







最后
除了简历做到位,面试题也必不可少,整理了些题目,前面有117道汇总的面试到的题目,后面包括了HTML、CSS、JS、ES6、vue、微信小程序、项目类问题、笔试编程类题等专题。

-
有且只有一个根结点 a1 a 1 a_1,它无前件;
-
有且只有一个终端结点 an a n a_n,它无后件;
-
除根结点与终端结点外,其他所有结点有且只有一个前件,也有且只有一个后件。线性表中结点的个数 n n n 称 为线性表的长度。当 n=0n=0n=0 时称为空表。
栈
栈实际上也是一个线性表,只不过是一种特殊的线性表。栈是只能在表的一端进行插入和删除运算的线性表,通常称插入、删除这一端为栈顶(TOP),另一端为栈底(BOTTOM)。当表中没有元素时称为栈空。 栈顶元素总是后被插入(入栈)的元素,从而也是最先被移除(出栈)的元素;栈底元素总是最先被插入的元素,从而也是最后才能被移除的元素。所以栈是个 后进先出(LIFO) 的数据结构
栈的基本运算有三种:入栈、出栈与读栈顶,时间复杂度都是 O(1) O ( 1 ) O(1)
队列
队列是只允许在一端删除,在另一端插入的顺序表,允许删除的一端叫做队头,用对头指针 front f r o n t front 指向对头元素的下一个元素,允许插入的一端叫做队尾,用队尾指针 rear r e a r rear 指向队列中的队尾元素,因此,从排头指针 front f r o n t front 指向的下一个位置直到队尾指针 rear r e a r rear 指向的位置之间所有的元素均为队列中的元素。
队列的修改是 先进先出(FIFO) 。往队尾插入一个元素称为入队运算。从对头删除一个元素称为退队运算。
队列主要有两种基本运算:入队运算和退队运算,复杂度都是 O(1) O ( 1 ) O(1)
循环队列
在实际应用中,队列的顺序存储结构一般采用循环队列的形式。所谓循环队列,就是将队列存储空间的最后一个 位置绕到第一个位置,形成逻辑上的环状空间。在实际使用循环队列时,为了能区分队满还是队列空,通常需要增加一个标志 S S S。
循环队列主要有两种基本运算:入队运算和退队运算,复杂度都是O(1)O(1)O(1)
- 入队运算
指在循环队列的队尾加入一个新元素,首先 rear=rear+1 r e a r = r e a r + 1 rear=rear+1, 当 rear=m+1 r e a r = m + 1 rear=m+1 时,置 rear=1 r e a r = 1 rear=1,然后将新元素插入到队尾指针 指向的位置。当 S=1,rear=front S = 1 , r e a r = f r o n t S=1, rear=front,说明队列已满,不能进行入队运算,称为“上溢”。
- 退队运算
指在循环队列的排头位置退出一个元素并赋给指定的变量。首先 front=front+1 f r o n t = f r o n t + 1 front=front+1, 并当 front=m+1 f r o n t = m + 1 front=m+1 时,置 front=1 f r o n t = 1 front=1, 然后 将排头指针指向的元素赋给指定的变量。当循环队列为空 S=0 S = 0 S=0,不能进行退队运算,这种情况成为“下溢”。
