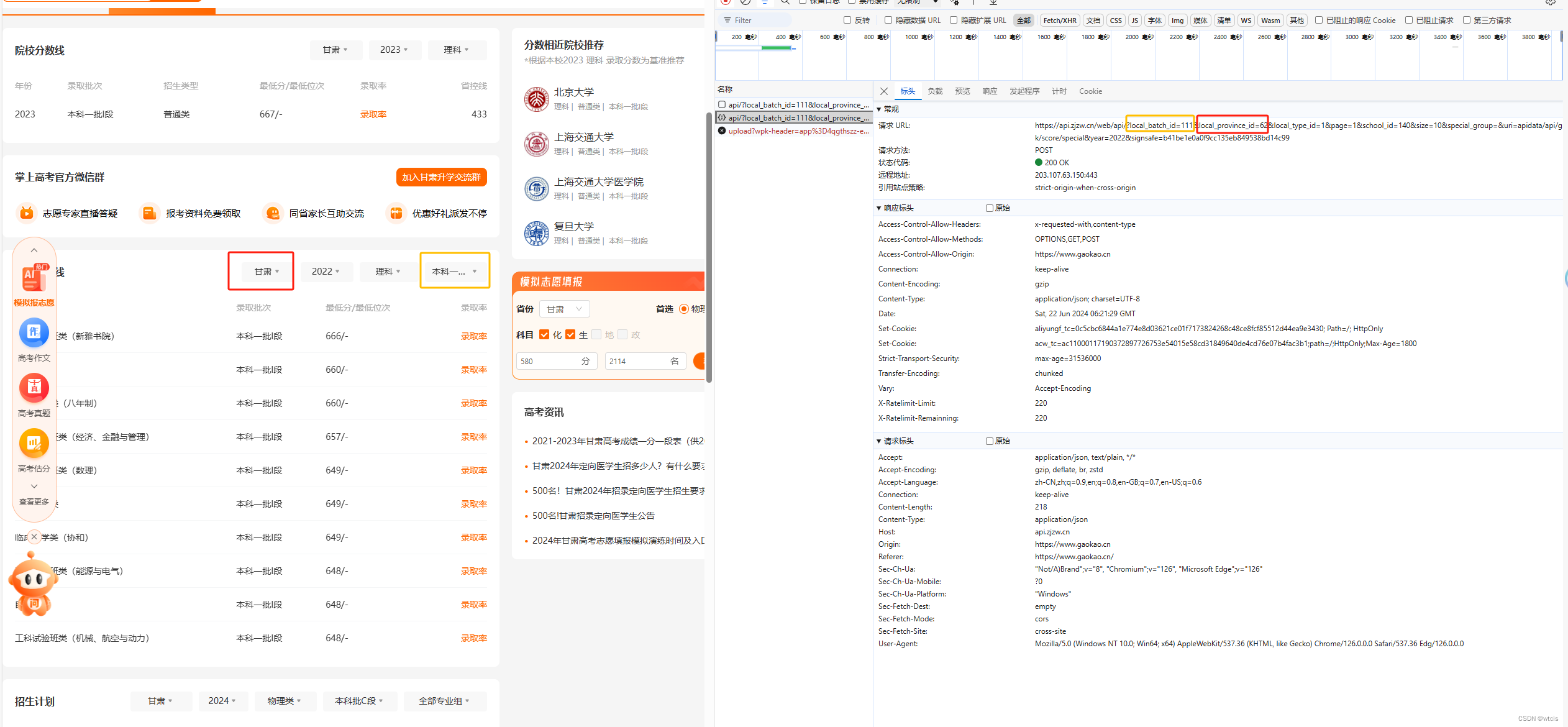
- 捞取获取高校数据的API接口
https://static-data.gaokao.cn/www/2.0/school/list_v2.json
https://api.zjzw.cn/web/api/?local_batch_id=7&local_province_id=51&local_type_id=1&page=1&school_id=143&size=10&special_group=&uri=apidata/api/gk/score/special&year=2022&signsafe=c447cb2e8d1e32b600425e751a88f36d
- 使用IP代理绕过反爬机制
- Excel追加写入
捞取接口及参数的方式
import openpyxl
import requests
import os
API = 'https://api.wandouapp.com/?app_key=fdd6d6a749bb3f210fcf20dbc7b005b1&num=10&xy=1&type=2&lb=\r\n&nr=99&area_id=0&isp=0&'
proxies_data = []
def get_proxy_list(api_url):
proxies_response = requests.get(api_url)
proxies_json = proxies_response.json()
global proxies_data
proxies_data = proxies_json['data']
def get_response(url):
session = requests.session()
session.verify = False
session.headers = {'User-Agent': 'Mozilla/5.0'}
flag = 0;
for proxy_info in proxies_data:
ip = proxy_info['ip']
port = proxy_info['port']
try:
session.proxies = {
'http': f'http://{ip}:{port}',
'https': f'http://{ip}:{port}',
}
res = session.get(url=url,timeout=3)
res_json = res.json()
if res_json['code'] == "0000":
flag = 1
return res
except Exception as e:
print(f'{ip}:{port}: {str(e)}')
if flag == 0:
get_proxy_list(API)
url = "https://static-data.gaokao.cn/www/2.0/school/list_v2.json"
response = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'})
if response.status_code == 200:
data = response.json()
data = data.get('data')
file_path = "table_data_1.xlsx"
failed_requests_file = "failed_requests.txt"
header_data = ['编码', '年份','学校', '省', '市', '性质', '是否985', '是否211', '是否双一流', 'level',
'录取批次', '生源地', '学科属性', '学科分类层级1', '学科分类层级2', '专业', '最低分', '最低位次',
'智能问答地址']
existing_codes = set()
if os.path.exists(file_path):
workbook = openpyxl.load_workbook(file_path)
sheet = workbook.active
for row in sheet.iter_rows(min_row=2, values_only=True):
existing_codes.add(row[0])
workbook.close()
for i in data:
level_value = data.get(i, {}).get('level')
if isinstance(level_value, str) and "专科" in level_value:
print("跳过专科")
continue
if int(i) < 29:
continue
if i in existing_codes:
print(f"编码 {i} 已存在,跳过...")
continue
print(i)
try:
if os.path.exists(file_path):
workbook = openpyxl.load_workbook(file_path)
sheet = workbook.active
row_num = sheet.max_row + 1
else:
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = "Table Data"
