








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
之前为团队里的小伙伴做了 Flink 与阿里云 Realtime Compute 的技术分享,今天有时间就把PPT的内容做了整理分享给大家 (多图预警)🙄。
前言

Flink 最早期起源于德国柏林工业大学的一个研究项目Stratosphere,直到 2014年4月 捐献给Apache软件基金会…
要知道,在2015年的时候,Filnk几乎没有人知道,更没有人大规模使用它 😭。

而阿里是全球第一批使用Flink做大数据计算引擎研发的公司,2015年就引入内部,但最早Flink只能支持小流量互联网场景的数据处理。阿里觉得Flink很有潜力,决定进行改造,并把这个内部版本取名Blink,是英文眨眼的意思:“一眨眼,所有东西都计算好了!
在2017年双11,Blink就已成功支持全集团(阿里巴巴、阿里云、菜鸟)所有交易数据的实时计算任务,也验证了Flink可以通过改造支持企业大规模数据计算的场景 😍。
目前,国内诸多互联网大厂都已经完全拥抱了Flink。本次的分享就是围绕实时计算Flink和Alibaba Cloud Realtime Compute相关的知识点(能力、限制、典型场景,区别)进行分析。
什么是 Apache Flink?

如果用一句话聊聊什么是 Apache Flink 的命脉?
那我的答案可能是:Apache Flink 是以"批是流的特例"的认知进行系统设计的。
就目前最热的两种流计算引擎 Apache Spark 和 Apache Flink 而言,谁最终会成为No1呢?
单从 “低延时” 的角度看,Spark是Micro Batching(微批式)模式,延迟Spark能达到0.5~2秒左右,Flink是Native Streaming(纯流式)模式,延时能达到微秒。
很显然是相对较晚出道的 Apache Flink 后来者居上。 那么为什么Apache Flink能做到如此之 "快"呢?根本原因是 Apache Flink 设计之初就认为 “批是流的特例”,整个系统是 Native Streaming 设计,每来一条数据都能够触发计算。相对于需要靠时间来积攒数据 Micro Batching 模式来说,在架构上就已经占据了绝对优势。
那么为什么关于流计算会有两种计算模式呢?
归其根本是因为对流计算的认知不同,是"流是批的特例" 和 “批是流的特例” 两种不同认知产物。

首先,我觉得 Flink 应用开发需要先理解 Flink 的 Streams、State、Time 等基础处理语义以及 Flink 兼顾灵活性和方便性的多层次API。

Streams:流,分为有限数据流与无限数据流,unbounded stream 是有始无终的数据流,即无限数据流;而bounded stream 是限定大小的有始有终的数据集合,即有限数据流,二者的区别在于无限数据流的数据会随时间的推演而持续增加,计算持续进行且不存在结束的状态,相对的有限数据流数据大小固定,计算最终会完成并处于结束的状态。
在 Spark 的世界观中,一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个一个无限的小批次组成的。
而在 Flink 的世界观中,一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。

State:状态是计算过程中的数据信息,在容错恢复和 Checkpoint 中有重要的作用,流计算在本质上是Incremental Processing(增量处理),因此需要不断查询保持状态;另外,为了确保Exactly- once 语义,需要数据能够写入到状态中;而持久化存储,能够保证在整个分布式系统运行失败或者挂掉的情况下做到Exactly- once,这是状态的另外一个价值。
流式计算分为无状态和有状态两种情况。无状态的计算观察每个独立事件,并根据最后一个事件输出结果。- 例如,流处理应用程序从传感器接收温度读数,并在温度超过 90 度时发出警告。
有状态的计算则会基于多个事件输出结果。以下是一些例子:
- 所有类型的窗口。例如,计算过去一小时的平均温度,就是有状态的计算
- 所有用于复杂事件处理的状态机。例如,若在一分钟内收到两个相差 20 度以上的温度读数,则发出警告,这是有状态的计算
- 流与流之间的所有关联操作,以及流与静态表或动态表之间的关联操作,都是有状态的计算

Time,分为Event time、Ingestion time、Processing time,Flink 的无限数据流是一个持续的过程,时间是我们判断业务状态是否滞后,数据处理是否及时的重要依据。

EventTime,因为我们要根据日志的生成时间进行统计。
- 在不同的语义时间有不同的应用场景
- 我们往往更关心事件时间 EventTime

API 通常分为三层,由上而下可分为SQL / Table API、DataStream API、ProcessFunction 三层,API 的表达能力及业务抽象能力都非常强大,但越接近SQL 层,表达能力会逐步减弱,抽象能力会增强,反之,ProcessFunction 层API 的表达能力非常强,可以进行多种灵活方便的操作,但抽象能力也相对越小。
实际上,大多数应用并不需要上述的底层抽象,而是针对核心 API(Core APIs) 进行编程,比如 DataStream API(有界或无界流数据)以及 DataSet API(有界数据集)。这些 API 为数据处理提供了通用的构建模块,比如由用户定义的多种形式的转换(transformations),连接(joins),聚合(aggregations),窗口操作(windows)等等。DataSet API 为有界数据集提供了额外的支持,例如循环与迭代。这些 API处理的数据类型以类(classes)的形式由各自的编程语言所表示。

- 第一:Flink 具备统一的框架处理有界和无界两种数据流的能力。
- 第二:部署灵活,Flink 底层支持多种资源调度器,包括 Yarn、Kubernetes 等。Flink 自身带的 Standalone 的调度器,在部署上也十分灵活。
- 第三:极高的可伸缩性,可伸缩性对于分布式系统十分重要,阿里巴巴双 11 大屏采用 Flink 处理海量数据,使用过程中测得 Flink 峰值可达 17 亿 / 秒。
- 第四:极致的流式处理性能。Flink 相对于 Storm 最大的特点是将状态语义完全抽象到框架中,支持本地状态读取,避免了大量网络 IO,可以极大提升状态存取的性能。

