








对文章首页发送网络请求
通过正则的方式提取出所有的数据下载地址
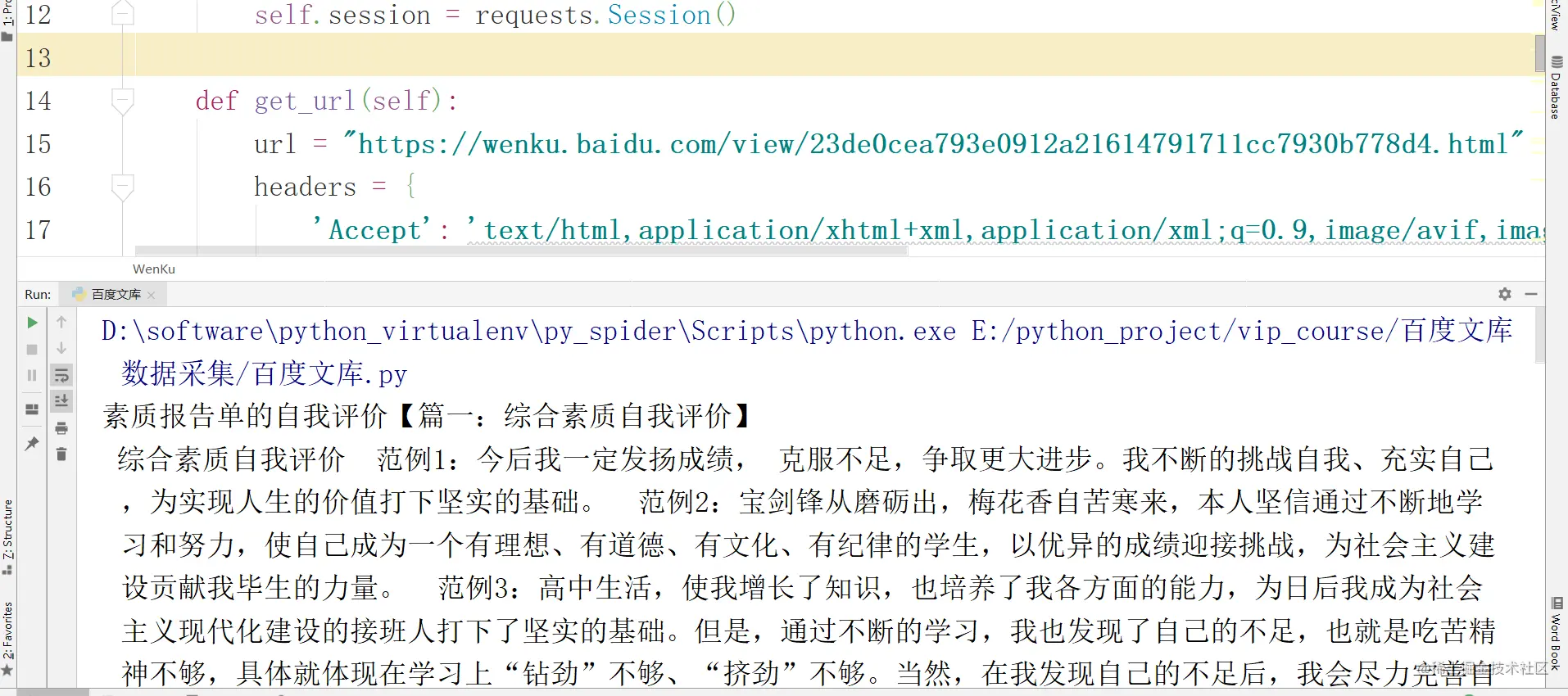
def get_url(self):
url = "https://wenku.baidu.com/view/d19a6bf4876fb84ae45c3b3567ec102de3bddf82.html"
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'wenku.baidu.com',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
response = self.session.get(url=url,headers=headers)
json_data = re.findall('"json":(.*?}])', response.text)[0]
json_data = json.loads(json_data)
# print(json_data)
for index, page_load_urls in enumerate(json_data):
# print(page_load_urls)
page_load_url = page_load_urls['pageLoadUrl']
# print(index)
self.get_data(index, page_load_url)
复制代码
需要取出对应数据的下标,以及所有的文章数据来源地址
再次对文章片段数据发送请求
获取到对应json数据
通过正则的方式先将wenku_1里的json数据全部取出来
在取出body下面所以的列表
在取出所以的C键对应的值
格式可自行调整,最后将数据进行保存
另外怕大家不会使用,直接给大家准备了写好的,直接下载打开即可使用!
源码放在百度云盘上了需要可以微信扫描下方CSDN官方认证二维码免费领取
👉[[CSDN大礼包:《python安装包&全套学习资料》免费分享]](安全链接,放心点击)

Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
入门学习视频
Python实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
最后,千万别辜负自己当时开始的一腔热血,一起变强大变优秀。

感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1958
1958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









