








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
8、消费组
多个消费者组成一个消费组,为什么要有消费组的概念?首先要引入两个概念
①单播消息:在一个topic中,生产者生产一条消息后,如果有多个消费者同时监听,只有一个消费者能收到该消息。
②多播消息:多个消费者组成为多个消费组,以消费组的去监听消息,那么每个消费组都能收到消息。但只有消费组里的其中一个消费者能收到消息。
如图所示:消费组group1和group2均能收到消息,但也只有组内的消费者1和消费者3收到了消息

9、整体架构
①以下是一个包含八个broker的kafka集群A,一个broker代表一个可用的kafka实例
②一个broker内的一个主题包含了三个分区,分别为p0,p1,p2分区。
③每个分区又有两份follower副本,每个副本又分别存储在不同的broker下,这就保证了单个broker挂了也不会影响整体的可用性。

二、安装使用及相关文件说明
1.Linux本地伪分布式安装及相关配置
①下载压缩包https://kafka.apache.org/downloads

②输入tart -zxvf 文件名解压

③复制三个/kafka_2.12-3.0.0/config/server.properties的文件分别为如下server0.properties、server1.properties、server2.properties在新创建的etc目录下,同时把config下的也zookeeper.properties复制过来。

④修改server0.properties、server1.properties、server2.properties的内容分别如下,其中log.dirs里存储的就是kafka里的具体数据
sever0:
server1:
server2:
⑤、进入bin目录,启动zookeeper后,启动kafka0、1、2。(分别开四个窗口启动每条命令)
启动zookeeper:
[root@localhost bin]# ./zookeeper-server-start.sh ../etc/zookeeper.properties
启动Kafka0、1、2
[root@localhost bin]# ./kafka-server-start.sh ../etc/server0.properties
[root@localhost bin]# ./kafka-server-start.sh ../etc/server1.properties
[root@localhost bin]# ./kafka-server-start.sh ../etc/server2.properties
⑥本文仅展示在同一台服务器上伪分布式的部署,正式的部署需要在多台服务器启动多个kafka实例,同时要提前启动zookeeper,然后在个Kafka实例的server.properites上修改如下修改信息即可,其中第一个ip地址代表当前实例的ip及端口号,第二个代表zookeeper的ip端口号。

2、/tmp/kafka-logs文件说明
进入/tmp/kafka0-logs/目录,可以看到
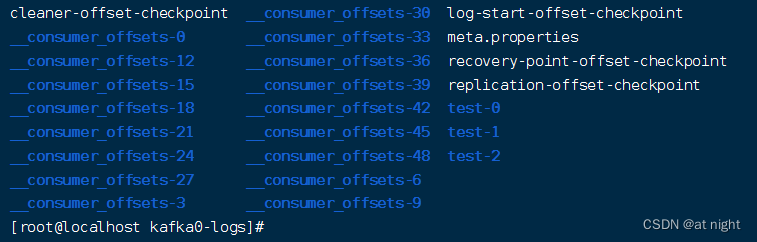
1)test-0:topic为test的文件目录,其他test-1和test-2分别为之前创建另外两个副本
进入test-0,可以看到
①0000000.index:消息实体内容的索引文件
②0000000.log:消息的实体内容存储文件
③0000000.timeindex:根据时间来映射的索引文件。
2)_consumer_offsets系列文件:
①该系列文件是kafka官方的消费者偏移的主题文件,用于保存 consumer 消费消息后的当前偏移量。
②由于消费者也有集群的概念,当同一事务中的某个消费者消费的过程中挂了,集群里的其他消费者就需要继续之前的消费任务,此时,就能通过该偏移量继续之前的消费。
③由于消费者可能会有很多,所以官方默认为该topic创建50个分区,并根据消费组id哈希路由到每个分区上,可以看到,消息的key为消费组id+topic+分区的组合。

三、相关命令操作
1、创建主题
进入bin目录:输入
[root@localhost bin]# ./kafka-topics.sh --create --topic test --bootstrap-server localhost:9092 --partitions 3 --replication-factor 3
①- -topic test:创建名为test的主题
②- -bootstrap-server localhost:9092:任意一个活跃的Kafka服务的ip端口
③- -partitions 3:主题分区设置为3个
④- -replication-factor 3:副本因子设置为3,即总共三份partition,一份leader,两份follower
2、查看主题详情
1)、查看所有主题
[root@localhost bin]# ./kafka-topics.sh --list --bootstrap-server localhost:9093
2)、查看某个主题详情
[root@localhost bin]# ./kafka-topics.sh --bootstrap-server localhost:9093 --describe --topic test
结果:可以看到创建了0、1、2个分区,每个分区分别有三个副本0、1、2

3、发送和消费消息
1)生产者发消息
输入如下命令后,出现>号,表示已经打开客户端,输入asd回车后即可发送消息
[root@localhost bin]# ./kafka-console-producer.sh --broker-list localhost:9092 --topic test
>asd
2)消费者消费消息
方式一:从最后一条消息的偏移量+1开始消费,也就意味着,如果还没进入消费者客户端,生产者就已经发了消息,再使用如下命令是收不到之前发的消息。
[root@localhost bin]# ./kafka-console-consumer.sh --bootstrap-server localhost:9094 --topic test
方式二:从头开始消费,可以收到生产者之前发的信息
[root@localhost bin]# ./kafka-console-consumer.sh --bootstrap-server localhost:9094 --from-beginning --topic test
3)以消费组的形式消费消息,可实现多播消息
①创建消费组testGroup1
[root@localhost bin]# ./kafka-console-consumer.sh --bootstrap-server localhost:9094 --consumer-property group.id=testGroup1 --topic test
②开启另一个终端创建消费组testGroup2
[root@localhost bin]# ./kafka-console-consumer.sh --bootstrap-server localhost:9094 --consumer-property group.id=testGroup2 --topic test
③生产者发送消息,结果最终两个消费组均收到消息



4)查看消费组及信息
①查看所有消费组
[root@localhost bin]# ./kafka-consumer-groups.sh --bootstrap-server localhost:9094 --list
②查看消费组的具体信息:当前偏移量,最后一条消息的偏移量、堆积的消息量
[root@localhost bin]# ./kafka-consumer-groups.sh --bootstrap-server localhost:9094 --describe --group testGroup1
结果:

CURRENT-OFFSET:当前被消费的消息偏移量
LOG-END-OFFSET:当前队列上最后一条消息的偏移量(消息总量)
LAG:当前积压的消息量
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1020
1020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