非线性逻辑结构
树
树是一种简单的非线性结构。树型结构具有以下特点:
-
每个结点只有一个前件,称为父结点,没有前件的结点只有一个,称为树的根结点。
-
每一个结点可以有多个后件结点,称为该结点的子结点。没有后件的结点称为叶子结点
-
一个结点所拥有的后件个数称为结点的度
-
树的最大层次称为树的深度。
二叉树
二叉树是一种树型结构,通常采用链式存储结构,满足以下特性:
-
它的特点是每个结点至多只有二棵子树(即二叉树中不存在度大于 2 的结点);
-
二叉树的子树有左右之分,其次序不能任意颠倒。
二叉树的基本性质
-
在二叉树的第 i i i 层上至多有 2i−12i−12i-1 个结点
-
深度为 k k k 的二叉树至多有 2k−12k−12k-1 个结点( k≥1 k ≥ 1 k \geq 1)
-
在任意一个二叉树中,度为 0 的结点总是比度为 2 的结点多一个
-
具有 N N N 个结点的二叉树,其深度至少为 ⌊log2N⌋+1⌊log2N⌋+1\lfloor log_2 N \rfloor+1
-
霍夫曼树的带权路径长度 len=2n+1 l e n = 2 n + 1 len = 2n+1; n n n 为所以叶子权重和。
二叉树的遍历
就是遵从某种次序,访问二叉树中的所有结点,使得每个结点仅被访问一次。分为以下几种:
-
前序遍历(DLR): 首先访问根结点,然后遍历左子树,最后遍历右子树。
-
中序遍历(LDR): 首先遍历左子树,然后根结点,最后右子树
-
后序遍历(LRD): 首先遍历左子树,然后遍历右子树,最后访问根结点。
此外图的遍历也可以用在树上,包括:
-
广度优先遍历(层序遍历): 从根结点开开始逐层向下,从左到右遍历。
-
深度优先遍历: 从根结点出发沿左子树遍历到叶子结点再逐层向上向遍历右子树。
除此之外还有很多有特点的特殊二叉树:
- 满二叉树:除最后一层以外,每一层上的所有结点都有两个子结点。
- 在满二叉树的第 KKK 层上有 2K−1 2 K − 1 2^{K-1} 个结点,且深度为 M M M 的满二叉树有 2M−12M−12M-1 个结点
- 完全二叉树:除最后一层以外,每一层上的结点数均达到最大值;在最后一层上只缺少右边的若干结点。
- 具有 N N N 个结点的完全二叉树的深度为 ⌊log2N⌋+1⌊log2N⌋+1\lfloor log_2 N \rfloor+1
- 完全二叉树总结点数为 N N N,则叶子结点数为⌈N/2⌉⌈N/2⌉\lceil N/2 \rceil
堆
最常见的完全二叉树就是 **堆** 了。堆满足以下条件
-
堆中某个结点的值总是不大于或不小于其父结点的值
-
堆总是一棵完全二叉树
将根结点最大的堆叫做 最大堆 或 大根堆 ,根结点最小的堆叫做 最小堆 或 小根堆 。
堆具有以下基本操作:
-
插入: 向堆中插入一个新元素
-
