







- 条件判断(if等):用来解决爬虫过程中哪些要哪些不要的问题
- 循环和迭代(for while):用来循环、重复爬虫动作
- 文件读写操作:用来读取参数、保存趴下来的内容等
其次Python爬虫主要用到的库就是request库,这个库是必须要学习的,获取到的数据还需要你自行处理,通过数据筛选规则,正则表达式等等技术进行筛选。
**还有就是知道如何应付反爬;**现在很多网站都开发了属于自己的反爬机制,所以一些常见的反爬措施是需要学习掌握的,否则无法顺利爬取到想要的数据。
需要补充学习的部分:
- 大致了解网络协议:HTTP/HTTPS 协议、tcp-ip协议;
- 了解HTML 、CSS、等前端基础;
- 理解网站的POST GET的一些相关概念,JS的一些基本内容,方便理解动态网页。
总结一下:
想要自己写一个Python爬虫程序,必须学会Python基础,包括环境安装、基础语法、字典、正则匹配、还有一些数据处理技术等等。
其次就是模拟请求的库request以及解析库的使用,还有一些反爬技术和前端基础。
2)爬虫的工作流程
简记为“爬虫四部曲”;
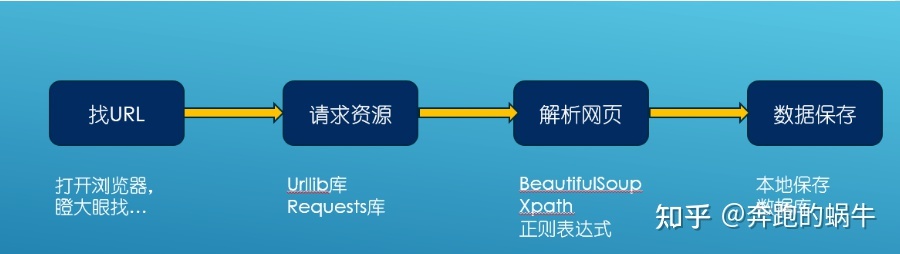
① 发起请求
使用http库向目标站点发起请求,即发送一个Request;
Request包含:请求头、请求体等;
如果只进行基本的爬虫网页抓取,urllib库足够用,Requests使用起来更简洁,自带json解析器,应付大多数的静态网页爬取问题不大。
涉及到动态网页抓取的话就要用到Selenium了,通常配合PhantomJS使用,,Selenium+PhantomJS可以抓取那些使用JS加载数据的网页。
② 获取响应内容
如果服务器能正常响应,则会得到一个Response;
Response包含:html、json、图片、视频等;
③ 解析内容
解析html数据:正则表达式、第三方解析库如Beautifulsoup、pyquery等;
解析json数据:json模块
解析二进制数据:以b的方式写入文件
个人一般情况下会用bs4,bs4无法满足就用正则。
正则一般用来满足特殊需求、以及提取其他解析器提取不到的数据,re速度比较快,但是写正则比较麻烦。
前端基础比较扎实的,用pyquery是最方便的,当然了,自己哪个用着方便就用哪个,无需纠结。
④ 保存数据
需要用到数据库;
- 小规模数据:可以使用txt文件、json文件、csv文件等方式来保存文件;
- 大规模数据:就需要使用mysql、mongodb、redis等数据库;
这步比较简单,掌握主流的数据库使用就差不多了。
如果是对爬虫这个领域很感兴趣的可以去听听免费的公开课,看看自己的学习天赋如何,下方也给大家留了一个传送门~
<Python爬虫学习免费公开课 点击跳转第三方>
爬虫学习资料下方也有整理一部分(有视频教程,文档,写好的代码文件,以及一些爬虫所需要的软件安装包),有需要的可以下方自提
点此免费领取:CSDN大礼包:《python兼职资源&全套学习资料》免费分享
二、关于爬虫可爬与不可爬的问题
其实我们生活中几乎每天都在爬虫应用,如百度,你在百度中搜索到的内容几乎都是爬虫采集下来的,(百度自营的产品除外,如百度知道、百科等)。
网络爬虫作为一门技术,技术本身是不违法的。
但是!记住重点!也不是网站的所有内容想爬就爬!随便你爬的!

