







 本文介绍了Scrapy-Redis框架中Master和Slaver节点的工作原理,包括如何使用随机User-Agent和代理IP进行爬取,分布式策略下的URL指纹判重和任务分配,以及如何将数据存储到Redis和MySQL数据库。同时讨论了数据持久化和如何通过规则实现翻页功能。
本文介绍了Scrapy-Redis框架中Master和Slaver节点的工作原理,包括如何使用随机User-Agent和代理IP进行爬取,分布式策略下的URL指纹判重和任务分配,以及如何将数据存储到Redis和MySQL数据库。同时讨论了数据持久化和如何通过规则实现翻页功能。
def process_request(self, request, spider):
useragent = random.choice(USER_AGENTS)
#print useragent
request.headers.setdefault(“User-Agent”, useragent)
# 随机的代理ip
class RandomProxy(object):
def process_request(self, request, spider):
proxy = random.choice(PROXIES)
# 没有代理账户验证的代理使用方式
request.meta[‘proxy’] = “http://” + proxy[‘ip_port’]
在setting.py中开启下载中间件:
DOWNLOADER_MIDDLEWARES = {
‘dytt_redis_slaver.middlewares.RandomUserAgent’: 543,
‘dytt_redis_slaver.middlewares.RandomProxy’: 553,
}
**二、Master端代码**
Scrapy-Redis分布式策略中,Master端(核心服务器),不负责爬取数据,只负责url指纹判重、Request的分配,以及数据的存储,但是一开始要在Master端中lpush开始位置的url,这个操作可以在控制台中进行,打开控制台输入:
redis-cli
127.0.0.1:6379> lpush dytt:start_urls https://www.dy2018.com/0/
也可以写一个爬虫对url进行爬取,然后动态的lpush到redis数据库中,这种方法对于url数量多且有规律的时候很有用(不需要在控制台中一条一条去lpush,当然最省事的方法是在slaver端代码中增加rule规则去实现url的获取)。比如要想获取所有电影的分类。
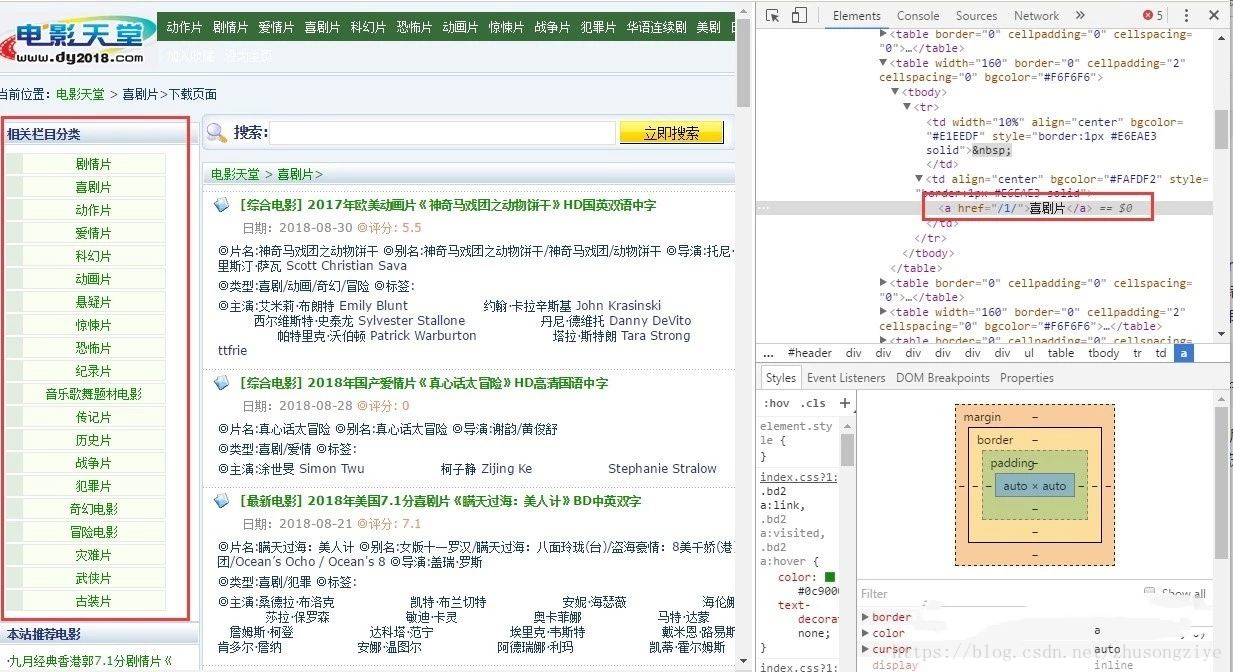
链接就是一个或者两个数字,所以rule规则为:
rules = (
Rule(LinkExtractor(allow=r’/\d{1,2}/$'), callback=‘parse_item’),
)
在parse\_item中返回这个请求链接:
def parse_item(self, response):
# print(response.url)
items = DyttRedisMasterItem()
