







 本文详细介绍了朴素贝叶斯算法在文章分类中的运用,特别是如何处理特征频率为0的问题,以及与拉普拉斯平滑系数的结合。文章还讨论了朴素贝叶斯的优点、缺点和与逻辑回归的区别,提供了一套适合不同学习阶段的大数据教育资源。
本文详细介绍了朴素贝叶斯算法在文章分类中的运用,特别是如何处理特征频率为0的问题,以及与拉普拉斯平滑系数的结合。文章还讨论了朴素贝叶斯的优点、缺点和与逻辑回归的区别,提供了一套适合不同学习阶段的大数据教育资源。

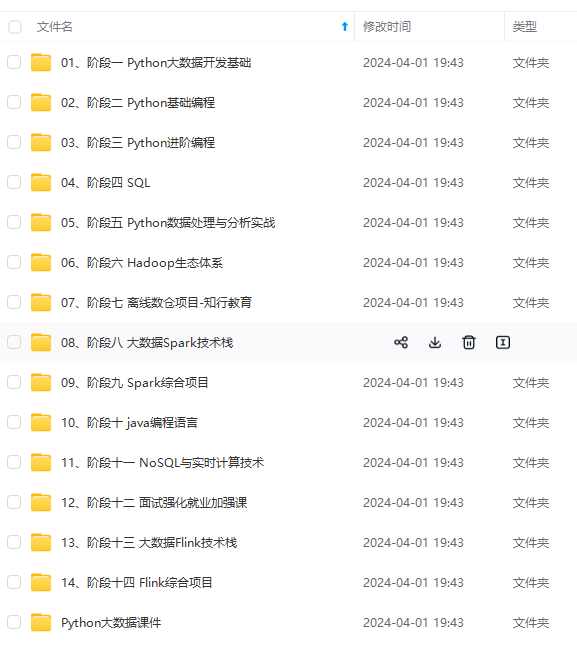
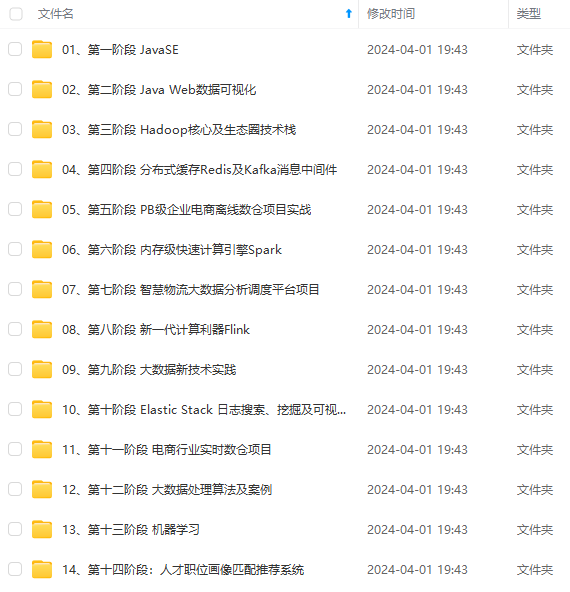
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
所以,思考题如果按照朴素贝叶斯的思路来解决,就可以是
P(产品, 超重) = P(产品) \* P(超重) = 2/7 \* 3/7 = 6/49
p(产品, 超重|喜欢) = P(产品|喜欢) \* P(超重|喜欢) = 1/2 \* 1/4 = 1/8
P(喜欢|产品, 超重) = P(产品, 超重|喜欢)P(喜欢)/P(产品, 超重) = 1/8 \* 4/7 / 6/49 = 7/12
3 拉普拉斯平滑系数
贝叶斯公式如果应用在文章分
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









