







总结
虽然面试套路众多,但对于技术面试来说,主要还是考察一个人的技术能力和沟通能力。不同类型的面试官根据自身的理解问的问题也不尽相同,没有规律可循。


上面提到的关于这些JAVA基础、三大框架、项目经验、并发编程、JVM及调优、网络、设计模式、spring+mybatis源码解读、Mysql调优、分布式监控、消息队列、分布式存储等等面试题笔记及资料
有些面试官喜欢问自己擅长的问题,比如在实际编程中遇到的或者他自己一直在琢磨的这方面的问题,还有些面试官,尤其是大厂的比如 BAT 的面试官喜欢问面试者认为自己擅长的,然后通过提问的方式深挖细节,刨根到底。
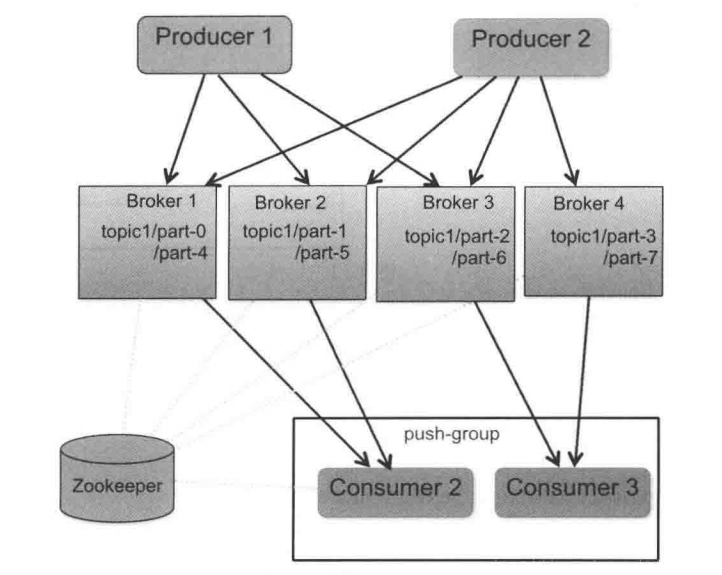
整体架构很简单,Kafka给Producer和Consumer提供注册的接口,数据从Producer发送到Broker,Broker承担一个中间缓存和分发的作用,负责分发注册到系统中的Consumer。
设计要点
Kafka非常高效,下面介绍Kafka高效的原因,对理解Kafka非常用帮助。
-
直接使用Linux文件系统的Cache来高效缓存数据
-
采用Linux Zero-Copy提高发送性能。传统的数据发送需要发送4次上下切换,采用Sendfile系统调用之后,数据直接在内核态交换,系统上下文切换减少为2次。可以提高60%的数据发送性能。
Kafka以Topic来进行消费管理,每个Topic包含多个Part(ition),每个Part对应一个逻辑Log,由多个Segment组成。每个Segment中存储多条消息,消息ID由逻辑位置决定,即从消息ID可直接定位到消息的存储位置,避免ID到位置的额外映射。每个Part在内存中对应一个Index,记录每个Segment中的第一个消息偏移。
发布者发到某个Topic的消息会被均匀地分布到多个Part上(随机或根据用户指定的回调函数进行分布),Broker收到发布消息后往对应Part的最后一个Segment上添加该消息,当某个Segment上的消息条数到达配置值或消息发布时间超过阈值时,Segment上的消息便会被flush到磁盘上,只有flush到磁盘上的消息订阅者才能订阅到,Segment达到一定的大小后将不会再往该Segment写数据,Broker会创建新的Segment。
全系统分布式,即所有的Producer、Broker和Consumer都默认有多个,均为分布式的。Producer和Broker之间没有负载均衡机制。Broker和Consumer 之间利用ZooKeeper进行负载均衡。所有的Broker和Consumer都会在Zookeeper中进行注册,且Zookeeper会保存他们的一些元数据信息。如果某个Broker和Consumer发生了变化,那么所有其他的Broker和Consumer都会得到通知。
Kafka消息存储方式
Topc
Topic是发布的消息的类别或者种子Feed名。对于每个Topic,Kafka集群都会维护这个分区的Log。如图
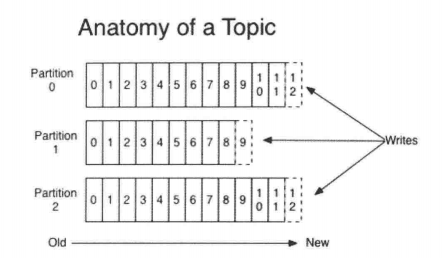
每个分区都是一个顺序的、不可变的消息队列,并且可以持续添加。分区中的消息都被分配了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。
Kafka集群保存所有的消息,直到他们过期,无论消息是否被消费。实际上,消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个Log中的位置。在正常情况下,当消费者消费消息的时候偏移量也线性增加。但是实际偏移量由消费者控制,消费者可以重置偏移量,以重新读取消息。
这种设计对消费者来说操作自如,一个消费者的操作不会影响其他消费者对此Log的处理。
分区
Kafka中采用分区的设计有两个目的:一是可以处理更多的消息,而不受单体服务器的限制,Topic拥有多个分区,意味着它可以不受限制地处理更多数据;二是分区可以作为并行处理的单元。
Kafka会为每个分区创建一个文件夹,文件夹的命名方式为topicName-分区序号,如图
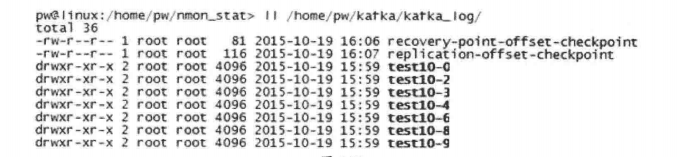
而分区是由多个Segment组成的,是为了方便进行日志清理、恢复等工作。每个Segment以该Segment第一条消息的offset命名并以“.log”作为后缀。另外还有一个索引文件,他标明了每个Segment下包含的Log Entry的offset范围,文件命名方式也是如此,以“.index”作为后缀,如下:

