







 本文介绍了如何在爬虫中避免因末尾斜线、锚点等问题导致的重复抓取,并详细说明了爬取规则的设定,包括排除特定类型地址、处理相对路径、验证地址有效性。同时提到了使用Python3.6和多线程技术提高效率,以及提供相关学习资源和社群支持。
本文介绍了如何在爬虫中避免因末尾斜线、锚点等问题导致的重复抓取,并详细说明了爬取规则的设定,包括排除特定类型地址、处理相对路径、验证地址有效性。同时提到了使用Python3.6和多线程技术提高效率,以及提供相关学习资源和社群支持。
防止因末尾斜线、锚点而重复爬取(http://www.example.com、http://www.example.com、http://www.example.com/index.html#xxoo)

爬取规则:
第一个无法爬取页面注释中的地址(<!–http://example.com/index.html–>),第二个无法爬取相对路径和php?id=等类型的地址,古结合两种规则,并排除图片视频类的地址,最后再去重
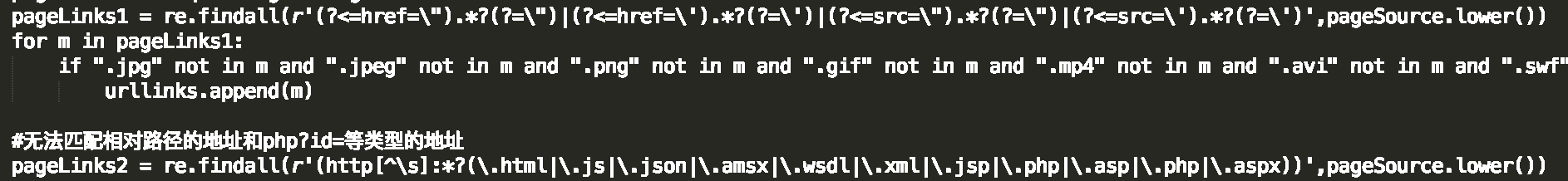
补全相对地址、防止越界(可爬取子域名,其他地址除外),并验证地址是否能正常访问
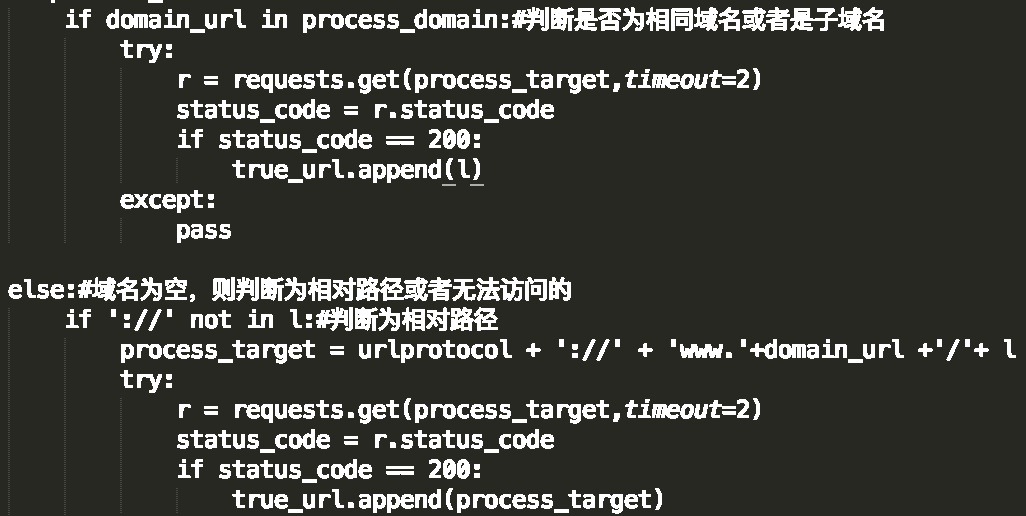
地址池
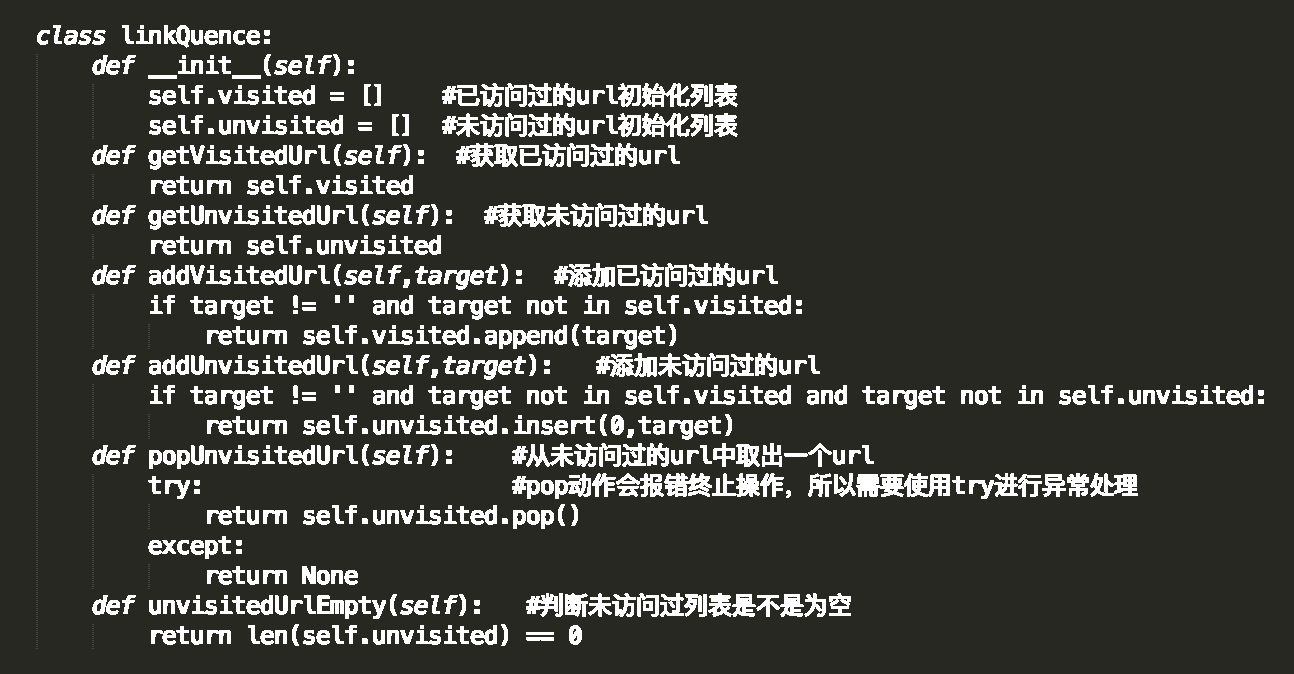
爬取功能,虽然使用了多线程,但还是比较慢,输出结果是爬取完毕的地址

目录扫描和输出到文件

0×04 代码地址:
https://github.com/silience/spider
0×05 参考链接:
#http://blog.csdn.net/foryouslgme/article/details/52242653
最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1044
1044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