接下来聊聊 Flink 常见的三种应用场景 :

- 实时数仓
当下游要构建实时数仓时,上游则可能需要实时的Stream ETL。这个过程会进行实时清洗或扩展数据,清洗完成后写入到下游的实时数仓的整个链路中,可保证数据查询的时效性,形成实时数据采集、实时数据处理以及下游的实时Query。
- 搜索引擎推荐
搜索引擎这块以淘宝为例,当卖家上线新商品时,后台会实时产生消息流,该消息流经过Flink 系统时会进行数据的处理、扩展。然后将处理及扩展后的数据生成实时索引,写入到搜索引擎中。这样当淘宝卖家上线新商品时,能在秒级或者分钟级实现搜索引擎的搜索。

- 移动应用中的用户行为分析
- 消费者技术中的实时数据即席查询

在触发某些规则后,Data Driven 会进行处理或者是进行预警,这些预警会发到下游产生业务通知,这是Data Driven 的应用场景,Data Driven 在应用上更多应用于复杂事件的处理。
- 实时推荐(例如在客户浏览商家页面的同时进行商品推荐)
- 模式识别或复杂事件处理(例如根据信用卡交易记录进行欺诈识别)
- 异常检测(例如计算机网络入侵检测)
接下来就该讲讲 Apache Flink 的几点优势:



Flink作为分布式的处理引擎,在分布式的场景下,进行多个本地状态的运算,只产生一个全域一致的快照,如需要在不中断运算值的前提下产生全域一致的快照,就涉及到分散式状态容错。


如果项链上有很多珠子,大家显然不想从头再数一遍,尤其是当三人的速度不一样却又试图合作的时候,更是如此(比如想记录前一分钟三人一共数了多少颗珠子,回想一下一分钟滚动窗口。
于是,我们可以想一个比较好的办法: 在项链上每隔一段就松松地系上一根有色皮筋,将珠子分隔开; 当珠子被拨动的时候,皮筋也可以被拨动; 然后,你安排一个助手,让他在你和朋友拨到皮筋时记录总数。用这种方法,当有人数错时,就不必从头开始数。相反,你向其他人发出错误警示,然后你们都从上一根皮筋处开始重数,助手则会告诉每个人重数时的起始数值。
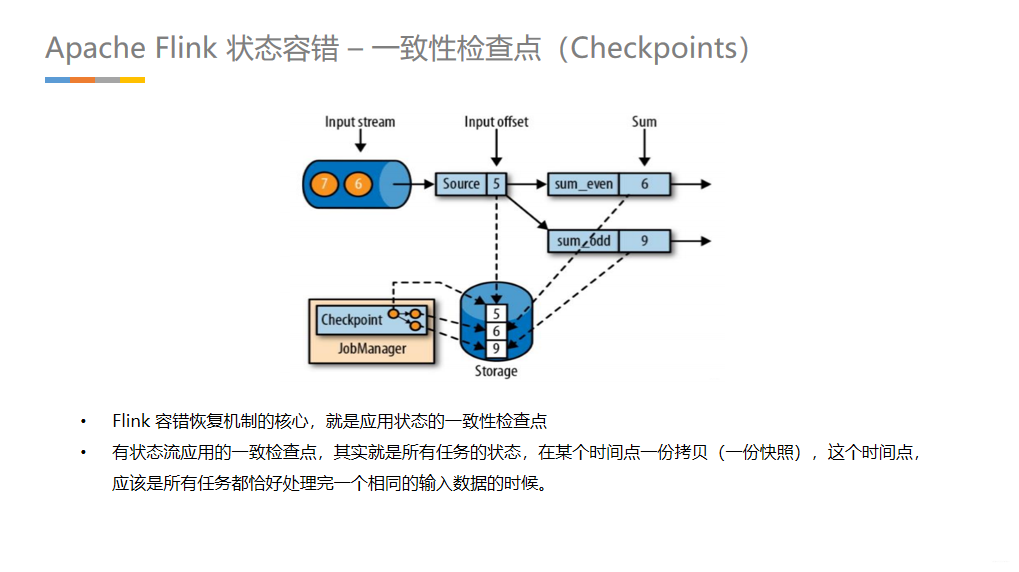
在执行流应用程序期间,Flink会定期保存状态的一致检查点
如果发生故障,Flink将会使用最近的检查点来一致恢复应用程序的状态,并重新启动处理流程遇到故障后
- 第一步就是重新启动
- 第二步是从 checkpoint 中读取状态,将状态重置
从检查点重新启动应用程序后,其内部状态与检查点完成时的状态完全相同 - 第三步:开始消费并处理检查点到发生故障之间的所有数据
这种检查点的保存和恢复机制可以为应用程序提供“精确一次”(exactly-once)的一致性,因为所有的算子都会保存检查点并恢复其所有的状态,这样一来所有的输入流就都会被重置到检查点完成时的位置 - 一种简单的想法
暂停应用,保存状态到检查点,再重新恢复应用 - Flink 的改进实现
基于Chandy-Lamport 算法的分布式快照
将检查点的保存和数据处理分离开,不暂停整个应用

检查点分界线(Checkpoint Barrier)
- Flink 的检查点算法用到了一种称为分界线(barrier)的特殊形式,用来吧一条流上数据按照不同的检查点分开
- 分界线之前来的数据导致的状态更改,都会被包含在当前分界线所属的检查点中;而基于分界线之后的数据导致的所有更改,就会被包含在之后的检查点中
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1967
1967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









