







Kafka实战笔记
关于这份笔记,为了不影响大家的阅读体验,我只能在文章中展示部分的章节内容和核心截图

- Kafka入门
- 为什么选择Kafka
- Karka的安装、管理和配置

- Kafka的集群
- 第一个Kafka程序

afka的生产者

- Kafka的消费者
- 深入理解Kafka
- 可靠的数据传递


- Spring和Kalka的整合
- Sprinboot和Kafka的整合
- Kafka实战之削峰填谷
- 数据管道和流式处理(了解即可)

- Kafka实战之削峰填谷

-
hashmap在高并发场景下会出现什么问题?(扩容方向思考一下)
-
红黑树特性?
-
红黑树插入操作?
-
红黑树和二叉树各自性能优势的场景?
这里姑且认为红黑树和AVL比较。
AVL平衡二叉搜索树,左右子树深度之差的绝对值不超过1且左右子树仍然为平衡二叉树。
AVL是严格平衡树,因此在增加或者删除节点的时候,根据不同情况,旋转的次数比红黑树要多;红黑是弱平衡的,用非严格的平衡来换取增删节点时候旋转次数的降低;所以简单说,搜索的次数远远大于插入和删除,那么选择AVL树,如果搜索,插入删除次数几乎差不多,应该选择RB树。
- linux命令:杀死所有名字带有java的进程,命令怎么写?
ps -ef | grep java
kill掉相应的进程号
- mysql:select * from xxx where name = xxxxx,name是非唯一索引,说一下内部具体执行过程?
这里要注意非聚集索引和聚集索引的区别,我把B+树中查找子节点数据的过程模拟讲了一遍。
-
Redis 持久化方案?
-
Redis 底层有哪些数据结构?
-
TCP和UDP的区别
-
HTTP使用的是TCP还是UDP?长连接还是短连接?
HTTP使用的是TCP,在HTTP/1.0中默认使用短连接,从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加入Connection:keep-alive
- 介绍下HTTP的缓存?
HTTP缓存有多种规则,根据是否需要重新向服务器发起请求来分类,将其分为两大类(强制缓存,对比缓存)。


