







结尾
学习html5、css、javascript这些基础知识,学习的渠道很多,就不多说了,例如,一些其他的优秀博客。但是本人觉得看书也很必要,可以节省很多时间,常见的javascript的书,例如:javascript的高级程序设计,是每位前端工程师必不可少的一本书,边看边用,了解js的一些基本知识,基本上很全面了,如果有时间可以读一些,js性能相关的书籍,以及设计者模式,在实践中都会用的到。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
- dataA
- dataB
- dataC
- dataD
- dataE
- dataF
切换到第二页后,由于所有
<li>的 key 值不同,所以 Diff 算法会将第一页的所有 DOM 节点标记为删除,然后将第二页的所有 DOM 节点标记为新增。整个更新过程需要三次 DOM 删除、三次 DOM 创建。如果不使用 key,Diff 算法只会将三个
<li>节点标记为更新,执行三次 DOM 更新。参考 Demo 没有添加、删除、排序功能的分页列表[16], 使用 key 时每次翻页耗时约为 140ms,而不使用 key 仅为 70ms。尽管存在以上场景,React 官方仍然推荐使用 ID 作为每项的 key 值。其原因有两:
-
在列表中执行删除、插入、排序列表项的操作时,使用 ID 作为 key 将更高效。而翻页操作往往伴随着 API 请求,DOM 操作耗时远小于 API 请求耗时,是否使用 ID 在该场景下对用户体验影响不大。
-
使用 ID 做为 key 可以维护该 ID 对应的列表项组件的 State。举个例子,某表格中每列都有普通态和编辑态两个状态,起初所有列都是普通态,用户点击第一行第一列,使其进入编辑态。然后用户又拖拽第二行,将其移动到表格的第一行。如果开发者使用索引作为 key,那么第一行第一列的状态仍然为编辑态,而用户实际希望编辑的是第二行的数据,在用户看来就是不符合预期的。尽管这个问题可以通过将「是否处于编辑态」存放在数据项的数据中,利用 Props 来解决,但是使用 ID 作为 key 不是更香吗?
批量更新,减少 Render 次数
我们先回忆一道前几年的 React 面试常考题,React 类组件中 setState 是同步的还是异步的?如果对类组件不熟悉也没关系,可以将 setState 理解为 useState 的第二个返回值。balabala…
答案是:在 React 管理的事件回调和生命周期中,setState 是异步的,而其他时候 setState 都是同步的。这个问题根本原因就是 React 在自己管理的事件回调和生命周期中,对于 setState 是批量更新的,而在其他时候是立即更新的。
读者可参考线上示例 setState 同步还是异步[17],并自行验证。
批量更新 setState 时,多次执行 setState 只会触发一次 Render 过程。相反在立即更新 setState 时,每次 setState 都会触发一次 Render 过程,就存在性能影响。
假设有如下组件代码,该组件在
getData()的 API 请求结果返回后,分别更新了两个 State 。线上代码实操参考:batchUpdates 批量更新[18]。function NormalComponent() {
const [list, setList] = useState(null)
const [info, setInfo] = useState(null)
useEffect(() => {
;(async () => {
const data = await getData()
setList(data.list)
setInfo(data.info)
})()
}, [])
return (
非批量更新组件时 Render 次数:
{renderOnce(‘normal’)}
)
}
该组件会在
setList(data.list)后触发组件的 Render 过程,然后在setInfo(data.info)后再次触发 Render 过程,造成性能损失。遇到该问题,开发者有两种实现批量更新的方式来解决该问题:-
将多个 State 合并为单个 State。例如
useState({ list: null, info: null })替代 list 和 info 两个 State。 -
使用 React 官方提供的 unstable_batchedUpdates 方法,将多次 setState 封装到 unstable_batchedUpdates 回调中。修改后代码如下。
function BatchedComponent() {
const [list, setList] = useState(null)