获取: 获取当前堆顶元素的值
-
删除: 删除堆顶元素
-
包含: 判断堆中是否存在某个元素
哈希表
常用的哈希函数
-
直接寻址法: H(k) H ( k ) H(k) 是一个线性函数,如果该位置已经有值就向下寻找到第一个空的地方作为散列地址
-
平方取中法: 取 k k k 平方以后值的中间几位作为散列地址
-
数字分析法: 对于比较规律的 kkk 值,找出其差异较大的部分作为散列地址
-
折叠法: 将 k k k 分成很多部分,然后做模二和作为散列地址
-
留余数法: H(k)=kH(k)=kH(k)=k % p, p \leq m,其中 p p p 为素数,mmm 为表的长度
-
随机数法: 取键字的随机值作为散列地址,关键字长度时使用
实现映射的函数是哈希函数,简单的 hash 可能会发生碰撞(不同输入得到相同输出),为了防止碰撞,考虑以下方法:
-
链地址法(拉链法): 当发生碰撞时,将发生碰撞的数据元素连接到同一个单链表中,而新元素插入到链表的前端
-
线性探针法: 线性探针法地址增量 d∈D1={1,2,3,…,m−1} d ∈ D 1 = { 1 , 2 , 3 , . . . , m − 1 } d \in D_1 = \{1,2,3, … , m-1\}, i i i 为探测次数,mmm 为表的长度,该方法遇到冲突地址会依次探测下一个地址( d=di+1 d = d i + 1 d = d_i + 1)直到有空的地址,若找不到空地址,则溢出。
平均查找长度
- 线性探针法平均长度推算(其中 m m m 为表中数据长度,nnn 为表长度):
ASLs=∑mi=1dim A S L s = ∑ i = 1 m d i m ASL_s=\frac{\sum_{i=1}^m d_i}{m},查找成功
ASLu=∑ni=1din A S L u = ∑ i = 1 n d i n ASL_u=\frac{\sum_{i=1}^n d_i}{n},查找不成功
注:线性探针法查找成功时 di d i d_i 为每次放入元素时的地址增量,不成功时 di d i d_i 为在表长度内依次查找每个元素到下一个空地址的地址增量(索引在表长度内循环)
- 链地址法平均长度推算(其中 k k k 为最长链长度,其中 mmm 为表中数据长度, n n n 为表长度):
ASLs=∑ki=1(当前级指针数量×当前级数)mASLs=∑i=1k(当前级指针数量×当前级数)mASL_s=\frac{\sum_{i=1}^k ({当前级指针数量} \times {当前级数})}{m},查找成功
ASLu=∑ni=1当前个位置链长度n A S L u = ∑ i = 1 n 当 前 个 位 置 链 长 度 n ASL_u=\frac{\sum_{i=1}^n {当前个位置链长度}}{n},查找不成功
哈希表相关特性
-
线性探针法容易“聚集”,影响查找效率,而链地址法不会
-
链地址法适应表长不确定情况
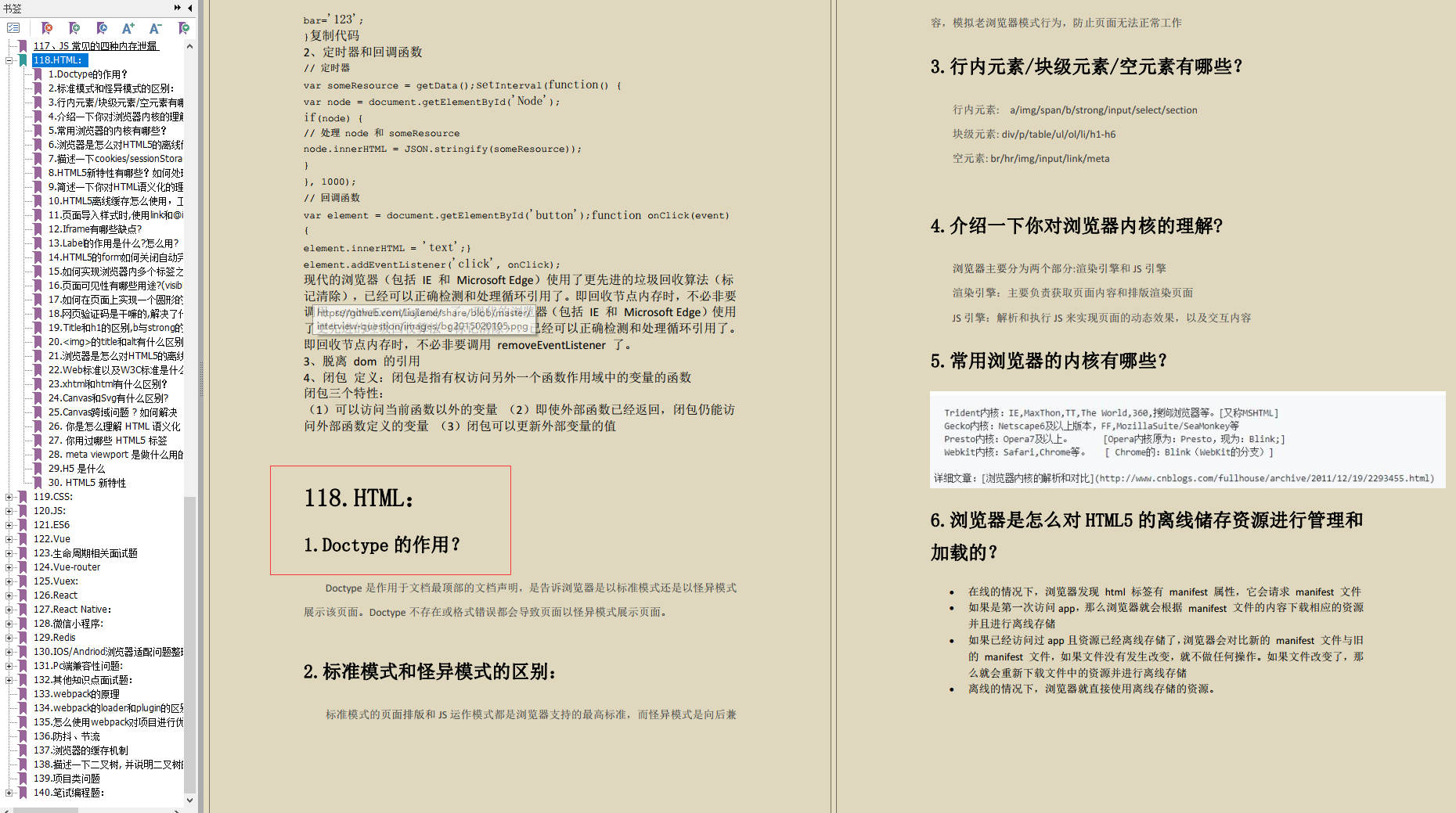
-
