







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
| 过载处理 | 任务队列机制,单个机器上可调度的任务数量可以灵活配置,当任务过多时会缓存在任务队列中,不会造成机器卡死 | 暂无 |
| DAG监控界面 | 任务状态、任务类型、重试次数、任务运行机器、可视化变量等关键信息一目了然 | 支持简单的子任务和任务依赖,不支持完整的DAG任务 |
| 可视化流程定义 | 是,所有流程定义操作都是可视化的,通过拖拽任务来绘制DAG,配置数据源及资源。同时对于第三方系统,提供api方式的操作。 | 支持简单的指定子任务 |
| 监控告警 | 支持 | 支持 |
| 是否能暂停和恢复 | 支持暂停,恢复操作 | 不支持 |
| 是否支持多租户 | 支持,easyscheduler上的用户可以通过租户和hadoop用户实现多对一或一对一的映射关系,这对大数据作业的调度是非常重要的。 | 不支持 |
| 日志可追溯 | 实现每个任务实例生成一个日志文件,以/流程定义id/流程实例id/任务实例id.log的形式生成日志 | 支持日志查看,同时支持jstack和gc log备份到executor日志目录(executor版本大于3.0.0) |
| 任务类型 | Shell,MR,Spark,Flink,SQL(mysql,postgresql,hive,sparksql,clickhouse等),DataX,Sqoop,Python,Sub_Process,Procedure | 支持以GLUE模式开发和运行脚本任务,包括Shell、Python、NodeJS、PHP、PowerShell等类型脚本 |