const [info, setInfo] = useState(null)
useEffect(() => {
;(async () => {
const data = await getData()
unstable_batchedUpdates(() => {
setList(data.list)
setInfo(data.info)
})
})()
}, [])
return (
批量更新组件时 Render 次数:
{renderOnce(‘batched’)}
)
}
拓展知识
- 推荐阅读为什么 setState 是异步的?[19]
- 为什么面试官不会问“函数组件中的 setState 是同步的还是异步的?”?因为函数组件中生成的函数是通过闭包引用了 state,而不是通过 this.state 的方式引用 state,所以函数组件的处理函数中 state 一定是旧值,不可能是新值。可以说函数组件已经将这个问题屏蔽掉了,所以面试官也就不会问了。可参考线上示例[20]。
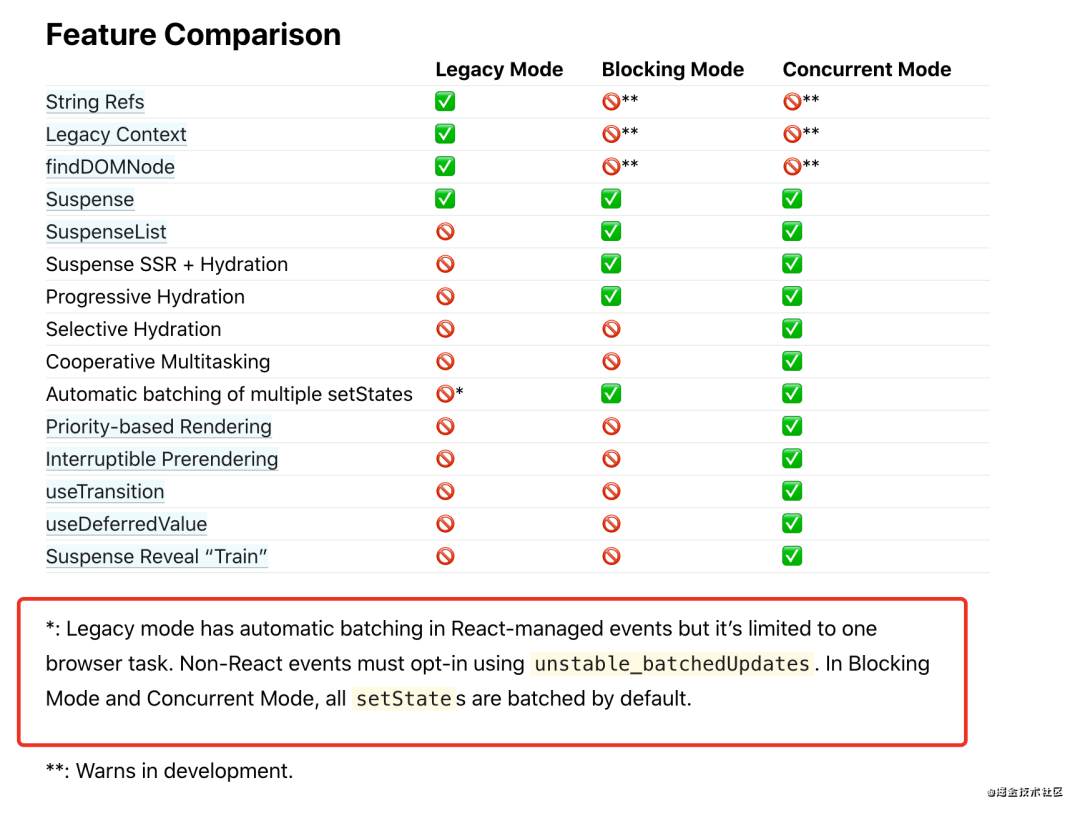
- 根据官方文档[21],在 React 并发模式中,将默认以批量更新方式执行 setState。到那时候,也可能就不需要这个优化了。
按优先级更新,及时响应用户
优先级更新是批量更新的逆向操作,其思想是:优先响应用户行为,再完成耗时操作。常见的场景是:页面弹出一个 Modal,当用户点击 Modal 中的确定按钮后,代码将执行两个操作。
a) 关闭 Modal。
b) 页面处理 Modal 传回的数据并展示给用户。
当 b) 操作需要执行 500ms 时,用户会明显感觉到从点击按钮到 Modal 被关闭之间的延迟。
例子参考:CodeSandbox 在线 Demo[22]。
在该例子中,用户添加一个整数后,页面要隐藏输入框,并将新添加的整数加入到整数列表,将列表排序后再展示。
以下为一般的实现方式,将
slowHandle函数作为用户点击按钮的回调函数。const slowHandle = () => {
setShowInput(false)
setNumbers([…numbers, +inputValue].sort((a, b) => a - b))
}
slowHandle()执行过程耗时长,用户点击按钮后会明显感觉到页面卡顿。如果让页面优先隐藏输入框,用户便能立刻感知到页面更新,不会有卡顿感。
实现优先级更新的要点是将耗时任务移动到下一个宏任务中执行,优先响应用户行为。
例如在该例中,将
setNumbers移动到 setTimeout 的回调中,用户点击按钮后便能立即看到输入框被隐藏,不会感知到页面卡顿。优化后的代码如下。const fastHandle = () => {
// 优先响应用户行为
setShowInput(false)
// 将耗时任务移动到下一个宏任务执行
setTimeout(() => {
setNumbers([…numbers, +inputValue].sort((a, b) => a - b))
})
}
发布者订阅者跳过中间组件 Render 过程
React 推荐将公共数据放在所有「需要该状态的组件」的公共祖先上,但将状态放在公共祖先上后,该状态就需要层层向下传递,直到传递给使用该状态的组件为止。
每次状态的更新都会涉及中间组件的 Render 过程,但中间组件并不关心该状态,它的 Render 过程只负责将该状态再传给子组件。在这种场景下可以将状态用发布者订阅者模式维护,只有关心该状态的组件才去订阅该状态,不再需要中间组件传递该状态。
当状态更新时,发布者发布数据更新消息,只有订阅者组件才会触发 Render 过程,中间组件不再执行 Render 过程。
只要是发布者订阅者模式的库,都可以进行该优化。比如:redux、use-global-state、React.createContext 等。例子参考:发布者订阅者模式跳过中间组件的渲染阶段[23],本示例使用 React.createContext 进行实现。
import { useState, useEffect, createContext, useContext } from ‘react’
const renderCntMap = {}
const renderOnce = name => {
return (renderCntMap[name] = (renderCntMap[name] || 0) + 1)
}
// 将需要公共访问的部分移动到 Context 中进行优化
// Context.Provider 就是发布者
// Context.Consumer 就是消费者
