







技术一、JAVA
1、什么是JVM
JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。
引入Java语言虚拟机后,Java语言在不同平台上运行时不需要重新编译。Java语言使用Java虚拟机屏蔽了与具体平台相关的信息,使得Java语言编译程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。
通过JVM,Java实现了平台无关性,Java语言在不同平台运行时不需要重新编译,只需要在该平台上部署JVM就可以了。因而能实现一次编译多处运行。
2、JRE和JDK
JRE:Java Runtime Environment,也就是JVM的运行平台,联系平时用的虚拟机,大概可以理解成JRE=虚拟机平台+虚拟机本体(JVM)。类似于你电脑上的VMWare+适用于VMWare的Ubuntu虚拟机。这样我们也就明白了JVM到底是个什么。
JDK:Java Develop Kit,Java的开发工具包,JDK本体也是Java程序,因此运行依赖于JRE,由于需要保持JDK的独立性与完整性,JDK的安装目录下通常也附有JRE。目前Oracle提供的Windows下的JDK安装工具会同时安装一个正常的JRE和隶属于JDK目录下的JRE。
3、JVM位置
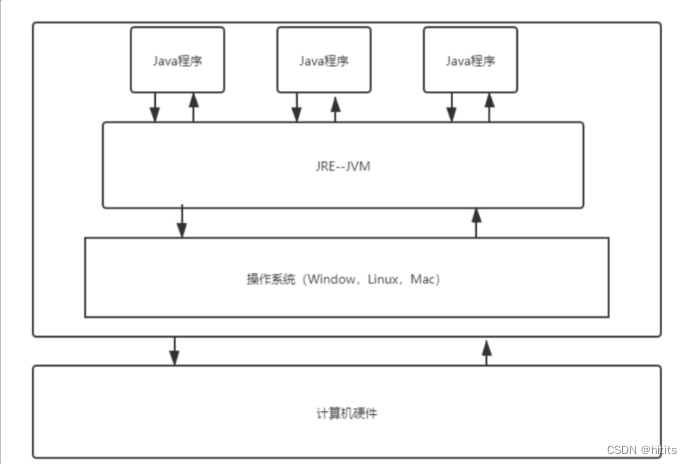
4、JVM体系结构
简图:
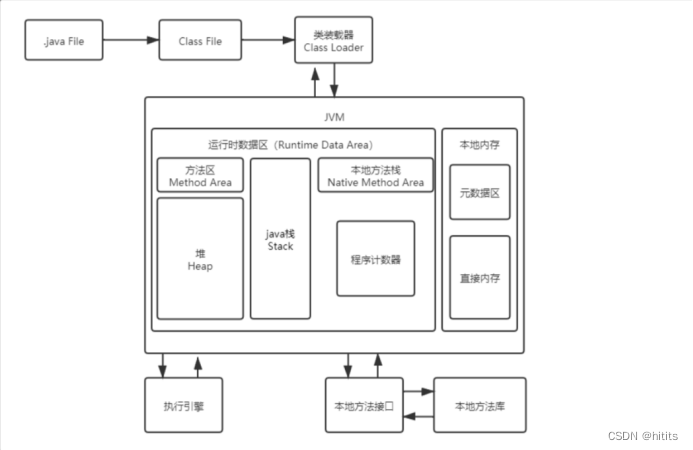
详图:

5、ClassLoader(类加载器)
(1)、类加载的机制的层次结构
每个编写的".java"拓展名类文件都存储着需要执行的程序逻辑,这些".java"文件经过Java编译器编译成拓展名为".class"的文件,“.class"文件中保存着Java代码经转换后的虚拟机指令,当需要使用某个类时,虚拟机将会加载它的”.class"文件,并创建对应的class对象,将class文件加载到虚拟机的内存,这个过程称为类加载,这里我们需要了解一下类加载的过程,如下:
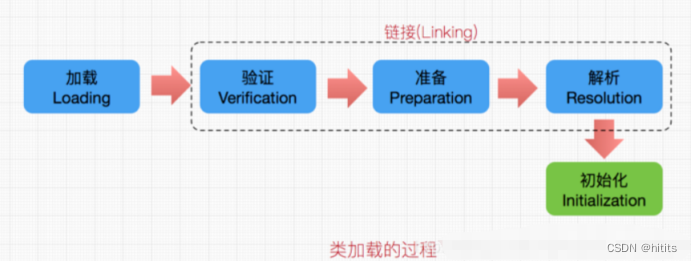
在虚拟机提供了3种类加载器,引导(Bootstrap)类加载器、扩展(Extension)类加载器、系统(System)类加载器(也称应用类加载器),下面分别介绍
启动(Bootstrap)类加载器
启动类加载器主要加载的是JVM自身需要的类,这个类加载使用C++语言实现的,是虚拟机自身的一部分,它负责将 <JAVA_HOME>/lib路径下的核心类库或-Xbootclasspath参数指定的路径下的jar包加载到内存中,注意必由于虚拟机是按照文件名识别加载jar包的,如rt.jar,如果文件名不被虚拟机识别,即使把jar包丢到lib目录下也是没有作用的(出于安全考虑,Bootstrap启动类加载器只加载包名为java、javax、sun等开头的类)。
扩展(Extension)类加载器
扩展类加载器是指Sun公司(已被Oracle收购)实现的sun.misc.Launcher E x t C l a s s L o a d e r 类,由 J a v a 语言实现的,是 L a u n c h e r 的静态内部类,它负责加载 < J A V A H O M E > / l i b / e x t 目录下或者由系统变量 − D j a v a . e x t . d i r 指定位路径中的类库,开发者可以直接使用标准扩展类加载器。系统( S y s t e m )类加载器也称应用程序加载器是指 S u n 公司实现的 s u n . m i s c . L a u n c h e r ExtClassLoader类,由Java语言实现的,是Launcher的静态内部类,它负责加载<JAVA_HOME>/lib/ext目录下或者由系统变量-Djava.ext.dir指定位路径中的类库,开发者可以直接使用标准扩展类加载器。 