







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
排序:
s.sort(Client,-Amount)
去重:
s.id(Client)
分组汇总:
s.groups(year(OrderDate);sum(Amount))
关联:
join(T ("D:/data/Orders.csv"):O,SellerId; T("D:/data/Employees.txt"):E,EId)
TopN:
s.top(-3;Amount)
组内 TopN:
s.groups(Client;top(3,Amount))
更不规则的文本,通常无法直接解析成结构化数据,SPL 提供了灵活的函数语法,只要简单处理就能够获得理想数据。比如文件每三行对应一条记录,其中第二行含多个字段,将该文件整理成结构化数据,并按第 3 和第 4 个字段排序:
| A | |
|---|---|
| 1 | =file(“D:\data.txt”).import@si() |
| 2 | =A1.group((#-1)\3) |
| 3 | =A2.new(~(1):OrderID, (line=(2).array(“\t”))(1):Client,line(2):SellerId,line(3):Amount,(3):OrderDate ) |
| 4 | =A3.sort(_3,_4) |
SPL 还提供了符合SQL92 标准的语法,包括集合计算、case when、with、嵌套子查询等。比如分组汇总可以写作:
$select year(OrderDate),sum(Amount) from D:/data/Orders.txt group by year(OrderDate)
json\xml
SPL 不仅支持二维结构的文本,还可以方便地处理 json\xml 这样的多层结构数据,自由访问不同层级,并用统一的代码进行计算。
专业的多层结构数据对象。SPL 可以方便地表达 json\xml 的层级结构。比如,从文件读取多层 json 串并解析:
| A | |
|---|---|
| 1 | =file(“d:\xml\emp_orders.json”).read() |
| 2 | =json(A1) |
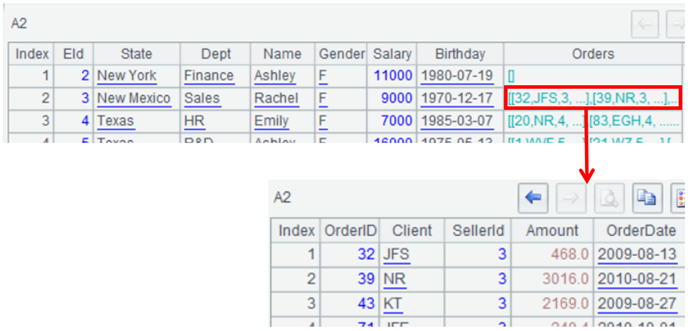
可以看到多层结构:
xml也是类似:
| A | |
|---|---|
| 1 | =file(“d:\xml\emp_orders.xml”).read() |
| 2 | =xml(A1,“xml/row”) |
| 访问多层结构数据。可以通过点号访问不同的层级,通过下标访问不同的位置。 |
Client 字段构成的集合:
A2.(Client)
第 10 条记录的 Orders 字段(所含的二维表):
A2(10).Orders
第 10 条件记录的 Orders 字段下的第 5 条记录:
(A2(10).Orders)(5)
计算多层数据。SPL 可以用统一的代码计算二维结构数据和多层结构数据:
| A | |
|---|---|
| 3 | =A2.conj(Orders).groups(year(OrderDate);sum(Amount)) |
| 4 | =A2(10).Orders.select(Amount>1000 && Amount<=3000 && like(Client,“s”)) |
网络多层结构数据。除了 json\xml 这样的本地文件,SPL 也支持 WebSerivce 和 Restful 这类网络服务上的多层结构数据。比如,从 Restful 取多层 json,进行条件查询:
| A | |
|---|---|
| 1 | =httpfile(“http://127.0.0.1:6868/restful/emp_orders”).read() |
| 2 | =json(A1) |
| 3 | =A2.conj(Orders) |
| 4 | =A3.select(Amount>1000 && Amount<=2000 && like@c(Client,“business”)) |
| 很多特殊数据源也是多层结构数据,常见的比如 MongoDB、ElasticSearch、SalesForce,SPL 可直接从这些数据源取数并计算。 |
xls
SPL 对 POI 进行了高度封装,可以轻松读写格式规则或不规则的 xls,并用 SPL 函数和语法统一进行计算。
格式规则的行式 xls,仍然用 T 函数读取:
=T("d:\\Orders.xls")
后继的计算也和文本类似。
生成格式规则的行式 xls,可以用 xlsexport 函数。比如,将 A1 写入新 xls 的第一个 sheet,首行为列名,只要一句代码:
=file("e:/result.xlsx").xlsexport@t(A1)
xlsexport 函数的功能丰富多样,可以将序表写入指定 sheet,或只写入序表的部分行,或只写入指定的列:
=file("e:/scores.xlsx").xlsexport@t(A1,No,Name,Class,Maths)
xlsexport 函数还可以方便地追加数据,比如对于已经存在且有数据的 xls,将序表 A1 追加到该文件末尾,外观风格与原文件末行保持一致:
=file("e:/scores.xlsx").xlsexport@a(A1)
格式较不规则的行式 xls,可使用 xlsimport 函数读取,功能丰富而简洁。
没有列名,首行直接是数据:
file("D:\\Orders.xlsx").xlsimport()
跳过前 2 行的标题区:
file("D:/Orders.xlsx").xlsimport@t(;,3)
从第 3 行读到第 10 行:
file("D:/Orders.xlsx").xlsimport@t(;,3:10)
只读取其中 3 个列:
file("D:/Orders.xlsx").xlsimport@t(OrderID,Amount,OrderDate)
读取名为 “sales” 的特定 sheet:
file("D:/Orders.xlsx").xlsimport@t(;"sales")
函数 xlsimport 还具有读取倒数 N 行、密码打开文件、读大文件等功能,这里不再详述。
格式自由的 xls。SPL 提供了 xlscell 函数,可以读写指定 sheet 里指定片区的数据,比如读取第 1 个 sheet 里的 A2 格:
=file("d:/Orders.xlsx").xlsopen().xlscell("C2")
配合 SPL 灵活的语法,就可以解析自由格式的 xls,比如将下面的文件读为规范的二维表(序表):
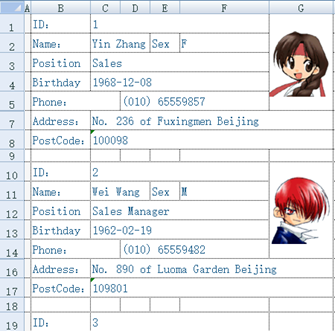
这个文件格式很不规则,直接基于 POI 写 JAVA 代码是个浩大的工程,而 SPL 代码就简短得多:
| A | B | C | |
| 1 | =create(ID,Name,Sex,Position,Birthday,Phone,Address,PostCode) | ||
| 2 | =file(“e:/excel/employe.xlsx”).xlsopen() | ||
| 3 | [C,C,F,C,C,D,C,C] | [1,2,2,3,4,5,7,8] | |
| 4 | for | =A3.(/B3(#)).(A2.xlscell()) | |
| 5 | if len(B4(1))==0 | break | |
| 6 | >A1.record(B4) | ||
| 7 | >B3=B3.(~+9) |
不规则片区写入数据,同样使用 xlscell 函数。比如,xls 中蓝色单元格是不规则的表头,需要在相应的白色单元格中填入数据,如下图:
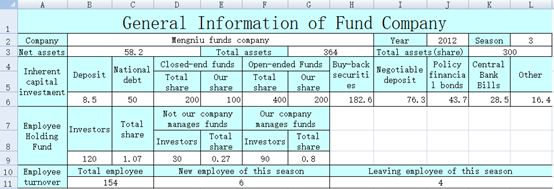
直接用 POI 要大段冗长的代码,而 SPL 代码就简短许多:
| A | B | C | D | E | F | |
| 1 | Mengniu Funds | 2017 | 3 | 58.2 | 364 | 300 |
| 2 | 8.5 | 50 | 200 | 100 | 400 | 200 |
| 3 | 182.6 | 76.3 | 43.7 | 28.5 | 16.4 | |
| 4 | 120 | 1.07 | 30 | 0.27 | 90 | 0.8 |
| 5 | 154 | 6 | 4 | |||
| 6 | =file(“e:/result.xlsx”) | =A6.xlsopen() | ||||
| 7 | =C6.xlscell(“B2”,1;A1) | =C6.xlscell(“J2”,1;B1) | =C6.xlscell(“L2”,1;C1) | |||
| 8 | =C6.xlscell(“B3”,1;D1) | =C6.xlscell(“G3”,1;E1) | =C6.xlscell(“K3”,1;F1) | |||
| 9 | =C6.xlscell(“B6”,1;[A2:F2].concat(“\t”)) | =C6.xlscell(“H6”,1;[A3:E3].concat(“\t”)) | ||||
| 10 | =C6.xlscell(“B9”,1;[A4:F4].concat(“\t”)) | =C6.xlscell(“B11”,1;[A5:C5].concat(“\t”)) | ||||
| 11 | =A6.xlswrite(B6) |
上面第 6、9、11 行有连续单元格,SPL 可以简化代码一起填入,POI 只能依次填入。
更强的计算能力
SPL 有更丰富的日期和字符串函数、更方便的语法,能有效简化 SQL 和存储过程难以实现的复杂计算。
更丰富的日期和字符串函数。除了常见的日期增减、截取字符串等函数,SPL 还提供了更丰富的日期和字符串函数,在数量和功能上远远超过了 SQL:
季度增减:
elapse@q("2020-02-27",-3) //返回2019-05-27
N 个工作日之后的日期:
workday(date("2022-01-01"),25) //返回2022-02-04
字符串类函数,判断是否全为数字:
isdigit("12345") //返回true
取子串前面的字符串:
substr@l("abCDcdef","cd") //返回abCD
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
(“abCDcdef”,“cd”) //返回abCD
[外链图片转存中...(img-zUXxu9gY-1715459563716)]
[外链图片转存中...(img-TrM5slSP-1715459563716)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1314
1314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