const ValueCtx = createContext()
const CtxContainer = ({ children }) => {
const [cnt, setCnt] = useState(0)
useEffect(
() => {
const timer = window.setInterval(() => {
setCnt(v => v + 1)
}, 1000)
return () => clearInterval(timer)
},
[setCnt]
)
return <ValueCtx.Provider value={cnt}>{children}</ValueCtx.Provider>
}
function CompA({}) {
const cnt = useContext(ValueCtx)
// 组件内使用 cnt
return (
组件 CompA Render 次数:
{renderOnce(‘CompA’)}
)
}
function CompB({}) {
const cnt = useContext(ValueCtx)
// 组件内使用 cnt
return (
组件 CompB Render 次数:
{renderOnce(‘CompB’)}
)
}
function CompC({}) {
return (
组件 CompC Render 次数:
{renderOnce(‘CompC’)}
)
}
export const PubSubCommunicate = () => {
return (
优化后场景
将状态提升至最低公共祖先的上层,用 CtxContainer 将其内容包裹。
每次 Render 时,只有组件A和组件B会重新 Render 。
父组件 Render 次数:
{renderOnce(‘parent’)}
)
}
export default PubSubCommunicate
运行后效果:TODO: 放图。从图中可看出,优化后只有使用了公共状态的组件 CompA 和 CompB 发生了更新,减少了父组件和 CompC 组件的 Render 次数。
useMemo 返回虚拟 DOM 可跳过该组件 Render 过程
利用 useMemo 可以缓存计算结果的特点,如果 useMemo 返回的是组件的虚拟 DOM,则将在 useMemo 依赖不变时,跳过组件的 Render 阶段。
该方式与 React.memo 类似,但与 React.memo 相比有以下优势:
-
更方便。React.memo 需要对组件进行一次包装,生成新的组件。而 useMemo 只需在存在性能瓶颈的地方使用,不用修改组件。
-
更灵活。useMemo 不用考虑组件的所有 Props,而只需考虑当前场景中用到的值,也可使用 useDeepCompareMemo[24] 对用到的值进行深比较。
例子参考:useMemo 跳过组件 Render 过程[25]。
该例子中,父组件状态更新后,不使用 useMemo 的子组件会执行 Render 过程,而使用 useMemo 的子组件不会执行。
import { useEffect, useMemo, useState } from ‘react’
import ‘./styles.css’
const renderCntMap = {}
function Comp({ name }) {
renderCntMap[name] = (renderCntMap[name] || 0) + 1
return (
组件「
{name}」 Render 次数:
{renderCntMap[name]}
)
}
export default function App() {
const setCnt = useState(0)[1]
useEffect(
() => {
const timer = window.setInterval(() => {
setCnt(v => v + 1)
}, 1000)
return () => clearInterval(timer)
},
[setCnt]
)
const comp = useMemo(() => {
return
}, [])
return (
{comp}
)
}
debounce、throttle 优化频繁触发的回调
在搜索组件中,当 input 中内容修改时就触发搜索回调。当组件能很快处理搜索结果时,用户不会感觉到输入延迟。
但实际场景中,中后台应用的列表页非常复杂,组件对搜索结果的 Render 会造成页面卡顿,明显影响到用户的输入体验。
在搜索场景中一般使用 useDebounce[26] + useEffect 的方式获取数据。
例子参考:debounce-search[27]。