装填因子(α)=哈希表中的记录数哈希表的长度 装 填 因 子 ( α ) = 哈 希 表 中 的 记 录 数 哈 希 表 的 长 度 装填因子(\alpha)=\frac{哈希表中的记录数}{哈希表的长度}
图
图有两种定义:
-
二元组的定义:图 G G G 是一个有序二元组 (V,E)(V,E)(V,E),其中 V V V 称为顶集(Vertices Set),EEE 称为边集(Edges set), E E E 与 VVV 不相交。它们亦可写成 V(G) V ( G ) V(G) 和 E(G) E ( G ) E(G) 。 E E E 的元素都是二元组,用 (x,y)(x,y)(x,y) 表示,其中 x,y∈V x , y ∈ V x,y \in V
-
三元组的定义: 图 G G G 是指一个三元组(V,E,I)(V,E,I)(V,E,I),其中 V V V 称为顶集,EEE 称为边集, E E E 与 VVV 不相交; I I I 称为关联函数,III 将 E E E 中的每一个元素映射到V×VV×VV \times V。如果 e e e 被映射到 (u,v)(u,v)(u,v),那么称边 e e e 连接顶点 u,vu,vu,v,而 u,v u , v u,v 则称作 e e e 的端点,u,vu,vu,v 此时关于 e e e 相邻。同时,若两条边 i,ji,ji,j 有一个公共顶点 u u u,则称 i,ji,ji,j 关于 u u u 相邻。
图的分类
图有不同的分类规则,具体如下:
分类1
- 有向图: 如果图中顶点之间关系不仅仅是连通与不连通,而且区分两边的顶点的出入(存在出边和入边),则为有向图。
- 无向图: 如果图中顶点之间关系仅仅是连通与不连通,而不区分两边顶点的出入(不存在出边和入边),则为无向图。
单图
分类2
- 有环图: 单向遍历回可以到已遍历的点,比如有环链表
- 无环图: 单向遍历不能回到已遍历的点,比如树
分类3
- 带权图: 图的具有边带有关于该边信息的权值,比如地图中两点间距离
- 无权图: 图的每个边都不具有有关于该边信息的权值,其仅表示是否连通
其他
- 单图: 一个图如果任意两顶点之间只有一条边且边集中不含环,则称为单图
图的表示采用邻接矩阵和类似树的形式(顶点指针域是个指针数组)的形式,其具有以下特点:
-
无向图的邻接矩阵是对称矩阵
-
带权图的矩阵中元素为全职,无权图中用0/1分别表示不连通/连通
-
主对角线有不为零元素,该图一定有环
图的遍历
-
广度优先遍历: 广度优先遍历是连通图的一种遍历策略。因为它的思想是从一个顶点 V0V0V_0 开始,辐射状地优先遍历其周围较广的区域。
-
深度优先遍历:
图的相关性质:
-
N N N 个顶点的连通图中边的条数至少为 N−1N−1N-1
-
N N N 个顶点的强连通图的边数至少有 NNN
-
广度优先遍历用来找无权图最短路径(有权图其实也行,多点东西呗)
简单数据结构的增删改查
| 操作 | 添加 | 删除 | 查找 | 使用条件 |
| — | — | — | — | — |
