










前言
我们下载资料经常会用到百度文库,但百度文档大部分资料下载是要收费的,总是会遇到想要的资料开会员才能下载,但是为了下一篇资料,开一个会员总会觉得太浪费了,毕竟现在各大会员也有要涨价的趋势了。
【----帮助Python学习,以下所有学习资料文末免费领!----】

你说可以不下载只进行复制复制,但是百度文库就连超出复制字数也要收费,或者是干脆不能复制。

如何解决这个问题,现在我们就来学学如何利用Python免费下载文档。

由于百度文库的内容是通过网页展示的,那我们猜他是通过后台加载进来的。可以先通过Ctrl+u查看HTML源码,看源码里面是否有文档数据。很遗憾HTML源码里面并没有文档内容。
确定不是通过HTML加载的之后,我们就可以大胆地猜测他是通过json异步加载。所以通过F12打开开发者管理工具network抓包,查看页面加载过程请求的URL。这里会有大量的请求,但是我们仔细观察会发现有一个0.json的URL返回的数据就是文档的文本数据。

拿到请求文档数据的URL后需要确定URL参数。通过查看headers确定请求方式为GET请求。请求参数里x-bce-range和token是变动的,其他都是固定不变。
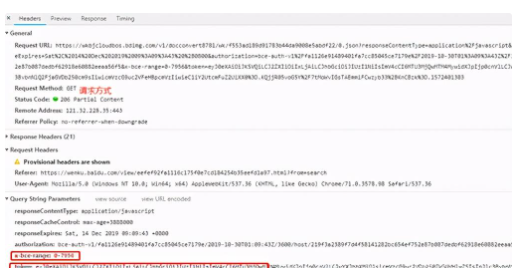
token这个东西很多时候都会写入到HTML页面里去,用途是防csrf攻击。但是百度文档里面的token有什么用我们不用关心,重要的是这个token那里来。去HTML源代码里查看这两个变量能不能获取到。

果然,在HTML源码里有一段js代码,其中就包含了所有请求文档的URL。看起来有点像,但还是不一样啊!其实这里是包含了转移符 \ ,还有一个比较奇怪的 \x22 其实是一个双引号。把这段不规范的json数据提取出来替换掉 \ 和 \x22就是一个标准的json格式数据。
提取文档数据URL代码实现

拿到URL之后继续发送请求获取文档数据,文档数据是分段保存到json里面的,json里面的数据如下图所示。

字段解释:
c: 数据
p: 位置
r: 暂时不确定作用
s: 字体样式
t: 数据格式(word文本,pic图片)
ps: 样式,_enter:1 表示换行,同一段的文本ps值为空
123456
由于图片加载比较特殊,有时候可能通过一个请求加载两张图片,不好确定图片的位置,所以这里暂且不考虑图片,我们只抓取文本。
到这里就已经可以把一个百度文档的文本内容完整下载下来。
网上随机选一篇文档来测试效果,纯文本的文档效果贼好。缺点就是不能同时下载图片插入到word里面去。
-END-
读者福利:如果大家对Python感兴趣,这套python学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、Python量化交易等习教程。带你从零基础系统性的学好Python!
零基础Python学习资源介绍
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 600多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,含50个超大型项目详解,学习不再是只会理论
④ 20款主流手游迫解 爬虫手游逆行迫解教程包
⑤ 爬虫与反爬虫攻防教程包,含15个大型网站迫解
⑥ 爬虫APP逆向实战教程包,含45项绝密技术详解
⑦ 超300本Python电子好书,从入门到高阶应有尽有
⑧ 华为出品独家Python漫画教程,手机也能学习
⑨ 历年互联网企业Python面试真题,复习时非常方便

👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)

👉Python必备开发工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉100道Python练习题👈
检查学习结果。
👉面试刷题👈


资料领取
这份完整版的Python全套学习资料已经上传网盘,朋友们如果需要可以点击下方微信卡片免费领取 ↓↓↓【保证100%免费】
或者
【点此链接】领取















 2160
2160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









