








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
ElasticSearch高效数据统计
聚合查询
① 什么是聚合查询
聚合是ES除搜索功能外提供的针对ES数据做统计分析的功能,聚合有助于根据搜索查询提供聚合数据,聚合查询是数据库中重要额功能特性,ES作为搜索引擎兼数据库,同样提供了强大的聚合分析功能力,它是基于查询条件来对数据进行分桶、计算的方法,这种很类似与SQL 中的group by 再加上一些函数方法的操作。
在了解聚合查询之前需要注意的一点是:text类型是不支持聚合的,主要是因为text类型本身是分词的,通俗的说,如果一句话分成了多个词然后进行group by操作,那么问题就出现了,到底对哪一个词进行group by操作呢?无法指定!
② Kibana 命令测试聚合查询
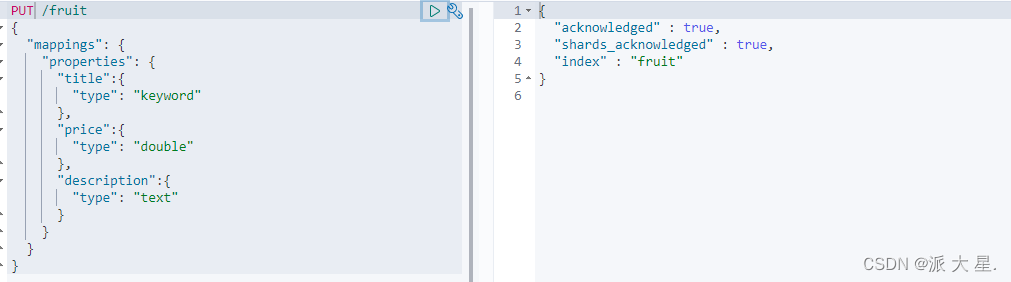
创建测试索引
PUT /fruit
{
"mappings":{
"properties":{
"title":"keyword"
},
"price":{
"type":"double"
},
"description":{
"type":"text"
}
}
}
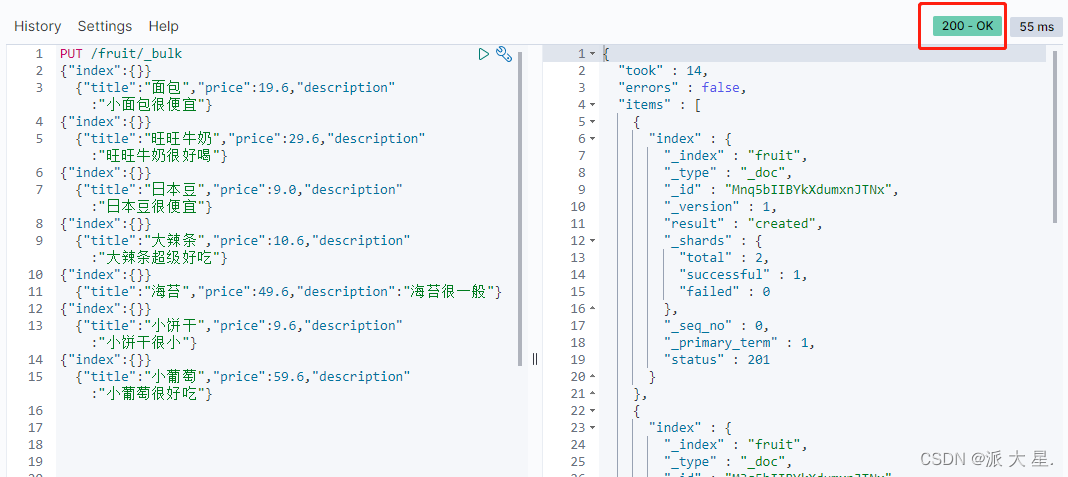
存放测试数据
PUT /fruit/_bulk
{"index":{}}
{"title":"面包","price":19.6,"description":"小面包很便宜"}
{"index":{}}
{"title":"旺旺牛奶","price":29.6,"description":"旺旺牛奶很好喝"}
{"index":{}}
{"title":"日本豆","price":9.0,"description":"日本豆很便宜"}
{"index":{}}
{"title":"大辣条","price":10.6,"description":"大辣条超级好吃"}
{"index":{}}
{"title":"海苔","price":49.6,"description":"海苔很一般"}
{"index":{}}
{"title":"小饼干","price":9.6,"description":"小饼干很小"}
{"index":{}}
{"title":"小葡萄","price":59.6,"description":"小葡萄很好吃"}
{"index":{}}
{"title":"小饼干","price":19.6,"description":"小饼干很小"}