以下情况需要注意,爬虫有可能违法:
(1)爬虫程序规避网站经营者设置的反爬虫措施或者破解服务器防抓取措施,也就是非法获取相关信息。
(2)爬取网上公开信息不犯法,但如果大量开启爬虫导致对方服务器崩溃,这属于暴力攻击的范畴了,肯定不可以的。
(3)爬虫采集的信息属于公民个人信息,不能涉及到个人的隐私问题,如果涉及了并通过非法途径收益了,那肯定是违法行为咯。
当采集的站点有声明禁止爬虫采集或者转载商业化时:

淘宝网的法律声明
这么明显的提示了应该不会有人想不开吧!
当网站声明了Robots 协议:
是一种存放于网站根目录下的 ASCII 编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。
Robots 协议就是告诉爬虫,哪些信息是可以爬取,哪些信息不能被爬取,严格按照 Robots 协议爬取网站相关信息一般不会出现太大问题。
如何查看采集的内容是否有Robots 协议?
方法很简单,你想查看的话就在IE上打http://你的网址/robots.txt,站长工具也可以。
比如淘宝的robots协议 ([http://www.taobao.com/robots.txt]
协议里最常出现的英文是Allow和Disallow,Allow代表可以被访问,Disallow代表禁止被访问。
所以在接单的时候保持适当的严谨是有必要的,哪些单子能接,哪些不能接自己心里得有个判断和分寸。
不要为一些明显是做灰黑产的人或者公司写代码,最好的避免违法的办法就是明显觉得不太好的事情就不要去碰,不要抱侥幸心理。

三、如何接单
点此免费领取:CSDN大礼包:《python兼职资源&全套学习资料》免费分享
(安全链接)
(1)怎么接单?
一般而言,对于刚刚开始接单的人而言,很难接到大单,基本上都是一些比较小的单。
但是没有关系啊,正好可以练手!
这些小单是可以提供一个很好的锻炼以及实践的机会,所以不要害怕接。
接单新手基本上接的都是网络爬虫、数据分析等这类的单,当然也可能有一些自动化运维之类的,但是都比较少。
个人做的话不太建议去抢一些几千元一个的项目,难度比较大,交付时间又紧,有些还是团对作战在抢单,这类单子要做的话难度高。
一般我们向甲方提供爬虫、数据分析、数据清洗这样的服务。
一开始也不要想着一口塞进个包子,慢慢来,等到技术提升之后可以去接一些开发之类的活,像APP开发、小程序开发都是几千的单子。

通过接单平台赚外快是个直接快速的方法,不同的任务需求难度不同,报酬在一两百、几千上万都有,具体能赚多少,看自己的技术水平。
接单报价方式:
简单公式:项目工时*日薪+紧急程度+报价
小tip:记得留个bug,防止不给尾款;
(2)整理的一些接单平台:
程序员客栈

程序员客栈中国非常领先的自由工作平台,支持按需雇佣,工作模式非常多,感兴趣的大家可以尝试一下。
码市

互联网软件外包服务平台,适合专门为开发者而提供的平台,接单方式是企业发布项目招募报名参与,企业方筛选合作项目分阶段结算。
猪八戒网
找兼职的地方,主要是入门级项目,不适合专业程序员,只适合新手。
开源众包

开源中国的众包平台,主要是以众包为主
猿急送
最后
Python崛起并且风靡,因为优点多、应用领域广、被大牛们认可。学习 Python 门槛很低,但它的晋级路线很多,通过它你能进入机器学习、数据挖掘、大数据,CS等更加高级的领域。Python可以做网络应用,可以做科学计算,数据分析,可以做网络爬虫,可以做机器学习、自然语言处理、可以写游戏、可以做桌面应用…Python可以做的很多,你需要学好基础,再选择明确的方向。这里给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
👉Python所有方向的学习路线👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

👉Python必备开发工具👈
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

👉Python全套学习视频👈
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

👉实战案例👈
学python就与学数学一样,是不能只看书不做题的,直接看步骤和答案会让人误以为自己全都掌握了,但是碰到生题的时候还是会一筹莫展。
因此在学习python的过程中一定要记得多动手写代码,教程只需要看一两遍即可。

👉大厂面试真题👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









