







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
export PATH= J A V A _ H O M E / b i n : {JAVA\_HOME}/bin: JAVA_HOME/bin:PATH
* 保存退出.bashrc,使用`source ~/.bashrc`让我们刚刚的配置生效。使用`java -version`查看是否配置java成功

## 二、 安装Hadoop伪分布式
`Hadoop下载地址:https://dlcdn.apache.org/hadoop/common/,我下的是hadoop-3.3.6.tar.gz 696M的那个`
1. 使用tar命令解压Hadoop包到/usr/local目录

2. 使用chown修改Hadoop权限,查看相关版本信息
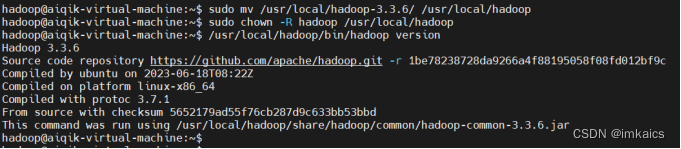
3. 修改配置文件 `/usr/local/hadoop(这个hadoop是我们解压后重命名的文件夹名)/etc/hadoop/`目录下
* core-site.xml
* hdfs-site.xml
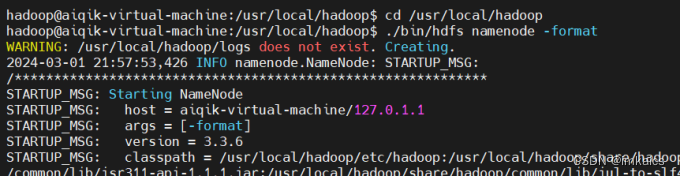
4. 格式化NameNode名称节点
cd /usr/local/hadoop
./bin/hdfs namenode -format
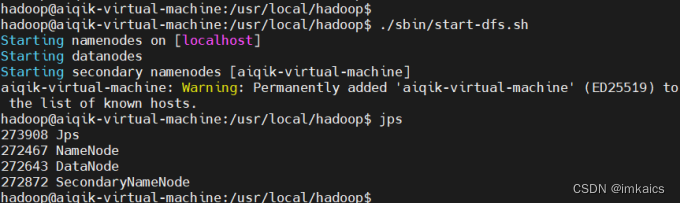
5. 启动Hadoop,开启守护进程,通过JPS查看进程数目应该是4个
cd /usr/local/hadoop
./sbin/start-dfs.sh
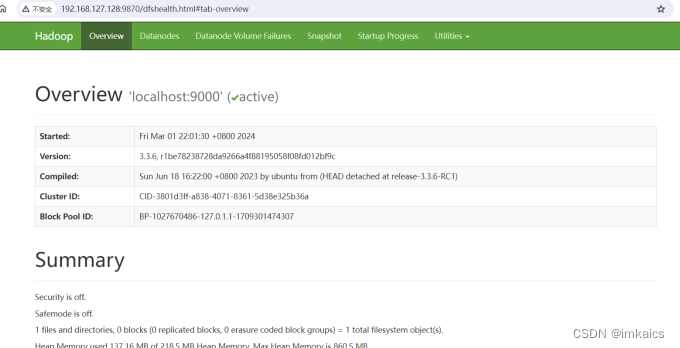
6. 浏览器查看localhost:9870(或者ip:9870)
## 三、安装Spark Local模式
`下载地址:https://archive.apache.org/dist/spark/,我这里下的是spark-3.4.2-bin-without-hadoop.tgz`
1. 使用tar命令解压spark包到/usr/local目录

2. 修改解压后的文件夹为spark,并修改内容所有者和所属组为hadoop

3. 修改./conf/spark-env.sh配置文件(需要使用cp复制模板文件再进行修改)
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh

export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)

4. 看spark是否安装成功
cd /usr/local/spark
bin/run-example SparkPi 2>&1 | grep “Pi is”
虽然结果可能不一定是3.14……



**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**















 1796
1796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