| 与大数据契合度 | 支持大数据作业spark,hive,mr的调度,同时由于支持多租户,与大数据业务更加契合 | 不大行 |
| 是否支持集群扩展 | 是,调度器使用分布式调度,整体的调度能力会随便集群的规模线性增长,Master和Worker支持动态上下线 | 是 |
| 部署运维 | 简单,一键部署,支持k8s | 简单,只需要部署多个Java服务,有官方实时提供的docker镜像 |
| GitHub上star数 | 4.7k | 16.3k |
| 2020 年度 OSC 中国开源项目评选 | 675 | 637 |
| License | Apache License 2.0 | GNU General Public License v3.0 |
| 文档 | 完善 | 完善 |
| 社区 | 活跃,更新快 | 活跃,更新快 |
| 开源时间 | 2019.9 | 2015.12 |
| 开源组织 | 易观开源,Apache | 大众点评 |
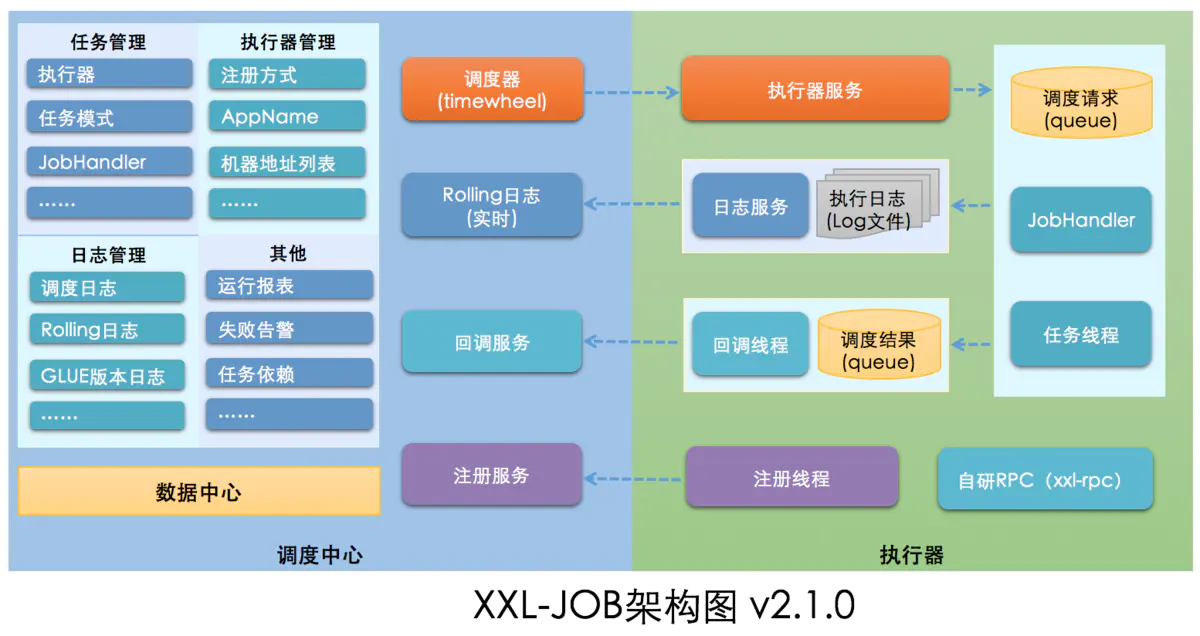
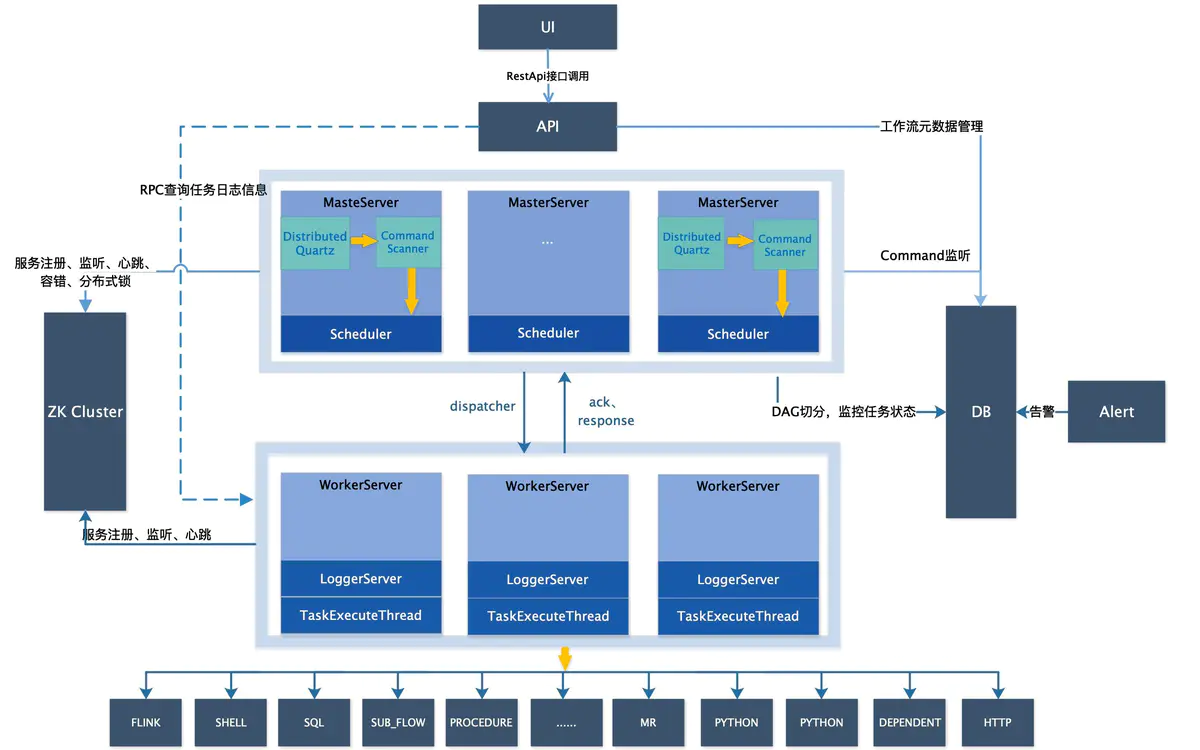
架构图
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 9890
9890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