系统(System)类加载器 也称应用程序加载器是指 Sun公司实现的sun.misc.Launcher ExtClassLoader类,由Java语言实现的,是Launcher的静态内部类,它负责加载<JAVAHOME>/lib/ext目录下或者由系统变量−Djava.ext.dir指定位路径中的类库,开发者可以直接使用标准扩展类加载器。系统(System)类加载器也称应用程序加载器是指Sun公司实现的sun.misc.LauncherAppClassLoader。它负责加载系统类路径java -classpath或-D java.class.path 指定路径下的类库,也就是我们经常用到的classpath路径,开发者可以直接使用系统类加载器,一般情况下该类加载是程序中默认的类加载器,通过ClassLoader#getSystemClassLoader()方法可以获取到该类加载器。
全流程简图
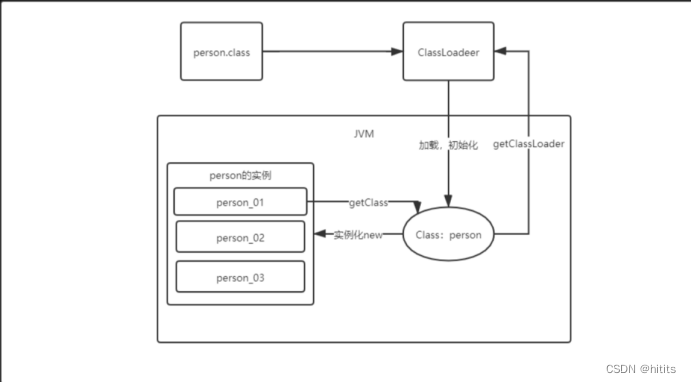
//代码详解
public class TestClassLoader {
public static void main(String[] args) {
Person person_01 = new Person();
Person person_02 = new Person();
Person person_03 = new Person();
//发现person_01,person_02,person_03的hashCode不一致,代表这三个实例化对象虽隶属于一个Class,即Person,但它们的hashCode值不一样,即代表内存空间的首地址不同,即这仨对象开辟在不同的内存空间。
System.out.println(person_01.hashCode());
System.out.println(person_02.hashCode());
System.out.println(person_03.hashCode());
//Person实例化对象person_01通过getClass()方法得到Class对象Person
Class Person = person_01.getClass();
//Person通过getClassLoader()方法得到系统类加载器
ClassLoader myClassLoader = Person.getClassLoader();
System.out.println(myClassLoader.hashCode());
//加载器对象myClassLoader通过getParent()方法得到拓展类加载器
ClassLoader myParentClassLoader = myClassLoader.getParent();
System.out.println(myParentClassLoader.hashCode());
//加载器对象myGPClassLoader通过getParent()方法得到引导类加载器
ClassLoader myGPClassLoader = myParentClassLoader.getParent();
System.out.println(myGPClassLoader.hashCode()); //发现报错,无法通过方法获取引导类加载器
}
}
class Person{}
(2)、双亲委派机制
双亲委派模式要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器,请注意双亲委派模式中的父子关系并非通常所说的类继承关系,而是采用组合关系来复用父类加载器的相关代码,类加载器间的关系如下:
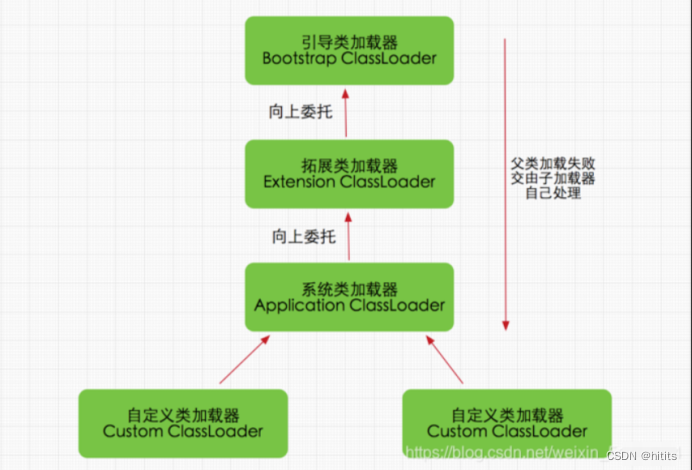
双亲委派机制工作原理为如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器,如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载。
双亲委派机制优点:
因为双亲委派是向上委托加载的,所以它可以确保类只被加载一次, 避免重复加载 。
Java的核心API都是通过引导类加载器进行加载的,如果别人通过定义同样路径的类比如java.lang.Integer,类加载器通过向上委托,两个Integer,那么最终被加载的应该是jdk的Integer类,而并非我们自定义的,这样就 避免了我们恶意篡改核心包的风险 。
6、沙箱安全机制
沙箱机制就是将 Java 代码限定在虚拟机(JVM)特定的运行范围中,并且严格限制代码对本地系统资源访问,通过这样的措施来保证对代码的有效隔离,防止对本地系统造成破坏。沙箱主要限制系统资源访问,那系统资源包括什么?——CPU、内存、文件系统、网络。
组成沙箱的基本组件:
1.字节码校验器(bytecode verifier) :确保Java类文件遵循Java语言规范。这样可以帮助Java程序实现内存保护。但并不是所有的类文件都会经过字节码校验,比如核心类。
2.类裝载器(class loader) :其中类装载器在3个方面对Java沙箱起作用
防止恶意代码去干涉善意的代码;
守护了被信任的类库边界;
将代码归入保护域,确定了代码可以进行哪些操作。
7、本地方法栈(Native)
程序中使用:private native void start0();
1.凡是带了native关键字的,说明java的作用范围达不到了,回去调用底层c语言的库!
2.会进入本地方法栈,然后去调用本地方法接口将native方法引入执行
本地方法栈(Native Method Stack)
内存区域中专门开辟了一块标记区域: Native Method Stack,负责登记native方法,在执行引擎( Execution Engine )执行的时候通过本地方法接口(JNI)加载本地方法库中的方法。
本地方法接口(JNI)
本地接口的作用是融合不同的编程语言为Java所用,它的初衷是融合C/C++程序, Java在诞生的时候是C/C++横行的时候,想要立足,必须有调用C、C++的程序,然后在内存区域中专门开辟了一块标记区域: Native Method Stack,负责登记native方法,在执行引擎( Execution Engine )执行的时候通过本地方法接口(JNI)加载本地方法库中的方法。
8、PC程序计数器
程序计数器: Program Counter Register
每个线程都有一个程序计数器,是线程私有的,就是一个指针, 指向方法区中的方法字节码(用来存储指向像一条指令的地址, 也即将要执行的指令代码),在执行引擎读取下一条指令, 是一个非常小的内存空间,几乎可以忽略不计。
为什么需要程序计数器?
记录要执行的代码位置,防止线程切换重新执行字节码执行引擎修改程序计数器的值
9、方法区(Method Area)
方法区是被所有线程共享,所有字段和方法字节码,以及一些特殊方法,如构造函数,接口代码也在此定义,简单说,所有定义的方法的信息都保存在该区域,此区域属于共享区间。
静态变量(static)、常量(final)、类信息(构造方法、接口定义)(Class)、运行时的常量池存在方法区中,但是实例变量存在堆内存中,和方法区无关
10、栈
栈:后进先出,每个线程都有自己的栈,栈内存主管程序的运行,生命周期和线程同步,线程结束,栈内存也就是释放。
对于栈来说,不存在垃圾回收问题,一旦线程结束,栈就结束.
栈内存中运行:8大基本类型+对象引用+实例的方法.