| 数组 | O(n) O ( n ) O(n) | O(n) O ( n ) O(n) | O(n) O ( n ) O(n) | 数定下标 |
| 链表 | O(1) O ( 1 ) O(1) | O(n) O ( n ) O(n) | O(n) O ( n ) O(n) | 两端修改 |
| 变长数组 | O(1) O ( 1 ) O(1) | O(n) O ( n ) O(n) | O(n) O ( n ) O(n) | 数不定下标 |
| 栈 | O(1) O ( 1 ) O(1) | O(1) O ( 1 ) O(1) | - | LIFO |
| 队列 | O(1) O ( 1 ) O(1) | O(1) O ( 1 ) O(1) | - | FIFO |
| 哈希表 | O(1) O ( 1 ) O(1) | O(1) O ( 1 ) O(1) | O(1) O ( 1 ) O(1) | key操作,无序 |
| 树字典 | O(log2n) O ( l o g 2 n ) O(log_2 n) | O(log2n) O ( l o g 2 n ) O(log_2 n) | O(log2n) O ( l o g 2 n ) O(log_2 n) | key操作,有序 |
| 哈希集合 | O(1) O ( 1 ) O(1) | O(1) O ( 1 ) O(1) | O(1) O ( 1 ) O(1) | 唯一值,无序 |
| 树集合 | O(log2n) O ( l o g 2 n ) O(log_2 n) | O(log2n) O ( l o g 2 n ) O(log_2 n) | O(log2n) O ( l o g 2 n ) O(log_2 n) | 唯一值,有序 |
算法
==
算法基本概念
-
算法的基本特征:可行性,确定性,有穷性
-
算法的基本要素:算法中对数据的运算和操作、算法的控制结构。
-
算法设计的基本方法:穷举法、动态规划、贪心法、回溯法、递推法、递归法、分治法、散列法,分支限界法。
-
算法设计的要求:正确性、可读性、健壮性、效率与低存储量需求
-
算法的基本结构:顺序、循环、选择
算法复杂度
-
算法的时间复杂度:指执行算法所需要的计算工作量(不代表算法实际需要时间)
-
算法的空间复杂度:执行这个算法所需要的额外内存空间(代表算法实际需要的空间)
复杂度表示方法: 使用大写 O O O 表示:O(n)O(n)O(n)表示时间复杂度时指 n n n 个数据处理完成使用 nnn 个单位的时间;表示空间复杂度时指 n n n 个数据处理完成使用了 nnn 个单位的辅助空间。
字符串算法
字符串算法除了增删改查以外,还有很多匹配算法,比如最耳熟能详的 KMP 算法(不属于基础部分),这里整理一些相关算法的性质:
最后
除了简历做到位,面试题也必不可少,整理了些题目,前面有117道汇总的面试到的题目,后面包括了HTML、CSS、JS、ES6、vue、微信小程序、项目类问题、笔试编程类题等专题。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