import { useState, useEffect } from ‘react’
import { useDebounce } from ‘use-debounce’
export default function App() {
const [text, setText] = useState(‘Hello’)
const [debouncedValue] = useDebounce(text, 300)
useEffect(
() => {
// 根据 debouncedValue 进行搜索
},
[debouncedValue]
)
return (
<input
defaultValue={‘Hello’}
onChange={e => {
setText(e.target.value)
}}
/>
Actual value: {text}
Debounce value: {debouncedValue}
)
}
为什么搜索场景中是使用 debounce,而不是 throttle 呢?throttle 是 debounce 的特殊场景,throttle 给 debounce 传了 maxWait 参数,可参考 useThrottleCallback[28]。
在搜索场景中,只需响应用户最后一次输入,无需响应用户的中间输入值,debounce 更适合使用在该场景中。
而 throttle 更适合需要实时响应用户的场景中更适合,如通过拖拽调整尺寸或通过拖拽进行放大缩小(如:window 的 resize 事件)。
实时响应用户操作场景中,如果回调耗时小,甚至可以用 requestAnimationFrame 代替 throttle。
懒加载
在 SPA 中,懒加载优化一般用于从一个路由跳转到另一个路由。
还可用于用户操作后才展示的复杂组件,比如点击按钮后展示的弹窗模块(有时候弹窗就是一个复杂页面 ???)。
在这些场景下,结合 Code Split 收益较高。懒加载的实现是通过 Webpack 的动态导入和
React.lazy方法,参考例子 lazy-loading[29]。实现懒加载优化时,不仅要考虑加载态,还需要对加载失败进行容错处理。
import { lazy, Suspense, Component } from ‘react’
import ‘./styles.css’
// 对加载失败进行容错处理
class ErrorBoundary extends Component {
constructor(props) {
super(props)
this.state = { hasError: false }
}
static getDerivedStateFromError(error) {
return { hasError: true }
}
render() {
if (this.state.hasError) {
return
这里处理出错场景
}
return this.props.children
}
}
const Comp = lazy(() => {
return new Promise((resolve, reject) => {
setTimeout(() => {
if (Math.random() > 0.5) {
reject(new Error(‘模拟网络出错’))
} else {
resolve(import(‘./Component’))
}
}, 2000)
})
})
export default function App() {
return (
实现懒加载优化时,不仅要考虑加载态,还需要对加载失败进行容错处理。
)
}
懒渲染
懒渲染指当组件进入或即将进入可视区域时才渲染组件。常见的组件 Modal/Drawer 等,当 visible 属性为 true 时才渲染组件内容,也可以认为是懒渲染的一种实现。懒渲染的使用场景有:
-
页面中出现多次的组件,且组件渲染费时、或者组件中含有接口请求。如果渲染多个带有请求的组件,由于浏览器限制了同域名下并发请求的数量,就可能会阻塞可见区域内的其他组件中的请求,导致可见区域的内容被延迟展示。
-
需用户操作后才展示的组件。这点和懒加载一样,但懒渲染不用动态加载模块,不用考虑加载态和加载失败的兜底处理,实现上更简单。
懒渲染的实现中判断组件是否出现在可视区域内是通过 react-visibility-observer[30] 进行监听。例子参考:懒渲染[31]
import { useState, useEffect } from ‘react’
import VisibilityObserver, {
useVisibilityObserver
} from ‘react-visibility-observer’
