







写在最后
可能有人会问我为什么愿意去花时间帮助大家实现求职梦想,因为我一直坚信时间是可以复制的。我牺牲了自己的大概十个小时写了这片文章,换来的是成千上万的求职者节约几天甚至几周时间浪费在无用的资源上。


上面的这些(算法与数据结构)+(Java多线程学习手册)+(计算机网络顶级教程)等学习资源
name varchar(10),
sex varchar(1),
age int
);
1.3 UNIQUE 唯一约束
指定id列为唯一的,不重复:
drop table if exists student;
create table student(
id int UNIQUE, --id为唯一的
name varchar(10),
sex varchar(1),
age int
);
1.4 DEFAULT 默认值约束
指定插入数据时,如果name列为空,则将默认值设为unkown:
drop table if exists student;
create table student(
id int UNIQUE,
name varchar(10) DEFAULT ‘unkown’,
sex varchar(1),
age int
);
1.5 PRIMARY KEY 主键约束
指定id列为主键:
drop table if exists student;
create table student(
id int PRIMARY KEY,
name varchar(10) DEFAULT ‘unkown’,
sex varchar(1),
age int
);
对于整数类型的主键,常搭配自增长auto_increment来使用,插入数据对应字段不给值,使用最大值+1
id int PRIMARY KEY auto_increment,
1.6 FOREIGN KEY 外键约束
外键用于关联其他表的主键或唯一值
语法:
foreign key (字段名) references 主表(列);
示例:
创建班级表:
– 创建班级表
drop table if exists classes;
create table classes(
id int primary key auto_increment,
name varchar(20)
);
创建学生表,一个学生对应一个班级,一个班级对应多个学生,id为主键,classes_id为外键,关联班级表id:
– 创建学生表来关联班级表
drop table if exists student;
create table student(
id int PRIMARY KEY,
name varchar(10) DEFAULT ‘unkown’,
sex varchar(1),
classes_id int,
foreign key (classes_id) references classes(id)
);
1.7 CHECK约束(了解)
MySQL使用时不报错,但忽略该约束:
create table test_user (
id int,
name varchar(10),
sex varchar(1),
check (sex = ‘男’ or sex = ‘女’)
);
2. 表的设计
========
三大范式:
一对一:
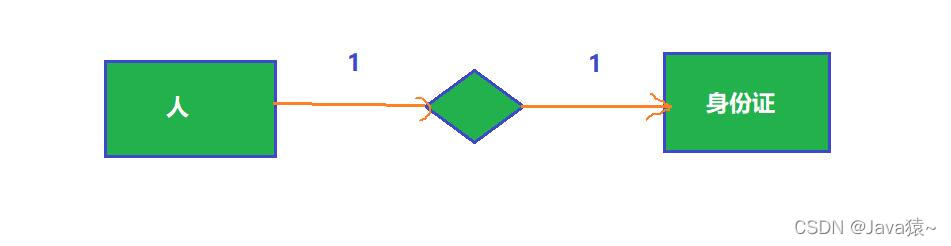
一对多:

多对多:

创建课程表:
drop table if exists course;
create table course (
id int primary key auto_increment,
name varchar(20)
);
创建学生课程中间表,考试成绩表:
drop table if exists score;
create table score (
id int primary key auto_increment,
score decimal(3,1),
student_id int,
course_id int,
foreign key (student_id) references student(id),
foreign key (course_id) references course(id)
);
3. 新增
======
插入查询的结果
语法:
INSERT INTO table_name [(column [, column …])] SELECT …
示例:
新建一张user表:
create table user (
id int primary key auto_increment,
name varchar(10),
sex varchar(1),
age int,
email varchar(20)
);
将学生表的数据复制到user表中:
insert into user (name,sex,age) select name,sex,age from student;
4. 查询
======
4.1 聚合查询
4.1.1 聚合函数
常见的统计总数,计算平均值等操作,可以使用聚合查询来实现,常见的聚合函数:
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的总和 |
| AVG([DISTINCT] expr) | 返回查询到的数据的平均值 |
| MAX([DISTINCT] expr) | 返回查询到的数据的最大值 |
| MIN([DISTINCT] expr) | 返回查询到的数据的最小值 |
示例:
· COUNT
– 统计班级有多少个同学
select count(*) from student;
select count(0) from student;
· SUM
– 统计学生的数学总成绩
select sum(math) from student_score;
– 统计不及格学生的数学总成绩
select sum(math) from student_score where math<60;
· AVG
– 统计平均总分
select avg(chinese+math+english) from student_score;
· MAX
– 找出英语的最高成绩
select max(english) from student_score;
· MIN
– 找出语文的最低成绩
select min(chinese) from student_score;
4.1.2 GROUP BY
select中使用group by子句可以对指定列进行分组查询,需要满足:使用group by 进行分组查询时,select指定的字段必须是“分组依据字段”,其他字段要想出现在select中必须包含在聚合函数中。
语法:
select column1, sum(column2), … from table group by column1,column3;
案例表:
create table emp (
id int primary key auto_increment,
name varchar(10),
role varchar(10) comment ‘角色’,
salary decimal(10,2) comment ‘薪资’
);
insert into emp (name,role,salary) values
(‘小王’,‘员工’,3000.50),
(‘小贺’,‘老板’,200000.00),
(‘小张’,‘秘书’,15000),
(‘小方’,‘保洁员’,3000),
(‘小乔’,‘员工’,4500.20),
(‘小李’,‘员工’,5000.28);
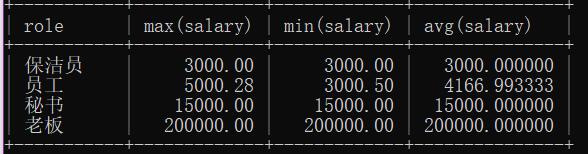
查询每个角色的最高工资,最低工资和平均工资:
select role,max(salary),min(salary),avg(salary) from emp group by role;
结果:
4.1.3 HAVING
GROUP BY子句进行分组后,如果要对分组后的结果进行条件过滤不能使用WHERE,要使用HAVING语句。
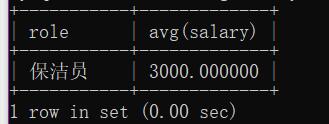
示例:显示平均工资低于4000的角色,和他的平均工资:
select role,avg(salary) from emp group by role having avg(salary)<4000;
结果:
4.2 联合查询
先将后续用到的表和数据给出:班级表,学生表,课程表,分数表
drop table if exists classes;
create table classes (
id int primary key auto_increment,
name varchar(20)
);
insert into classes (name) values
(‘计算机1班’),
(‘自动化2班’),
(‘机械3班’);
drop table if exists student;
create table student (
id int primary key auto_increment,
name varchar(10),
classes_id int,
foreign key (classes_id) references classes(id)
);
insert into student (name,classes_id) values
(‘小花’,2),
(‘小张’,1),
(‘小贺’,1),
(‘小方’,3),
(‘小乔’,3);
drop table if exists course;
create table course (
id int primary key auto_increment,
name varchar(20)
);
insert into course (name) values
(‘java程序设计’),
(‘大学英语’),
(‘高等数学’),
(‘数据结构’),
(‘工程制图’);
drop table if exists score;
create table score (
id int primary key auto_increment,
score decimal(3,1),
student_id int,
course_id int,
foreign key (student_id) references student(id),
foreign key (course_id) references course(id)
);
insert into score (score,student_id,course_id) values
– 小花
(98.5,1,3),(80,1,5),
– 小张
(99,2,1),(95,2,2),(96,2,3),(90,2,4),(93,2,5),
– 小贺
(85,3,1),(86,3,2),(86,3,3),(95,3,4),
– 小方
(70,4,3),(65,4,5),
– 小乔
(65,5,5),(67,5,3),(68,5,2);
实际的开发中,数据来自不同的表,这时候需要多张表联合查询,多表查询是对多张表的数据取笛卡尔积。
笛卡尔积:
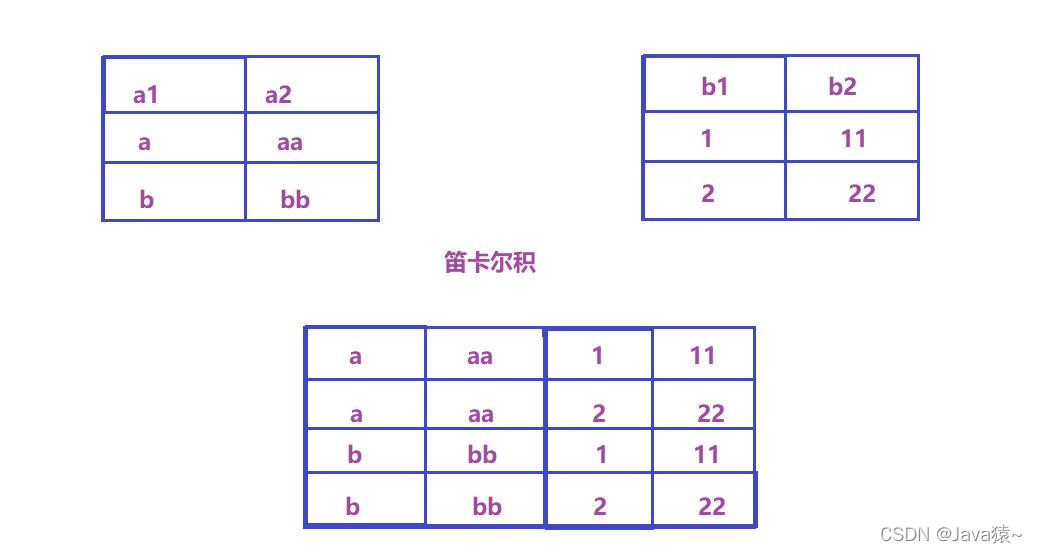
注意:关联查询可以对关联表使用别名
4.2.1 内连接
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
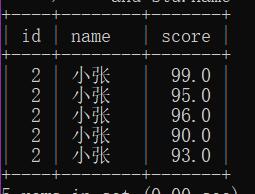
示例:查询“小张”同学的成绩:
select
stu.id,
stu.name,
sco.score
from
student stu
join score sco on stu.id = sco.student_id
and stu.name=‘小张’;
结果:
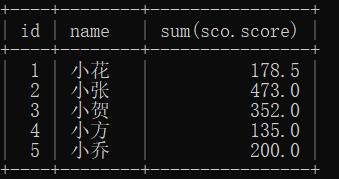
示例:查询所有同学的总成绩,及同学的个人信息:
select
stu.id,
stu.name,
sum(sco.score)
from
student stu
join score sco on stu.id = sco.student_id
group by
stu.id;
结果:
示例:查询所有同学的成绩,及同学的个人信息:
select
最后:学习总结——MyBtis知识脑图(纯手绘xmind文档)
学完之后,若是想验收效果如何,其实最好的方法就是可自己去总结一下。比如我就会在学习完一个东西之后自己去手绘一份xmind文件的知识梳理大纲脑图,这样也可方便后续的复习,且都是自己的理解,相信随便瞟几眼就能迅速过完整个知识,脑补回来。下方即为我手绘的MyBtis知识脑图,由于是xmind文件,不好上传,所以小编将其以图片形式导出来传在此处,细节方面不是特别清晰。但可给感兴趣的朋友提供完整的MyBtis知识脑图原件(包括上方的面试解析xmind文档)

