







bar
以上内容便是一些常用的Processor,在本节的实例中我们会使用Processor来进行数据的处理。
接下来,我们用一个实例来了解Item Loader的用法。
三、本节目标
我们以中华网科技类新闻为例,来了解CrawlSpider和Item Loader的用法,再提取其可配置信息实现可配置化。官网链接为:http://tech.china.com/。我们需要爬取它的科技类新闻内容,链接为:http://tech.china.com/articles/,页面如下图所示。

我们要抓取新闻列表中的所有分页的新闻详情,包括标题、正文、时间、来源等信息。
四、新建项目
首先新建一个Scrapy项目,名为scrapyuniversal,如下所示:
scrapy startproject scrapyuniversal
创建一个CrawlSpider,需要先制定一个模板。我们可以先看看有哪些可用模板,命令如下所示:
scrapy genspider -l
运行结果如下所示:
Available templates: basic crawl csvfeed xmlfeed
之前创建Spider的时候,我们默认使用了第一个模板basic。这次要创建CrawlSpider,就需要使用第二个模板crawl,创建命令如下所示:
scrapy genspider -t crawl china tech.china.com
运行之后便会生成一个CrawlSpider,其内容如下所示:
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class ChinaSpider(CrawlSpider):
name = ‘china’
allowed_domains = [‘tech.china.com’]
start_urls = [‘http://tech.china.com/’]
rules = (
Rule(LinkExtractor(allow=r’Items/'), callback=‘parse_item’, follow=True),
)
def parse_item(self, response):
i = {}
#i[‘domain_id’] = response.xpath(‘//input[@id=“sid”]/@value’).extract()
#i[‘name’] = response.xpath(‘//div[@id=“name”]’).extract()
#i[‘description’] = response.xpath(‘//div[@id=“description”]’).extract()
return i
这次生成的Spider内容多了一个rules属性的定义。Rule的第一个参数是LinkExtractor,就是上文所说的LxmlLinkExtractor,只是名称不同。同时,默认的回调函数也不再是parse,而是parse_item。
五、定义Rule
要实现新闻的爬取,我们需要做的就是定义好Rule,然后实现解析函数。下面我们就来一步步实现这个过程。
首先将start_urls修改为起始链接,代码如下所示:
start_urls = [‘http://tech.china.com/articles/’]
之后,Spider爬取start_urls里面的每一个链接。所以这里第一个爬取的页面就是我们刚才所定义的链接。得到Response之后,Spider就会根据每一个Rule来提取这个页面内的超链接,去生成进一步的Request。接下来,我们就需要定义Rule来指定提取哪些链接。
当前页面如下图所示。

这是新闻的列表页,下一步自然就是将列表中的每条新闻详情的链接提取出来。这里直接指定这些链接所在区域即可。查看源代码,所有链接都在ID为left_side的节点内,具体来说是它内部的class为con_item的节点,如下图所示。