栈运行原理:栈桢
栈满:StackOverflowError
栈细分4部分
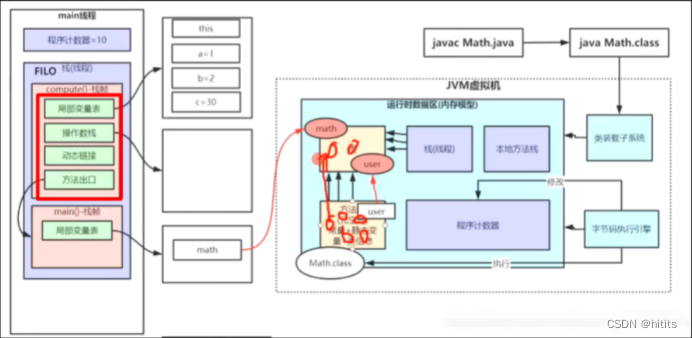
例:int a=7;
局部变量表:存放局部变量(a)
操作数栈:存放操作数(7)
动态链接:将符号引用转成直接引用(符号引用就是你知道调用了谁,直接引用就是你拿到可要调用的方法的地址)
方法出口:方法结束
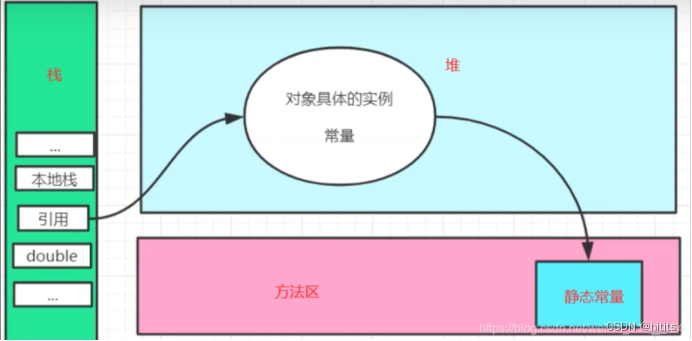
11、堆(重点)
一个JVM只有一个堆内存,堆内存的大小是可以调节的,类加载器读取类文件后,一般会把类,方法,常量,变量,我们所有引用类型的真实对象,放入堆中。
堆内存细分为三个区域:
新生区(伊甸园区):Young/New
养老区old
永久区Perm
新生区:类的诞生,成长和死亡的地方
分为:
伊甸园区:所有对象都在伊甸园区new出来
幸存0区和幸存1区:轻GC之后存下来的
老年区(养老区):多次轻GC存活下来的对象放在老年区
真理:经过研究,99%的对象都是临时对象!
永久区
注意:
元空间:逻辑上存在,物理上不存在 ,因为:存储在本地磁盘内,不占用虚拟机内存
默认情况下,JVM使用的最大内存为电脑总内存的四分之一,JVM使用的初始化内存为电脑总内存的六十四分之一.
总结:
栈:基本类型的变量,对象的引用变量,实例对象的方法
堆:存放由new创建的对象和数组
方法区:Class对象,static变量,常量池(常量)
12、使用JPofiler工具分析OOM原因
13、常见JVM调优参数

14、垃圾回收(GC)
无法手动垃圾回收,只能手动提醒,等待JVM自动回收
GC的作用区在堆(Heap)和方法区中
JVM进行GC时,并不是统一对这三区域(新生区,幸存区,老年区)统一回收,回收都是新生代
轻GC(普通GC)只针对于新生区,偶尔作用幸存区(在新生区满的情况下)
重GC(全局GC)全局释放内存
15、常见垃圾回收算法
1.引用计数算法
原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。垃圾回收时,只用收集计数为 0 的对象。此算法最致命的是无法处理循环引用的问题。
2.复制算法
此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中,同时回收未使用的对象。此算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理。
优点:不会出现碎片化问题
缺点:需要两倍内存空间,浪费
3.标记-清除算法
此算法执行分两阶段。第一阶段从引用根节点开始标记所用存活的对象,第二阶段遍历整个堆,把未标记的对象清除。
优点:不会浪费内存空间
缺点:此算法需要暂停整个应用,同时,会产生内存碎片
4.标记-压缩算法
此算法结合了“标记-清除”和“复制”两个算法的优点。也是分两阶段,第一阶段从根节点开始标记所有存活的对象,第二阶段遍历整个堆,清除未标记对象并且把存活对象“压缩”到堆的其中一块,按顺序排放。
此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
总结:
内存效率(时间复杂度):复制算法>标记清除算法>标记压缩算法