对比缓存,需要进行比较判断是否可以使用缓存:
浏览器第一次请求数据时,服务器会将缓存标识与数据一起返回给客户端,客户端将二者备份至缓存数据库中。
再次请求数据时,客户端将备份的缓存标识发送给服务器,服务器根据缓存标识进行判断,判断成功后,返回304状态码,通知客户端比较成功,可以使用缓存数据。
- 设计模式–迭代器模式
2021年3月11日补充:
没错,我又面试阿里了,这次还是有几个题让我印象深刻,整理一下:
- 介绍一下ForkJoinPool
通常大家说的Fork/Join框架其实就是指由ForkJoinPool作为线程池、ForkJoinTask(通常实现其三个抽象子类)为任务、ForkJoinWorkerThread作为执行任务的具体线程实体这三者构成的任务调度机制。
ForkJoinPool充分利用多cpu的优势,把一个任务拆分成多个“小任务”,把多个“小任务”放到多个处理器上并行执行;当多个“小任务”执行完成之后,再将这些执行结果合并起来。感觉有点像二分法。
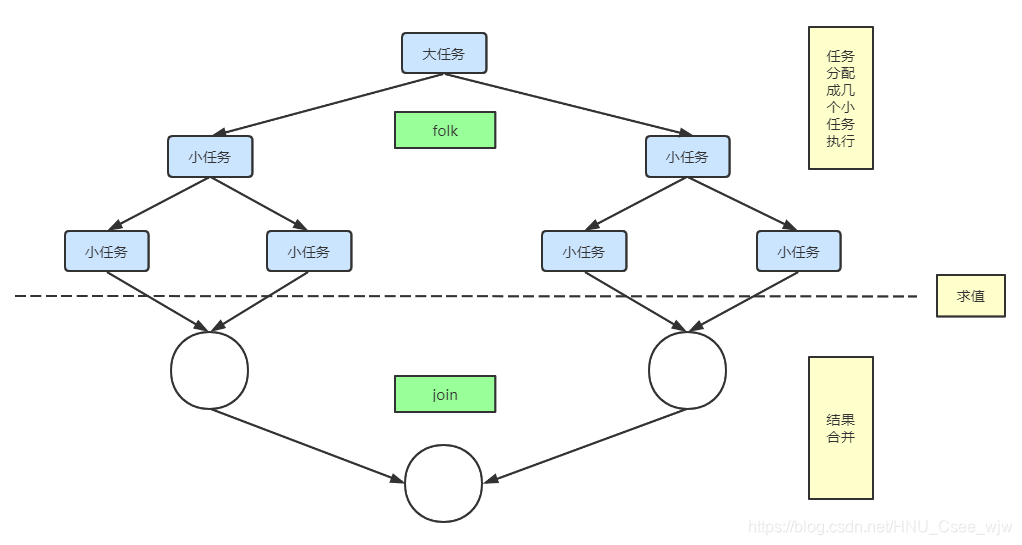
ForkJoinPool 的工作特点是work stealing,ForkJoinPool底层维护着一个双端队列,当一个线程的任务队列执行完毕后,其他线程的任务队列还没有执行完毕,这时,已经执行完毕的线程就会到另一个线程的双端任务队列的尾部去偷取任务执行。
-
ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。
-
每个工作线程在运行中产生新的任务(通常是因为调用了 fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。
-
每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务(或是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。
-
在遇到 join() 时,如果其他需要 join 的任务尚未完成,则会先处理其他任务,并等待其完成。
-
在既没有自己的任务,也没有可以窃取的任务时,进入休眠。
-
Spring Boot 打成的 jar 和普通的 jar
Spring Boot 项目最终打包成的 jar 是可执行 jar ,这种 jar 可以直接通过 java -jar xxx.jar 命令来运行,这种 jar 不可以作为普通的 jar 被其他项目依赖,即使依赖了也无法使用其中的类。
Spring Boot 的 jar 无法被其他项目依赖,主要还是他和普通 jar 的结构不同。普通的 jar 包,解压后直接就是包名,包里就是我们的代码,而 Spring Boot 打包成的可执行 jar 解压后,在 \BOOT-INF\classes 目录下才是我们的代码,因此无法被直接引用。
- Java8的函数式编程(Stream流)
https://blog.csdn.net/mu_wind/article/details/109516995
- BeanFactory和ApplicationContext的区别
BeanFactory:
是Spring里面最底层的接口,提供了最简单的容器的功能,只提供了实例化对象和拿对象的功能。
ApplicationContext:
应用上下文,继承BeanFactory接口,它是Spring的一各更高级的容器,提供了更多的有用的功能;
写在最后
作为一名即将求职的程序员,面对一个可能跟近些年非常不同的 2019 年,你的就业机会和风口会出现在哪里?在这种新环境下,工作应该选择大厂还是小公司?已有几年工作经验的老兵,又应该如何保持和提升自身竞争力,转被动为主动?
就目前大环境来看,跳槽成功的难度比往年高很多。一个明显的感受:今年的面试,无论一面还是二面,都很考验Java程序员的技术功底。
最近我整理了一份复习用的面试题及面试高频的考点题及技术点梳理成一份“Java经典面试问题(含答案解析).pdf和一份网上搜集的“Java程序员面试笔试真题库.pdf”(实际上比预期多花了不少精力),包含分布式架构、高可扩展、高性能、高并发、Jvm性能调优、Spring,MyBatis,Nginx源码分析,Redis,ActiveMQ、Mycat、Netty、Kafka、Mysql、Zookeeper、Tomcat、Docker、Dubbo、Nginx等多个知识点高级进阶干货!
由于篇幅有限,为了方便大家观看,这里以图片的形式给大家展示部分的目录和答案截图!

Java经典面试问题(含答案解析)

阿里巴巴技术笔试心得

(img-hwPBAhoz-1715684566836)]















 638
638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