除此之外,前文所提及的Alibaba珍藏版mybatis手写文档以及一本小小的MyBatis源码分析文档——《MyBatis源码分析》等等相关的学习笔记文档,也皆可分享给认可的朋友!
join score sco on stu.id = sco.student_id
group by
stu.id;
结果:
示例:查询所有同学的成绩,及同学的个人信息:
select
最后:学习总结——MyBtis知识脑图(纯手绘xmind文档)
学完之后,若是想验收效果如何,其实最好的方法就是可自己去总结一下。比如我就会在学习完一个东西之后自己去手绘一份xmind文件的知识梳理大纲脑图,这样也可方便后续的复习,且都是自己的理解,相信随便瞟几眼就能迅速过完整个知识,脑补回来。下方即为我手绘的MyBtis知识脑图,由于是xmind文件,不好上传,所以小编将其以图片形式导出来传在此处,细节方面不是特别清晰。但可给感兴趣的朋友提供完整的MyBtis知识脑图原件(包括上方的面试解析xmind文档)
[外链图片转存中…(img-9nEUpN9k-1715421323087)]
除此之外,前文所提及的Alibaba珍藏版mybatis手写文档以及一本小小的MyBatis源码分析文档——《MyBatis源码分析》等等相关的学习笔记文档,也皆可分享给认可的朋友!















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