内存效率整齐度:复制算法=标记压缩算法>标记清除算法
内存利用率:标记清除算法=标记压缩算法>复制算法
16、分代回收策略
1.绝大多数刚刚被创建的对象会存放在Eden区
2.当Eden区第一次满的时候,会触发MinorGC(轻GC)。首先将Eden区的垃圾对象回收清除,并将存活的对象复制到S0,此时S1是空的。
3.下一次Eden区满时,再执行一次垃圾回收,此次会将Eden和S0区中所有垃圾对象清除,并将存活对象复制到S1,此时S0变为空。
4.如此反复在S0和S1之间切换几次(默认15次)之后,还存活的对象将他们转移到老年代中。
5.当老年代满了时会触发FullGC(全GC)
MinorGC
使用的算法是复制算法
年轻代堆空间紧张时会被触发
相对于全收集而言,收集间隔较短
FullGC
使用的算法一般是标记压缩算法
当老年代堆空间满了,会触发全收集操作
可以使用 System.gc()方法来显式的启动全收集
全收集非常耗时
17、垃圾收集器
垃圾回收器的常规匹配:
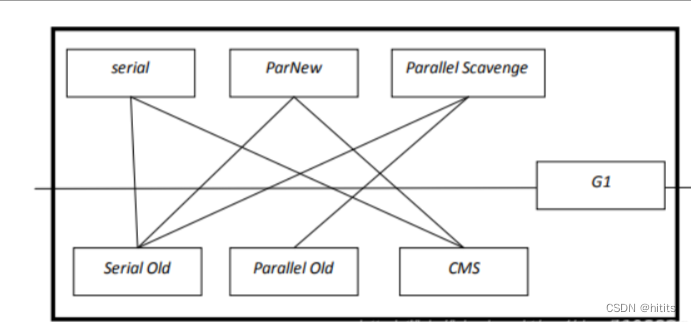
1.串行收集器(Serial)
Serial 收集器是 Hotspot 运行在 Client 模式下的默认新生代收集器, 它的特点是:单线程收集, 但它却简单而高效
2.并行收集器(ParNew)
ParNew 收集器其实是前面 Serial 的多线程版本
3.Parallel Scavenge 收集器
与 ParNew 类似, Parallel Scavenge 也是使用复制算法, 也是并行多线程收集器. 但与其
他收集器关注尽可能缩短垃圾收集时间不同, Parallel Scavenge 更关注系统吞吐量:
系统吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)
4.Serial Old 收集器
Serial Old 是 Serial 收集器的老年代版本, 同样是单线程收集器,使用“标记-整理”算法
5.Parallel Old 收集器
Parallel Old 是 Parallel Scavenge 收集器的老年代版本, 使用多线程和“标记-整理”算
法, 吞吐量优先
6.CMS 收集器(Concurrent Mark Sweep)
CMS是一种以获取最短回收停顿时间为目标的收集器(CMS又称多并发低暂停的收集器),
基于”标记-清除”算法实现, 整个 GC 过程分为以下 4 个步骤:
初始标记(CMS initial mark)
并发标记(CMS concurrent mark: GC Roots Tracing 过程)
重新标记(CMS remark)
并发清除(CMS concurrent sweep: 已死对象将会就地释放, 注意:此处没有压缩)
7.G1 收集器
G1将堆内存“化整为零”,将堆内存划分成多个大小相等独立区域(Region),每一个Region都可以根据需要,扮演新生代的Eden空间、Survivor空间,或者老年代空间。收集器能够对扮演不同角色的Region采用不同的策略去处理,这样无论是新创建的对象还是已经存活了一段时间、熬过多次收集的旧对象都能获取很好的收集效果。
18、为什么要垃圾回收时要设计STW(stop the world)?