const VisibilityObserverChildren = ({ callback, children }) => {
const { isVisible } = useVisibilityObserver()
useEffect(
() => {
callback(isVisible)
},
[callback, isVisible]
)
return <>{children}</>
}
export const LazyRender = () => {
const [isRendered, setIsRendered] = useState(false)
if (!isRendered) {
return (
<VisibilityObserver rootMargin={‘0px 0px 0px 0px’}>
<VisibilityObserverChildren
callback={isVisible => {
if (isVisible) {
setIsRendered(true)
}
}}
)
}
console.log(‘滚动到可视区域才渲染’)
return
我是 LazyRender 组件}
export default LazyRender
虚拟列表
虚拟列表是懒渲染的一种特殊场景。虚拟列表的组件有 react-window[32] 和 react-virtualized,它们都是同一个作者开发的。
react-window 是 react-virtualized 的轻量版本,其 API 和文档更加友好。
所以新项目中推荐使用 react-window,而不是使用 Star 更多的 react-virtualized。
使用 react-window 很简单,只需要计算每项的高度即可。下面代码中每一项的高度是 35px。
例子参考:官方示例[33]
import { FixedSizeList as List } from ‘react-window’
const Row = ({ index, style }) =>
Row {index}const Example = () => (
<List
height={150}
itemCount={1000}
itemSize={35} // 每项的高度为 35
width={300}
{Row}
)
如果每项的高度是变化的,可给 itemSize 参数传一个函数。对于这个优化点,笔者遇到一个真实案例。
在公司的招聘项目中,通过下拉菜单可查看某个候选人的所有投递记录。平常这个列表也就几十条,但后来用户反馈『下拉菜单点击后要很久才能展示出投递列表』。
该问题的原因就是这个候选人在我们系统中有上千条投递,一次性展示上千条投递导致页面卡住了。
所以在开发过程中,遇到接口返回的是所有数据时,需提前预防这类 bug,使用虚拟列表优化。
跳过回调函数改变触发的 Render 过程
React 组件的 Props 可以分为两类。
a) 一类是在对组件 Render 有影响的属性,如:页面数据、getPopupContainer[34] 和 renderProps 函数。
b) 另一类是组件 Render 后的回调函数,如:onClick、onVisibleChange[35]。
b) 类属性并不参与到组件的 Render 过程,因为可以对 b) 类属性进行优化。
当 b)类属性发生改变时,不触发组件的重新 Render ,而是在回调触发时调用最新的回调函数。
Dan Abramov 在 A Complete Guide to useEffect[36] 文章中认为,每次 Render 都有自己的事件回调是一件很酷的特性。
但该特性要求每次回调函数改变就触发组件的重新 Render ,这在性能优化过程中是可以取舍的。
例子参考:跳过回调函数改变触发的 Render 过程[37]。
以下代码比较难以理解,可通过调试该例子,帮助理解消化。
import { Children, cloneElement, memo, useEffect, useRef } from ‘react’
import { useDeepCompareMemo } from ‘use-deep-compare’
import omit from ‘lodash.omit’
let renderCnt = 0
export function SkipNotRenderProps({ children, skips }) {
if (!skips) {
// 默认跳过所有回调函数
skips = prop => prop.startsWith(‘on’)
}
const child = Children.only(children)
const childProps = child.props