索引和日志文件内部的关系,如图:
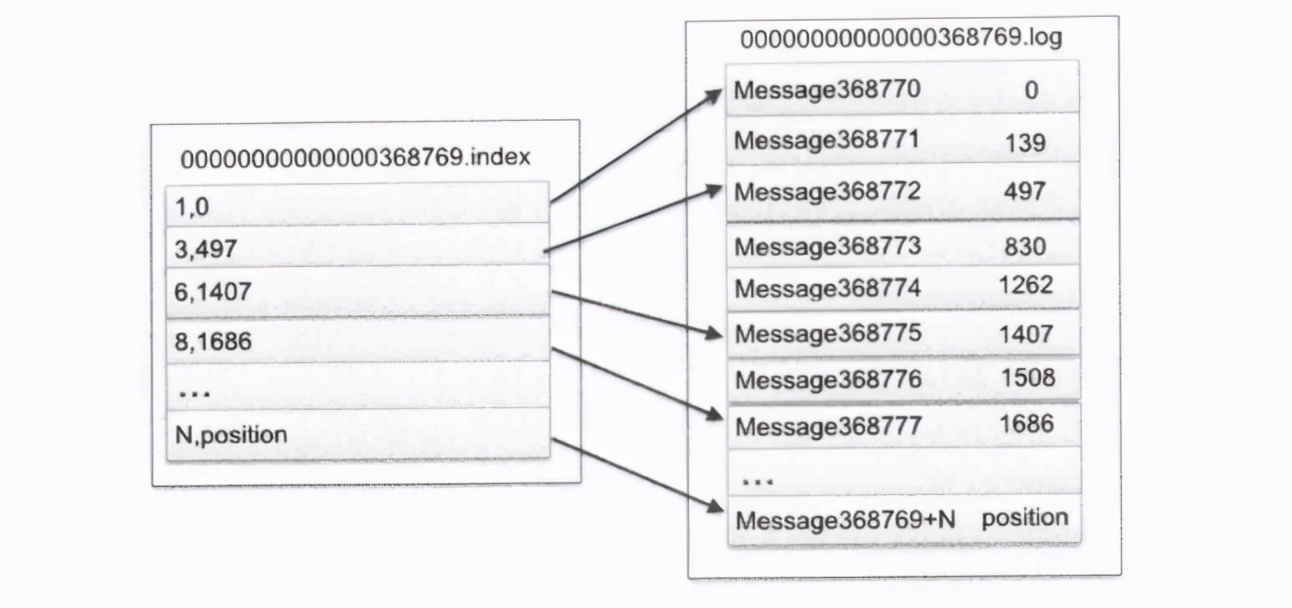
索引文件存储大量元数据,数据文件存储大量消息(Message),索引文件中的元数据指向对应数据文件中Message的物理偏移地址。以索引文件中的元数据3,497为例,依次在数据文件中表示第三个Message(在全局Partition中表示第368772个message),以及该消息的物理偏移地址为497.
Segment的Log文件由多个Message组成,下面详细说明Message的物理结构,如图:
最后
笔者已经把面试题和答案整理成了面试专题文档






+核心总结学习笔记+最新讲解视频+实战项目源码】](https://bbs.csdn.net/topics/618154847)收录**















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