{"index":{}}
{"title":"小饼干","price":59.6,"description":"小饼干很小"}
{"index":{}}
{"title":"小饼干","price":29.6,"description":"小饼干很小"}
{"index":{}}
{"title":"小饼干","price":39.6,"description":"小饼干很小"}
③ 聚合操作使用
根据某个字段分组
GET /fruit/_search
{
"query": {
"match\_all": {
}
},
"aggs": {
"price\_group": {
"terms": {
"field": "price"
}
}
}
}

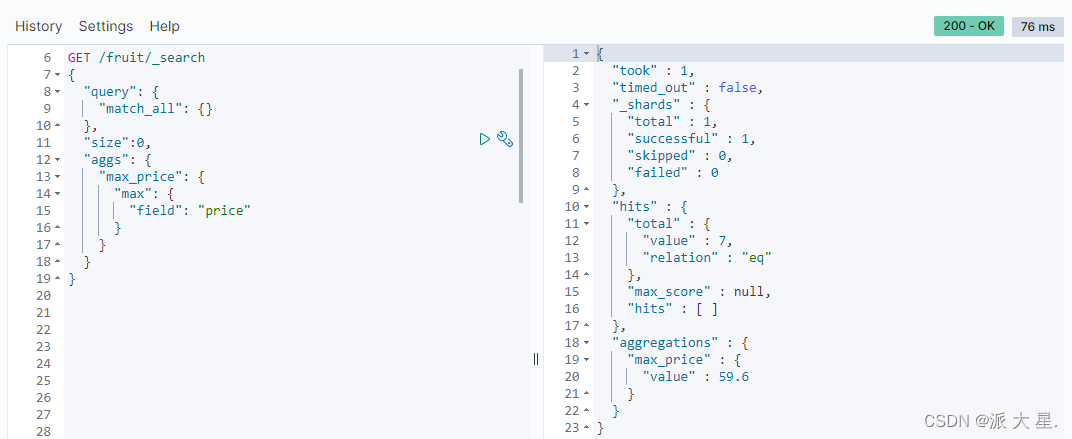
求最大值
GET /fruit/_search
{
"query": {
"match\_all": {}
},
"aggs": {
"max\_price": {
"max": {
"field": "price"
}
}
}
}
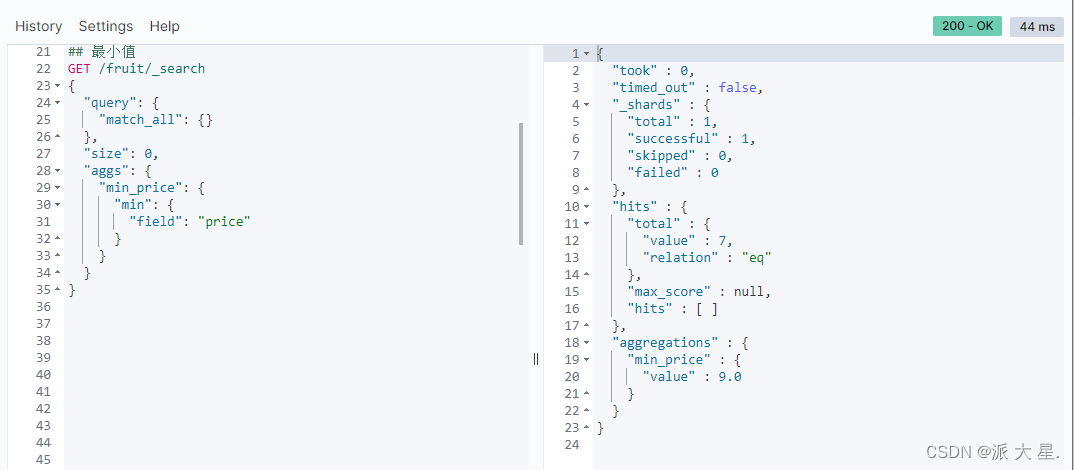
最小值
GET /fruit/_search
{
"query": {
"match\_all": {}
},
"size": 0,
"aggs": {
"min\_price": {
"min": {
"field": "price"
}
}
}
}
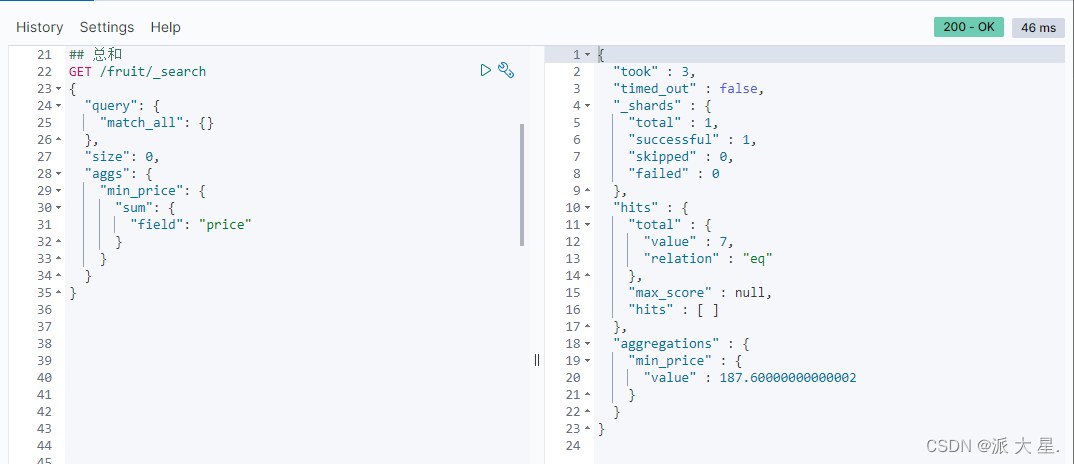
求总数
GET /fruit/_search
{
"query": {
"match\_all": {}
},
"size": 0,
"aggs": {
"min\_price": {
"sum": {
"field": "price"
}
}
}
}
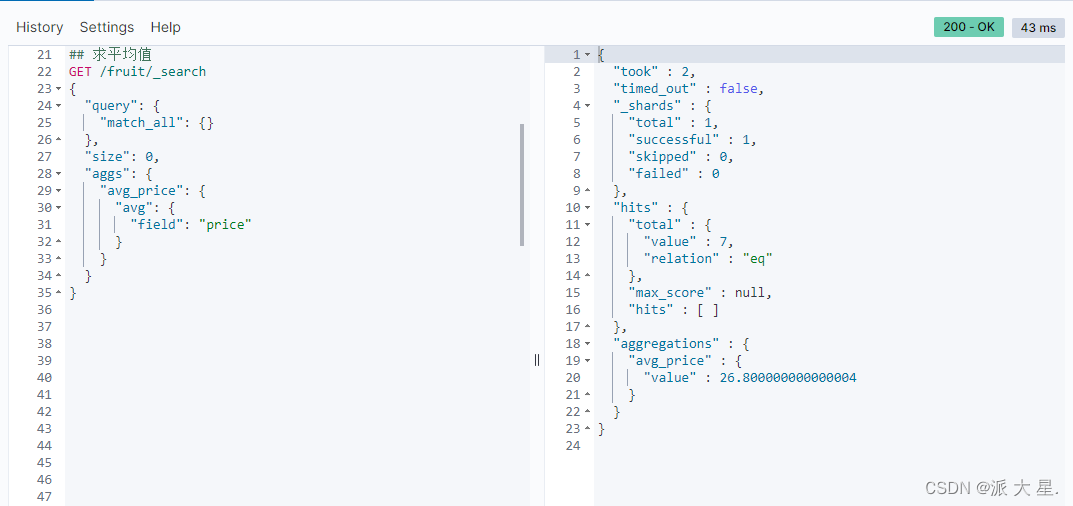
求平均值
GET /fruit/_search
{
"query": {
"match\_all": {}
},
"size": 0,
"aggs": {
"avg\_price": {
"avg": {
"field": "price"
}
}
}
}
④ RestHighLevelClient 测试聚合查询
在使用Java API实现上述操作之前,有必要先了解一下实现过程中使用到的某些方法以及工具
常见的聚合查询:
- 统计某个字段的数量