此处我们可以用LinkExtractor的restrict_xpaths属性来指定,之后Spider就会从这个区域提取所有的超链接并生成Request。但是,每篇文章的导航中可能还有一些其他的超链接标签,我们只想把需要的新闻链接提取出来。真正的新闻链接路径都是以article开头的,我们用一个正则表达式将其匹配出来再赋值给allow参数即可。另外,这些链接对应的页面其实就是对应的新闻详情页,而我们需要解析的就是新闻的详情信息,所以此处还需要指定一个回调函数callback。
到现在我们就可以构造出一个Rule了,代码如下所示:
Rule(LinkExtractor(allow=‘article/.*.html’, restrict_xpaths=‘//div[@id=“left_side”]//div[@class=“con_item”]’), callback=‘parse_item’)
接下来,我们还要让当前页面实现分页功能,所以还需要提取下一页的链接。分析网页源码之后可以发现下一页链接是在ID为pageStyle的节点内,如下图所示。
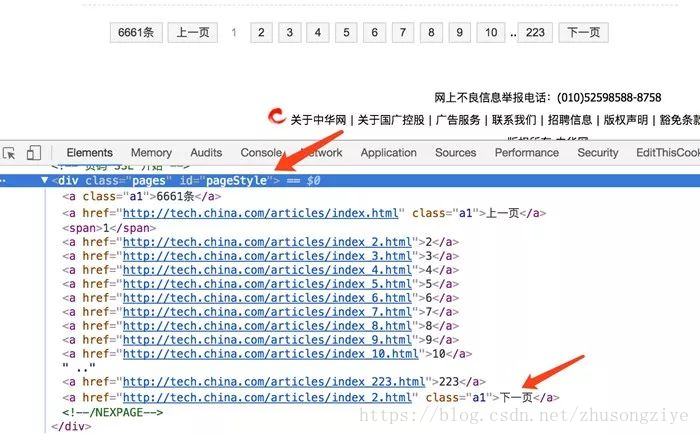
但是,下一页节点和其他分页链接区分度不高,要取出此链接我们可以直接用XPath的文本匹配方式,所以这里我们直接用LinkExtractor的restrict_xpaths属性来指定提取的链接即可。另外,我们不需要像新闻详情页一样去提取此分页链接对应的页面详情信息,也就是不需要生成Item,所以不需要加callback参数。另外这下一页的页面如果请求成功了就需要继续像上述情况一样分析,所以它还需要加一个follow参数为True,代表继续跟进匹配分析。其实,follow参数也可以不加,因为当callback为空的时候,follow默认为True。此处Rule定义为如下所示:
Rule(LinkExtractor(restrict_xpaths=‘//div[@id=“pageStyle”]//a[contains(., “下一页”)]’))
所以现在rules就变成了:
rules = (
Rule(LinkExtractor(allow=‘article/.*.html’, restrict_xpaths=‘//div[@id=“left_side”]//div[@class=“con_item”]’), callback=‘parse_item’),
Rule(LinkExtractor(restrict_xpaths=‘//div[@id=“pageStyle”]//a[contains(., “下一页”)]’))
)
接着我们运行代码,命令如下所示:
scrapy crawl china
现在已经实现页面的翻页和详情页的抓取了,我们仅仅通过定义了两个Rule即实现了这样的功能,运行效果如下图所示。

六、解析页面
接下来我们需要做的就是解析页面内容了,将标题、发布时间、正文、来源提取出来即可。首先定义一个Item,如下所示:
from scrapy import Field, Item
class NewsItem(Item):
title = Field()
url = Field()
text = Field()
datetime = Field()
source = Field()
website = Field()
这里的字段分别指新闻标题、链接、正文、发布时间、来源、站点名称,其中站点名称直接赋值为中华网。因为既然是通用爬虫,肯定还有很多爬虫也来爬取同样结构的其他站点的新闻内容,所以需要一个字段来区分一下站点名称。
详情页的预览图如下图所示。
如果像之前一样提取内容,就直接调用response变量的xpath()、css()等方法即可。这里parse_item()方法的实现如下所示:
def parse_item(self, response):
item = NewsItem()
item[‘title’] = response.xpath(‘//h1[@id=“chan_newsTitle”]/text()’).extract_first()
item[‘url’] = response.url
item[‘text’] = ‘’.join(response.xpath(‘//div[@id=“chan_newsDetail”]//text()’).extract()).strip()
item[‘datetime’] = response.xpath(‘//div[@id=“chan_newsInfo”]/text()’).re_first(‘(\d±\d±\d+\s\d+:\d+:\d+)’)
item[‘source’] = response.xpath(‘//div[@id=“chan_newsInfo”]/text()’).re_first(‘来源:(.*)’).strip()
item[‘website’] = ‘中华网’
yield item
这样我们就把每条新闻的信息提取形成了一个NewsItem对象。
这时实际上我们就已经完成了Item的提取。再运行一下Spider,如下所示:
scrapy crawl china
输出内容如下图所示。