如果不设计STW,可能在垃圾回收时用户线程就执行完了,堆中的对象都失去了引用,全部变成了垃圾,索性就设计了STW,快速做完垃圾回收,再恢复用户线程运行。
19、JMM(java内存模型)
JMM(java内存模型)Java Memory Model,本身是一个抽象的概念,不是真实存在的,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段、静态字段和构成数组对象的元素)的访问方式。
JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程读/写共享变量的副本。
JMM内存模型三大特性
1、原子性
使用 synchronized 互斥锁来保证操作的原子性
2、可见性:
volatile,会强制将该变量自己和当时其他变量的状态都刷出缓存。
synchronized,对一个变量执行 unlock 操作之前,必须把变量值同步回主内存。
final,被 final 关键字修饰的字段在构造器中一旦初始化完成,并且没有发生 this 逃逸(其它线程通过 this 引用访问到初始化了一半的对象),那么其它线程就能看见 final 字段的值。
3、有序性
源代码 -> 编译器优化的重排 -> 指令并行的重排 -> 内存系统的重排 ->最终执行的命令。
重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
处理器在进行重排时必须考虑数据的依赖性,多线程环境线程交替执行,由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的。
技术二、hadoop
1.hadoop及其组件
Hadoop是一个开源分布式计算平台架构,基于apache协议发布,由java语言开发。主要包括
HDFS(分布式文件管理系统)
MapReduce(分布式计算框架)
Yarn(资源管理器)
2.NameNode与SecondaryNameNode的区别与联系
区别
1)NameNode存储了文件系统下所有目录和文件的访问,修改,执行时间,块大小,执行权限等
2)SecondaryNameNode并非NameNode的热备(≠ StandBy NameNode)。定期触发CheckPoint(服务),代替NameNode合并EditLog和fsimage文件。
联系
1)SecondaryNameNode中保存了一份和NameNode一致的fsimage和edits文件。但是,NameNode还有一份正在使用的编辑日志edit_inporgress,这是SecondaryNameNode没有的。
2)在主namenode发生故障时(假设没有及时备份数据),可以从SecondaryNameNode恢复历史的数据。
3.SecondaryNameNode的目的是什么
SecondaryNameNode定期触发CheckPoint,代表NameNode合并编辑日志EditLog和镜像文件Fsimage,从而减小EditLog的大小,减少NN启动时间。
同时在合并期间,NameNode也可以对外提供写操作。
4.Block大小
如果一个文件小于128M,它只占用文件本身大小的空间,其它空间别的文件也能用。
Block大小设置主要取决于磁盘传输速率。
(把文件分为N块,读取文件时就要寻址N次)
5.请列出正常工作的Hadoop集群中Hadoop都分别需要启动哪些进程,它们的作用分别是什么?
1)NameNode:它是hadoop中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问,保存有metadate。
2)SecondaryNameNode:它不是namenode的冗余守护进程,而是提供周期检查点和清理任务。帮助NN合并editslog,减少NN启动时间。
3)DataNode:它负责管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个datanode守护进程。
4)ResourceManager(JobTracker):JobTracker负责调度DataNode上的工作。每个DataNode有一个TaskTracker,它们执行实际工作。
5)NodeManager:(TaskTracker)执行任务。
6)DFSZKFailoverController:高可用时它负责监控NN的状态,并及时的把状态信息写入ZK。它通过一个独立线程周期性的调用NN上的一个特定接口来获取NN的健康状态。FC也有选择谁作为Active NN的权利,因为最多只有两个节点,目前选择策略还比较简单(先到先得,轮换)。
7)JournalNode:高可用情况下存放namenode的editlog文件。
6.NameNode与SecondaryNameNode的区别与联系
区别
1)NameNode存储了文件系统下所有目录和文件的访问,修改,执行时间,块大小,执行权限等
2)SecondaryNameNode并非NameNode的热备(≠ StandBy NameNode)。定期触发CheckPoint(服务),代替NameNode合并EditLog和fsimage文件。
联系
1)SecondaryNameNode中保存了一份和NameNode一致的fsimage和edits文件。但是,NameNode还有一份正在使用的编辑日志edit_inporgress,这是SecondaryNameNode没有的。
2)在主namenode发生故障时(假设没有及时备份数据),可以从SecondaryNameNode恢复历史的数据。
7.SecondaryNameNode的目的是什么
SecondaryNameNode定期触发CheckPoint,代表NameNode合并编辑日志EditLog和镜像文件Fsimage,从而减小EditLog的大小,减少NN启动时间。
同时在合并期间,NameNode也可以对外提供写操作。
8.如果数据误删,如何抢救?
1.立即关闭Hadoop服务
2.打开edit_log文件,删除未发送的心跳包的命令
9.如何理解Hadoop中的数据倾斜现象?
