








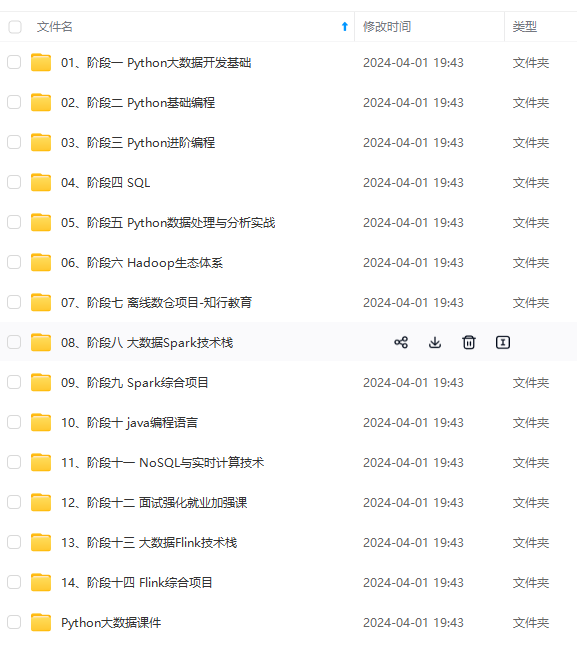
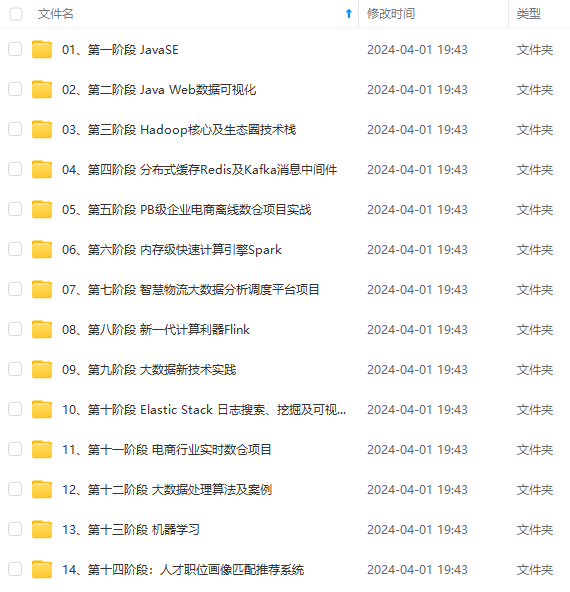
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
文章目录
1、数据说明
(1)数据格式
id course
1,a
1,b
1,c
1,e
2,a
2,c
2,d
2,f
3,a
3,b
3,c
3,e
(2)字段含义
表示有id为1,2,3的学生选修了课程a,b,c,d,e,f中其中几门。
2、数据准备
(1)建表t_course
create table t_course(id int,course string)
row format delimited fields terminated by ",";
(2)导入数据
load data local inpath "/home/hadoop/course/course.txt" into table t_course;
3、需求
编写Hive的HQL语句来实现以下结果:表中的1表示选修,表中的0表示未选修
id a b c d e f
1 1 1 1 0 1 0
2 1 0 1 1 0 1
3 1 1 1 0 1 0
4、解析
第一步:
select collect_set(course) as courses from id_course;
第二步:
set hive.strict.checks.cartesian.product=false;
create table id_courses as select t1.id as id,t1.course as id_courses,t2.course courses
from
( select id as id,collect_set(course) as course from id_course group by id ) t1
join
(select collect_set(course) as course from id_course) t2;

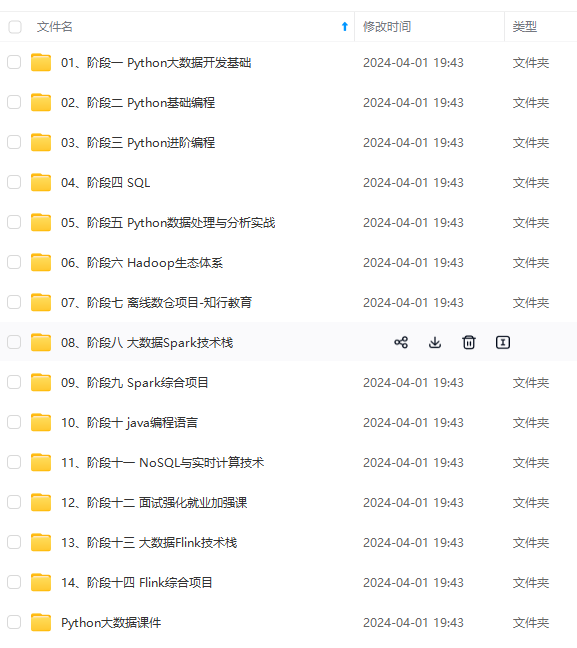
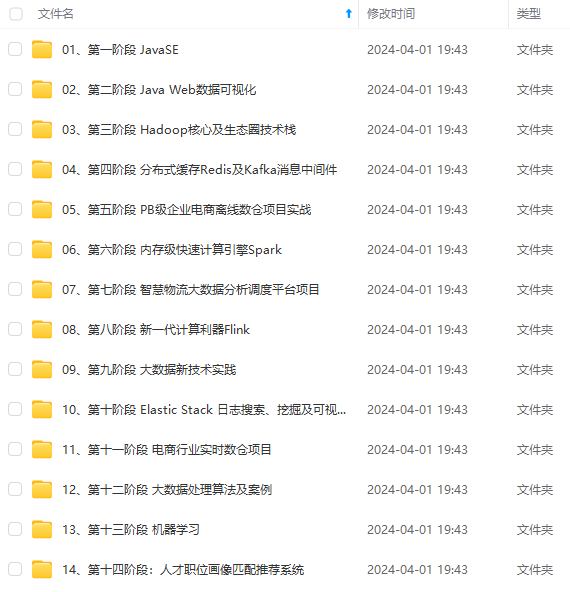
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