ValueCountBuilder vcb= AggregationBuilders.count(“分组的名称”).field(“字段”);
- 去重统计某个字段的数量(有少量的误差)
CardinalityBuilder cb= AggregationBuilders.cardinality(“分组的名称”).field(“字段”);
- 聚合过滤
FilterAggregationBuilder fab= AggregationBuilders.filter(“分组的名称”).filter(QueryBuilders.queryStringQuery(“字段:过滤值”));
- 按某个字段分组
TermsBuilder tb= AggregationBuilders.terms(“分组的名称”).field(“字段”);
- 求最大值
SumBuilder sumBuilder= AggregationBuilders.max(“分组的名称”).field(“字段”);
- 求最小值
AvgBuilder ab= AggregationBuilders.min(“分组的名称”).field(“字段”);
- 求平均值
MaxBuilder mb= AggregationBuilders.avg(“分组的名称”).field(“字段”);
- 按日期间隔分组
DateHistogramBuilder dhb= AggregationBuilders.dateHistogram(“分组的名称”).field(“字段”);
- 获取聚合里面的结果
TopHitsBuilder thb= AggregationBuilders.topHits(“分组的名称”);
- 嵌套的聚合
NestedBuilder nb= AggregationBuilders.nested(“分组的名称”).path(“字段”);
- 反转嵌套
AggregationBuilders.reverseNested(“分组的名称”).path("字段 ");
使用Java API实现上述在Kibana中的各项操作
根据某个字段分组


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Kibana`中的各项操作
根据某个字段分组
[外链图片转存中…(img-FcMdp2qs-1715347880223)]
[外链图片转存中…(img-jDymGz2q-1715347880224)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