items[‘url’] = response.url
yield items
piplines.py中,将获得的url全部lpush到redis数据库:
import redis
class DyttRedisMasterPipeline(object):
def init(self):
# 初始化连接数据的变量
self.REDIS_HOST = ‘127.0.0.1’
self.REDIS_PORT = 6379
# 链接redis
self.r = redis.Redis(host=self.REDIS_HOST, port=self.REDIS_PORT)
def process_item(self, item, spider):
# 向redis中插入需要爬取的链接地址
self.r.lpush(‘dytt:start_urls’, item[‘url’])
return item
运行slaver端时,程序会等待请求的到来,当starts\_urls有值的时候,爬虫将开始爬取,但是一开始并没有数据,因为会过滤掉重复的链接:
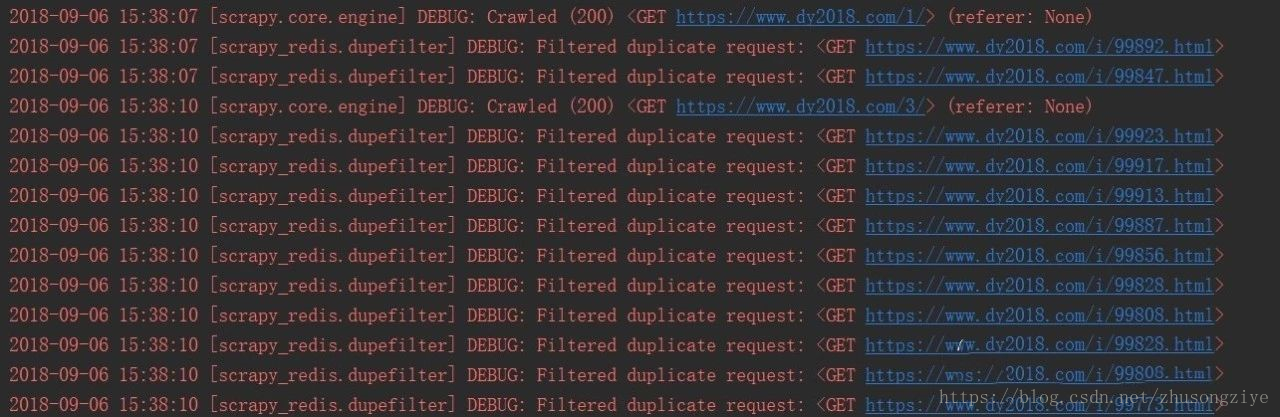
毕竟有些电影的类型不止一种:

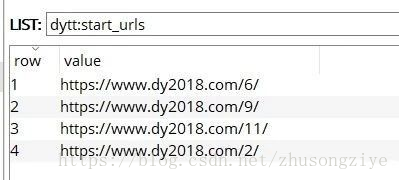
scrapy默认16个线程(当然可以修改为20个啊),而分类有20个,所以start\_urls会随机剩下4个,等待任务分配:
当链接过滤完毕后,就有数据了:
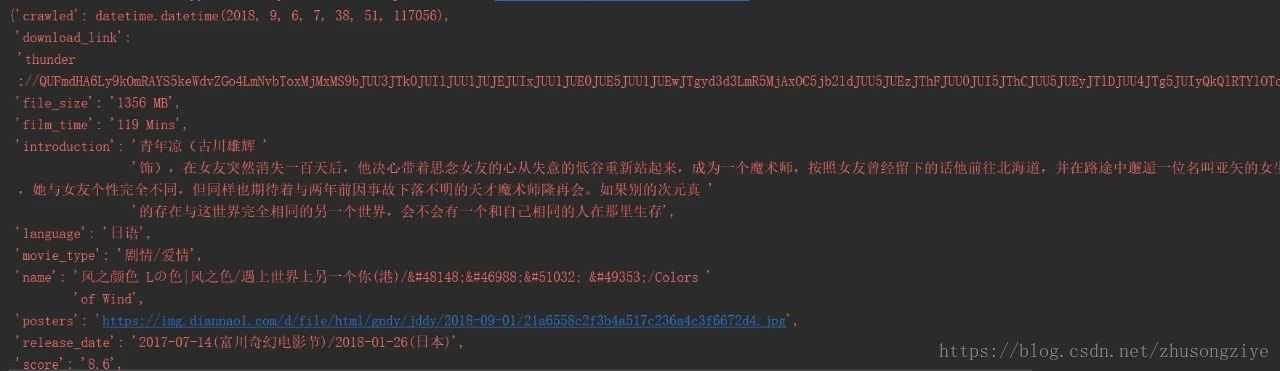
因为在setting.py中设置了:
SCHEDULER_PERSIST = True
所以重新启动爬虫的时候,会接着之前未完成的任务进行爬取。在slaver端中新增rule规则可以实现翻页功能:
page_links = LinkExtractor(allow=r’/index_\d*.html’)
rules = (
# 翻页规则
Rule(page_links),
# 进入电影详情页
Rule(movie_links, callback=‘parse_item’),
)
**三、数据转存到Mysql**
因为,redis只支持String,hashmap,set,sortedset等基本数据类型,但是不支持联合查询,所以它适合做缓存。将数据转存到mysql数据库中,方便以后查询:
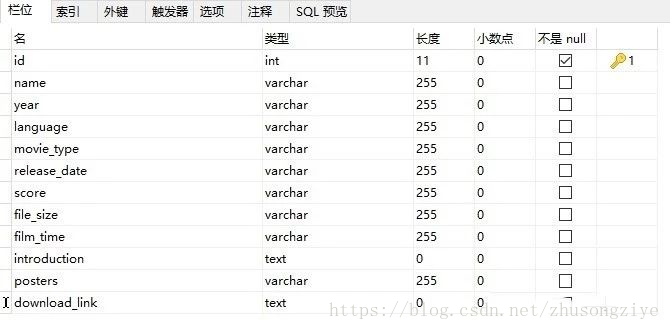
创建数据表:
代码如下:
# -- coding: utf-8 --
import json
import redis
import pymysql
def main():
# 指定redis数据库信息
rediscli = redis.StrictRedis(host=‘127.0.0.1’, port=6379, db=0)
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2783
2783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