现在我们就可以成功将每条新闻的信息提取出来。
不过我们发现这种提取方式非常不规整。下面我们再用Item Loader,通过add_xpath()、add_css()、add_value()等方式实现配置化提取。我们可以改写parse_item(),如下所示:
def parse_item(self, response):
loader = ChinaLoader(item=NewsItem(), response=response)
loader.add_xpath(‘title’, ‘//h1[@id=“chan_newsTitle”]/text()’)
loader.add_value(‘url’, response.url)
loader.add_xpath(‘text’, ‘//div[@id=“chan_newsDetail”]//text()’)
loader.add_xpath(‘datetime’, ‘//div[@id=“chan_newsInfo”]/text()’, re=‘(\d±\d±\d+\s\d+:\d+:\d+)’)
loader.add_xpath(‘source’, ‘//div[@id=“chan_newsInfo”]/text()’, re=‘来源:(.*)’)
loader.add_value(‘website’, ‘中华网’)
yield loader.load_item()
这里我们定义了一个ItemLoader的子类,名为ChinaLoader,其实现如下所示:
from scrapy.loader import ItemLoader
from scrapy.loader.processors import TakeFirst, Join, Compose
class NewsLoader(ItemLoader):
default_output_processor = TakeFirst()
class ChinaLoader(NewsLoader):
text_out = Compose(Join(), lambda s: s.strip())
source_out = Compose(Join(), lambda s: s.strip())
ChinaLoader继承了NewsLoader类,其内定义了一个通用的Out Processor为TakeFirst,这相当于之前所定义的extract_first()方法的功能。我们在ChinaLoader中定义了text_out和source_out字段。这里使用了一个Compose Processor,它有两个参数:第一个参数Join也是一个Processor,它可以把列表拼合成一个字符串;第二个参数是一个匿名函数,可以将字符串的头尾空白字符去掉。经过这一系列处理之后,我们就将列表形式的提取结果转化为去重头尾空白字符的字符串。
代码重新运行,提取效果是完全一样的。
至此,我们已经实现了爬虫的半通用化配置。
七、通用配置抽取
为什么现在只做到了半通用化?如果我们需要扩展其他站点,仍然需要创建一个新的CrawlSpider,定义这个站点的Rule,单独实现parse_item()方法。还有很多代码是重复的,如CrawlSpider的变量、方法名几乎都是一样的。那么我们可不可以把多个类似的几个爬虫的代码共用,把完全不相同的地方抽离出来,做成可配置文件呢?
当然可以。那我们可以抽离出哪些部分?所有的变量都可以抽取,如name、allowed_domains、start_urls、rules等。这些变量在CrawlSpider初始化的时候赋值即可。我们就可以新建一个通用的Spider来实现这个功能,命令如下所示:
scrapy genspider -t crawl universal universal
这个全新的Spider名为universal。接下来,我们将刚才所写的Spider内的属性抽离出来配置成一个JSON,命名为china.json,放到configs文件夹内,和spiders文件夹并列,代码如下所示:
{
“spider”: “universal”,
“website”: “中华网科技”,
“type”: “新闻”,
“index”: “http://tech.china.com/”,
“settings”: {
“USER_AGENT”: “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36”
},
“start_urls”: [
“http://tech.china.com/articles/”
],
“allowed_domains”: [
“tech.china.com”
],
“rules”: “china”
}
第一个字段spider即Spider的名称,在这里是universal。后面是站点的描述,比如站点名称、类型、首页等。随后的settings是该Spider特有的settings配置,如果要覆盖全局项目,settings.py内的配置可以单独为其配置。随后是Spider的一些属性,如start_urls、allowed_domains、rules等。rules也可以单独定义成一个rules.py文件,做成配置文件,实现Rule的分离,如下所示:
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import Rule
rules = {
‘china’: (
Rule(LinkExtractor(allow=‘article/.*.html’, restrict_xpaths=‘//div[@id=“left_side”]//div[@class=“con_item”]’),
callback=‘parse_item’),
Rule(LinkExtractor(restrict_xpaths=‘//div[@id=“pageStyle”]//a[contains(., “下一页”)]’))
)
}
这样我们将基本的配置抽取出来。如果要启动爬虫,只需要从该配置文件中读取然后动态加载到Spider中即可。所以我们需要定义一个读取该JSON文件的方法,如下所示:
from os.path import realpath, dirname
import json
def get_config(name):
path = dirname(realpath(__file__)) + ‘/configs/’ + name + ‘.json’
with open(path, ‘r’, encoding=‘utf-8’) as f:
return json.loads(f.read())
定义了get_config()方法之后,我们只需要向其传入JSON配置文件的名称即可获取此JSON配置信息。随后我们定义入口文件run.py,把它放在项目根目录下,它的作用是启动Spider,如下所示:
import sys
from scrapy.utils.project import get_project_settings
from scrapyuniversal.spiders.universal import UniversalSpider
from scrapyuniversal.utils import get_config
from scrapy.crawler import CrawlerProcess
def run():
name = sys.argv[1]
custom_settings = get_config(name)
# 爬取使用的Spider名称
spider = custom_settings.get(‘spider’, ‘universal’)
project_settings = get_project_settings()
settings = dict(project_settings.copy())
# 合并配置
settings.update(custom_settings.get(‘settings’))
process = CrawlerProcess(settings)
# 启动爬虫
process.crawl(spider, **{‘name’: name})
process.start()
if __name__ == ‘__main__’:
run()
运行入口为run()。首先获取命令行的参数并赋值为name,name就是JSON文件的名称,其实就是要爬取的目标网站的名称。我们首先利用get_config()方法,传入该名称读取刚才定义的配置文件。获取爬取使用的spider的名称、配置文件中的settings配置,然后将获取到的settings配置和项目全局的settings配置做了合并。新建一个CrawlerProcess,传入爬取使用的配置。调用crawl()和start()方法即可启动爬取。
在universal中,我们新建一个__init__()方法,进行初始化配置,实现如下所示:
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapyuniversal.utils import get_config
from scrapyuniversal.rules import rules
class UniversalSpider(CrawlSpider):
name = ‘universal’
def __init__(self, name, *args, **kwargs):
config = get_config(name)
self.config = config
self.rules = rules.get(config.get(‘rules’))
self.start_urls = config.get(‘start_urls’)
self.allowed_domains = config.get(‘allowed_domains’)
super(UniversalSpider, self).__init__(*args, **kwargs)
def parse_item(self, response):
i = {}
return i
在__init__()方法中,start_urls、allowed_domains、rules等属性被赋值。其中,rules属性另外读取了rules.py的配置,这样就成功实现爬虫的基础配置。
接下来,执行如下命令运行爬虫:
python3 run.py china
程序会首先读取JSON配置文件,将配置中的一些属性赋值给Spider,然后启动爬取。运行效果完全相同,运行结果如下图所示。