A.可能因为HDFS的存储不均衡:可能的原因是后扩展了集群的几台机器
B.使用默认的HashPartitoner
C.输入数据中不均匀的键分布
解决方法:执行 /opt/software/hadoop-3.1.3/sbin/start-balancer.sh
10.HDFS的读/写数据流程
HDFS的写(上传)数据流程
1)HDFS client创建DFS对象,通过该对象向NameNode请求上传文件,NameNode检查权限,并判断该目标文件是否已存在。
2)如果权限许可,目标文件也存在,NameNode响应请求。
3)客户端请求第一个Block上传到哪几台DataNode服务器上。
4)NameNode返回3个DataNode结点
5)HDFS client创建FS DataOutputStream数据流对象,请求dn1建立传输通道,dn1接收到请求之后会继续调用dn2建立通道…
6)传输通道建立完成之后,dn1,dn2,dn3逐级应答客户端。
7)客户端开始往dn1上传第一个Block,dn1利用通道传向dn2,dn2利用通道传向dn3…(直到传到Block副本应在的位置停止)
8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block到服务器。(重复3-7步)
HDFS的读数据流程
1)HDFS client创建DFS对象,该对象向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
2)挑选一台DataNode(要考虑结点距离最近选择原则,DataNode负载均衡)服务器,请求读取数据。
3)数据从DataNode传到客户端,如果在传输过程中出现宕机,才会考虑向含有该副本的其他节点获取数据。
4)客户端接收,写在本地缓存,然后写入目标文件。
11.请简述DataNode的工作机制
1)一个数据块在DataNode上以文件的形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据的校验信息。
2)DataNode 启动后向 NameNode 注册,之后周期性(默认 6 小时)的向 NameNode 上报所有的块信息。同时,DN 扫描自己节点块信息列表的时间,检查DN中的块是否完好,如果某块磁盘损坏,就将该块磁盘上存储的所有 BlockID报告给NameNode。
3)心跳是每 3 秒一次,心跳返回结果带有 NameNode 给该 DataNode 的命令如复制块数据到另一台机器,或删除某个数据块。 如果超过 10 分钟 + 30s 没有收到某个 DataNode 的心跳,则认为该节点不可用。
12.Namenode和Datanode的心跳机制
心跳是datanode向namenode发送的小数据包,表明它是活跃的。默认情况下,每3秒datanode就会向namenode发送一次心跳信号。如果namenode在10分钟内没有收到任何datanode的心跳,它会将该datanode标记为“死亡”,并开始数据的复制过程,将其复制到其他datanode,以保持数据的冗余和可靠性。
13.Safe Mode
Safe Mode是HDFS的一种状态,在此状态下,系统处于只读模式,不会进行数据块的复制或删除。
这通常用于系统维护或故障恢复。
管理员可以使用命令"hdfs dfsadmin -safemode enter"进入安全模式,"hdfs dfsadmin -safemode leave"退出安全模式,而"hdfs dfsadmin -safemode get"则用来查询系统是否处于安全模式。
14.Hadoop启动流程
首先,启动HDFS,通常包括启动namenodes,datanodes和secondary namenodes。
其次,启动YARN的资源管理器和节点管理器。
最后,如果在集群中运行MapReduce作业,则还需要启动MapReduce的历史服务器。
15.如何检查?
检查服务:jps
检查路径:
cd /opt/software/hadoop-3.1.3/logs/hadoop-root-namenode-single.log
检查端口:netstat -anutp | grep 9870
检查安全模式:hdfs dfsadmin -safemode get
重启服务
17.YARN的工作原理
18、hadoop的块大小,从哪个版本开始是128M
Hadoop1.x都是64M,hadoop2.x开始都是128M。
19、HDFS的存储机制
HDFS存储机制,包括HDFS的写入数据过程和读取数据过程两部分
HDFS写数据过程
1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
2)NameNode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)NameNode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3; dn1每传一个packet会放入一个应答队列等待应答。
8)当一个block传输完成之后,客户端再次请求NameNode上传第二个block的服务器。(重复执行3-7步)。
HDFS读数据过程
1)客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
20、secondary namenode工作机制
1)第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对数据进行增删改查。
2)第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要checkpoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行checkpoint。
(3)NameNode滚动正在写的edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
21、HDFS组成架构
架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。下面我们分别介绍这四个组成部分。
1)Client:就是客户端。
(1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行存储;
(2)与NameNode交互,获取文件的位置信息;
(3)与DataNode交互,读取或者写入数据;
(4)Client提供一些命令来管理HDFS,比如启动或者关闭HDFS;
(5)Client可以通过一些命令来访问HDFS;
2)NameNode:就是Master,它是一个主管、管理者。
(1)管理HDFS的名称空间;
(2)管理数据块(Block)映射信息;
(3)配置副本策略;
(4)处理客户端读写请求。
3)DataNode:就是Slave。NameNode下达命令,DataNode执行实际的操作。
(1)存储实际的数据块;
(2)执行数据块的读/写操作。
4)Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
(1)辅助NameNode,分担其工作量;
(2)定期合并Fsimage和Edits,并推送给NameNode;
(3)在紧急情况下,可辅助恢复NameNode。
22、HAnamenode 是如何工作的?