const propsRef = useRef({})
const nextSkippedPropsRef = useRef({})
Object.keys(childProps)
.filter(it => skips(it))
.forEach(key => {
// 代理函数只会生成一次,其值始终不变
nextSkippedPropsRef.current[key] =
nextSkippedPropsRef.current[key] ||
function skipNonRenderPropsProxy(…args) {
propsRef.current[key].apply(this, args)
}
})
useEffect(() => {
propsRef.current = childProps
})
// 这里使用 useMemo 优化技巧
// 除去回调函数,其他属性改变生成新的 React.Element
return useDeepCompareMemo(
() => {
return cloneElement(child, {
…child.props,
…nextSkippedPropsRef.current
})
},
[omit(childProps, Object.keys(nextSkippedPropsRef.current))]
)
}
// SkipNotRenderPropsComp 组件内容和 Normal 内容一样
export function SkipNotRenderPropsComp({ onClick }) {
return (
跳过『与 Render 无关的 Props』改变触发的重新 Render
Render 次数为:
{++renderCnt}
<button onClick={onClick} style={{ color: ‘blue’ }}>
点我回调,回调弹出值为 1000(优化成功)
)
}
export default SkipNotRenderPropsComp
动画库直接修改 DOM 属性,跳过组件 Render 阶段
这个优化在业务中应该用不上,但还是非常值得学习的,将来可以应用到组件库中。
参考 react-spring[38] 的动画实现,当一个动画启动后,每次动画属性改变不会引起组件重新 Render ,而是直接修改了 dom 上相关属性值。
例子演示:CodeSandbox 在线 Demo[39]
import React, { useState } from ‘react’
import { useSpring, animated as a } from ‘react-spring’
import ‘./styles.css’
let renderCnt = 0
export function Card() {
const [flipped, set] = useState(false)
const { transform, opacity } = useSpring({
opacity: flipped ? 1 : 0,
transform:
perspective(600px) rotateX(${flipped ? 180 : 0}deg),config: { mass: 5, tension: 500, friction: 80 }
})
// 尽管 opacity 和 transform 的值在动画期间一直变化
// 但是并没有组件的重新 Render
return (
Render 次数:
{++renderCnt}
<a.div
class=“c back”
style={{ opacity: opacity.interpolate(o => 1 - o), transform }}
/>
<a.div
class=“c front”
style={{
opacity,
transform: transform.interpolate(t =>
${t} rotateX(180deg))}}
/>
)
}
export default Card
避免在 didMount、didUpdate 中更新组件 State
最后
编程基础的初级开发者,计算机科学专业的学生,以及平时没怎么利用过数据结构与算法的开发人员希望复习这些概念为下次技术面试做准备。或者想学习一些计算机科学的基本概念,以优化代码,提高编程技能。这份笔记都是可以作为参考的。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】

-















 1622
1622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