for col_num, header in enumerate(header_data, 1):
sheet.cell(row=1, column=col_num, value=header)
row_num = 2
request_failed = False
for year in [2023, 2022, 2021, 2020, 2019]:
for batch in [111, 113]:
for index in (1, 2, 3, 4, 5):
print (year, batch,index,i)
url1 = ('https://api.zjzw.cn/web/api/?local_batch_id=' + str(batch) + '&local_province_id=62&local_type_id=2&page=' + str(index)
+ '&school_id=' + str(i) + '&size=10&special_group=&uri=apidata/api/gk/score/special&year=' + str(year) + '&signsafe=f4b8135f5eb1d58211edeb5a15368361')
res = get_response(url1)
res.raise_for_status()
res_data = res.json()
if 'data' in res_data and isinstance(res_data['data']['item'], list) and len(res_data['data']['item']) > 0:
read_data = res_data['data']['item']
for read_data_item in read_data:
row_data = []
row_data.append(i)
row_data.append(str(year))
row_data.append(data.get(i).get('name'))
row_data.append(data.get(i).get('p'))
row_data.append(data.get(i).get('c'))
row_data.append(data.get(i).get('nature'))
f985 = "是" if data[i].get('f985') == "1" else "否" if data[i].get(
'f985') == "2" else None
row_data.append(f985)
f211 = "是" if data[i].get('f211') == "1" else "否" if data[i].get(
'f211') == "2" else None
row_data.append(f211)
dual_class = "是" if data[i].get('dual_class') == "1" else "否" if data[i].get(
'dual_class') == "2" else None
row_data.append(dual_class)
row_data.append(data.get(i).get('level'))
row_data.append(read_data_item['local_batch_name'])
row_data.append(read_data_item['local_province_name'])
row_data.append(read_data_item['local_type_name'])
row_data.append(read_data_item['level2_name'])
row_data.append(read_data_item['level3_name'])
row_data.append(read_data_item['spname'])
row_data.append(read_data_item['min'])
row_data.append(read_data_item['min_section'])
row_data.append(data.get(i).get('answerurl'))
print(row_data)
for col_num, cell_data in enumerate(row_data, 1):
sheet.cell(row=row_num, column=col_num, value=cell_data)
row_num += 1
print(f"已写入第{row_num - 1}行")
else:
break
except Exception as e:
print(f"请求失败:{e}")
with open(failed_requests_file, "a") as f:
f.write(f"{i}\n")
continue
finally:
workbook.save(file_path)
workbook.close()
print("表格数据已成功写入Excel文件")
else:
print(f"请求失败,状态码:{response.status_code}")

























 1246
1246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