ZKFailoverController主要职责
1)健康监测:周期性的向它监控的NN发送健康探测命令,从而来确定某个NameNode是否处于健康状态,如果机器宕机,心跳失败,那么zkfc就会标记它处于一个不健康的状态。
2)会话管理:如果NN是健康的,zkfc就会在zookeeper中保持一个打开的会话,如果NameNode同时还是Active状态的,那么zkfc还会在Zookeeper中占有一个类型为短暂类型的znode,当这个NN挂掉时,这个znode将会被删除,然后备用的NN,将会得到这把锁,升级为主NN,同时标记状态为Active。
3)当宕机的NN新启动时,它会再次注册zookeper,发现已经有znode锁了,便会自动变为Standby状态,如此往复循环,保证高可靠,需要注意,目前仅仅支持最多配置2个NN。
4)master选举:如上所述,通过在zookeeper中维持一个短暂类型的znode,来实现抢占式的锁机制,从而判断那个NameNode为Active状态
23、谈谈Hadoop序列化和反序列化及自定义bean对象实现序列化?
1)序列化和反序列化
(1)序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储(持久化)和网络传输。
(2)反序列化就是将收到字节序列(或其他数据传输协议)或者是硬盘的持久化数据,转换成内存中的对象。
(3)Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,header,继承体系等),不便于在网络中高效传输。所以,hadoop自己开发了一套序列化机制(Writable),精简、高效。
2)自定义bean对象要想序列化传输步骤及注意事项:
(1)必须实现Writable接口
(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
(3)重写序列化方法
(4)重写反序列化方法
(5)注意反序列化的顺序和序列化的顺序完全一致
(6)要想把结果显示在文件中,需要重写toString(),且用"\t"分开,方便后续用
(7)如果需要将自定义的bean放在key中传输,则还需要实现comparable接口,因为mapreduce框中的shuffle过程一定会对key进行排序
24、FileInputFormat切片机制
job提交流程源码详解
waitForCompletion() submit(); // 1、建立连接
connect(); // 1)创建提交job的代理
new Cluster(getConfiguration()); // (1)判断是本地yarn还是远程 initialize(jobTrackAddr, conf); // 2、提交job
submitter.submitJobInternal(Job.this, cluster) // 1)创建给集群提交数据的Stag路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf); // 2)获取jobid ,并创建job路径
JobID jobId = submitClient.getNewJobID(); // 3)拷贝jar包到集群
copyAndConfigureFiles(job, submitJobDir); rUploader.uploadFiles(job, jobSubmitDir); // 4)计算切片,生成切片规划文件
writeSplits(job, submitJobDir); maps = writeNewSplits(job, jobSubmitDir); input.getSplits(job); // 5)向Stag路径写xml配置文件
writeConf(conf, submitJobFile); conf.writeXml(out); // 6)提交job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
25、在一个运行的Hadoop 任务中,什么是InputSplit?
FileInputFormat源码解析(input.getSplits(job))
(1)找到你数据存储的目录。
(2)开始遍历处理(规划切片)目录下的每一个文件。
(3)遍历第一个文件ss.txt。
a)获取文件大小fs.sizeOf(ss.txt);。
b)计算切片大小:computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M。
c)默认情况下,切片大小=blocksize。
d)开始切,形成第1个切片:ss.txt—0:128M 第2个切片ss.txt—128:256M 第3个切片ss.txt—256M:300M(每次切片时,都要判断切完剩下的部分是否大于块的1.1倍,不大于1.1倍就划分一块切片)。
e)将切片信息写到一个切片规划文件中。
f)整个切片的核心过程在getSplit()方法中完成。
g)数据切片只是在逻辑上对输入数据进行分片,并不会再磁盘上将其切分成分片进行存储。InputSplit只记录了分片的元数据信息,比如起始位置、长度以及所在的节点列表等。
h)注意:block是HDFS上物理上存储的存储的数据,切片是对数据逻辑上的划分。
(4)提交切片规划文件到yarn上,yarn上的MrAppMaster就可以根据切片规划文件计算开启maptask个数。
26、如何判定一个job的map和reduce的数量?
1)map数量 splitSize=max{minSize,min{maxSize,blockSize}} map数量由处理的数据分成的block数量决定default_num = total_size / split_size; 2)reduce数量 reduce的数量job.setNumReduceTasks(x);x 为reduce的数量。不设置的话默认为 1。
27、 Maptask的个数由什么决定?
一个job的map阶段MapTask并行度(个数),由客户端提交job时的切片个数决定。
28、MapTask和ReduceTask工作机制
MapTask工作机制
(1)Read阶段:Map Task通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
(2)Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
(3)Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。
(4)Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
(5)Combine阶段:当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
ReduceTask工作机制
(1)Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
(2)Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
(3)Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。 由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
(4)Reduce阶段:reduce()函数将计算结果写到HDFS上。
29、描述mapReduce有几种排序及排序发生的阶段
1)排序的分类:
(1)部分排序:MapReduce
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