现在我们已经对Spider的基础属性实现了可配置化。剩下的解析部分同样需要实现可配置化,原来的解析函数如下所示:
def parse_item(self, response):
loader = ChinaLoader(item=NewsItem(), response=response)
loader.add_xpath(‘title’, ‘//h1[@id=“chan_newsTitle”]/text()’)
loader.add_value(‘url’, response.url)
loader.add_xpath(‘text’, ‘//div[@id=“chan_newsDetail”]//text()’)
loader.add_xpath(‘datetime’, ‘//div[@id=“chan_newsInfo”]/text()’, re=‘(\d±\d±\d+\s\d+:\d+:\d+)’)
loader.add_xpath(‘source’, ‘//div[@id=“chan_newsInfo”]/text()’, re=‘来源:(.*)’)
loader.add_value(‘website’, ‘中华网’)
yield loader.load_item()
我们需要将这些配置也抽离出来。这里的变量主要有Item Loader类的选用、Item类的选用、Item Loader方法参数的定义,我们可以在JSON文件中添加如下item的配置:
“item”: { “class”: “NewsItem”, “loader”: “ChinaLoader”, “attrs”: { “title”: [ { “method”: “xpath”, “args”: [ “//h1[@id=‘chan_newsTitle’]/text()” ] } ], “url”: [ { “method”: “attr”, “args”: [ “url” ] } ], “text”: [ { “method”: “xpath”, “args”: [ “//div[@id=‘chan_newsDetail’]//text()” ] } ], “datetime”: [ { “method”: “xpath”, “args”: [ “//div[@id=‘chan_newsInfo’]/text()” ], “re”: “(\d±\d±\d+\s\d+:\d+:\d+)” } ], “source”: [ { “method”: “xpath”, “args”: [ “//div[@id=‘chan_newsInfo’]/text()” ], “re”: “来源:(.*)” } ], “website”: [ { “method”: “value”, “args”: [ “中华网” ] } ] }}
这里定义了class和loader属性,它们分别代表Item和Item Loader所使用的类。定义了attrs属性来定义每个字段的提取规则,例如,title定义的每一项都包含一个method属性,它代表使用的提取方法,如xpath即代表调用Item Loader的add_xpath()方法。args即参数,就是add_xpath()的第二个参数,即XPath表达式。针对datetime字段,我们还用了一次正则提取,所以这里还可以定义一个re参数来传递提取时所使用的正则表达式。
我们还要将这些配置之后动态加载到parse_item()方法里。最后,最重要的就是实现parse_item()方法,如下所示:
def parse_item(self, response):
item = self.config.get(‘item’)
if item:
cls = eval(item.get(‘class’))()
loader = eval(item.get(‘loader’))(cls, response=response)
# 动态获取属性配置
for key, value in item.get(‘attrs’).items():
for extractor in value:
if extractor.get(‘method’) == ‘xpath’:
loader.add_xpath(key, *extractor.get(‘args’), **{‘re’: extractor.get(‘re’)})
if extractor.get(‘method’) == ‘css’:
loader.add_css(key, *extractor.get(‘args’), **{‘re’: extractor.get(‘re’)})
if extractor.get(‘method’) == ‘value’:
loader.add_value(key, *extractor.get(‘args’), **{‘re’: extractor.get(‘re’)})
if extractor.get(‘method’) == ‘attr’:
loader.add_value(key, getattr(response, *extractor.get(‘args’)))
yield loader.load_item()
这里首先获取Item的配置信息,然后获取class的配置,将其初始化,初始化Item Loader,遍历Item的各个属性依次进行提取。判断method字段,调用对应的处理方法进行处理。如method为css,就调用Item Loader的add_css()方法进行提取。所有配置动态加载完毕之后,调用load_item()方法将Item提取出来。
重新运行程序,结果如下图所示。

运行结果是完全相同的。
我们再回过头看一下start_urls的配置。这里start_urls只可以配置具体的链接。如果这些链接有100个、1000个,我们总不能将所有的链接全部列出来吧?在某些情况下,start_urls也需要动态配置。我们将start_urls分成两种,一种是直接配置URL列表,一种是调用方法生成,它们分别定义为static和dynamic类型。
本例中的start_urls很明显是static类型的,所以start_urls配置改写如下所示:
“start_urls”: { “type”: “static”, “value”: [ “http://tech.china.com/articles/” ]}
文末有福利领取哦~
👉一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
👉二、Python必备开发工具

👉三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉 四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(文末领读者福利)

👉五、Python练习题
检查学习结果。

👉六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉因篇幅有限,仅展示部分资料,这份完整版的Python全套学习资料已经上传
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

















 2516
2516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









