







最后
为了帮助大家更好的了解前端,特别整理了《前端工程师面试手册》电子稿文件。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
…
26 => Z;
27 => AA;
28 => AB;
29 => AC
…
52 => AZ;
53 => BA;
54 => BB
…
// 实现下方函数
function convert(num) { // TODO }
// 测试代码:
const output1 = convert(1);
console.log(output1); // A
const output2 = convert(26);
console.log(output2); // Z
const output3 = convert(53);
console.log(output3); // BA
// 理解 其实,这道题很明显是一道10进制转26进制的题目。 主要需要考虑到2个因素
// 1. 1-26 分别对应 A-Z,没有0;
// 2. 超过26进A。(和原来的满10进1是一个道理)
function convert (columnNumber) {
const arr = [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘I’, ‘J’, ‘K’, ‘L’,‘M’, ‘N’,‘O’,‘P’,‘Q’,‘R’,‘S’,‘T’,‘U’,‘V’,‘W’,‘X’,‘Y’,‘Z’];
// 小于等于26,直接返回
let n = columnNumber;
if (n <= 26) return arr[n - 1];
let res = ‘’;
while (n > 0) {
// n先减1. 因为数组arr 下标是从0开始。 而题目是从1开始
n–;
// 从后往前拼接
res = arr[n % 26] + res;
n = Math.floor(n / 26); // 取整。
}
return res;
};
};
深度优先遍历
先给定一个二叉树数据
const tree = {
value: “-”,
left: {
value: ‘+’,
left: {
value: ‘a’,
},
right: {
value: ‘*’,
left: {
value: ‘b’,
},
right: {
value: ‘c’,
}
}
},
right: {
value: ‘/’,
left: {
value: ‘d’,
},
right: {
value: ‘e’,
}
}
}
如果你有心,应该能看出来,其实这个数据就是个公式:
(a+b∗c)−d/e(a+b*c)-d/e(a+b∗c)−d/e
那开始上代码了,先来一下深度优先遍历(Depth-First Search,DFS)吧。 当你看到代码里有 dfs 字样的时候,你就应该及时反应过来,这里十有八九是有遍历的。
// 深度遍历——先序遍历
// 递归实现
let result = [];
let dfs = function (node) {
if(node) {
result.push(node.value);
dfs(node.left);
dfs(node.right);
}
}
dfs(tree);
console.log(result); // [“-”, “+”, “a”, “*”, “b”, “c”, “/”, “d”, “e”]
/* 思路:
-
先遍历根结点,将值存入数组。
-
然后递归遍历:先左结点,将值存入数组,继续向下遍历;直到(二叉树为空)子树为空,则遍历结束;
-
然后再回溯遍历右结点,将值存入数组,这样递归循环,直到(二叉树为空)子树为空,则遍历结束。
*/
// 非递归实现
let dfs = function (nodes) {
let result = [];
let stack = [];
stack.push(nodes);
while(stack.length) { // 等同于 while(stack.length !== 0) 直到栈中的数据为空
let node = stack.pop(); // 取的是栈中最后一个j
result.push(node.value);
if(node.right) stack.push(node.right); // 先压入右子树 保证先序
if(node.left) stack.push(node.left); // 后压入左子树
}
return result;
}
dfs(tree);
/*思路
step 1. 初始化一个栈,将根节点压入栈中;
step 2. 当栈为非空时,循环执行步骤3到4,否则循环结束,得到最终的结果;
step 3. 从队列取得一个结点(其实是取的是栈顶元素),将该值放入结果数组;
step 4. 若该结点的右子树为非空,则将该结点的右子树入栈。若该结点的左子树为非空,则将该结点的左子树入栈;
(ps:先将右结点压入栈中,后压入左结点,从栈中取得时候是取最后一个入栈的结点,而先序遍历要先遍历左子树,后遍历右子树)
*/
// 深度遍历——中序遍历
// 递归实现
let result = [];
let dfs = function (node) {
if(node) {
dfs(node.left);
result.push(node.value); // 直到该结点无左子树 将该结点存入结果数组 接下来并开始遍历右子树
dfs(node.right);
}
}
dfs(tree);
console.log(result); // [“a”, “+”, “b”, “*”, “c”, “-”, “d”, “/”, “e”]
/思路你一看就看明白了,就是调了个顺序😂😂😂/
// 非递归实现?
function dfs(node) {
let result = [];
let stack = [];
while(stack.length || node) { // 是 || 不是 &&
if(node) {
stack.push(node);
node = node.left;
} else {
node = stack.pop();
result.push(node.value);
node = node.right; // 如果没有右子树 会再次向栈中取一个结点即双亲结点
}
}
return result;
}
dfs(tree);
/*思路:
-
将当前结点压入栈。
-
然后将左子树当做当前结点。
-
如果当前结点为空,则将双亲结点取出来,将值保存入数组。
-
然后将右子树当做当前结点,进行循环。
*/
// 后续遍历。。。 不写了。欢迎小伙伴们自己去写出来。
// 提一下广度优先遍历
let result = [];
let stack = [tree]; // 先将要遍历的树压入栈
let count = 0; // 用来记录执行到第一层
let bfs = function () {
let node = stack[count];
if(node) {
result.push(node.value);
if(node.left) stack.push(node.left);
if(node.right) stack.push(node.right);
count++;
bfs();
}
}
dfc();
console.log(result); // [“-”, “+”, “/”, “a”, “*”, “d”, “e”, “b”, “c”]
/思路: 思路应该一看就明白对伐?/
这年头,面试被问React diff算法有多大概率?
如果说,以前的diff 算法基本上都是 Virtual DOM -> DOM ,那现在的 diff 算法就是 Virtual DOM -> Fiber -> Fiber链表 -> DOM。
你以为面试官不会考虑时间的吗? 所以,问你 Fiber 就是在问你 diff,而你到底是回答diff呢还是Fiber呢? 还是一股脑的都说了?
这里有个小技巧。敲黑板,划重点! 请把Fiber 看作是一道算法题,而算法题首先要搞清楚的事情就是:算法要对应的数据结构。
step 1: 先介绍Fiber对象有哪些属性,其实这就是在介绍数据结构了。 请你挑最核心的属性讲。
step 2: 说清楚Fiber对象怎么来的,也就是如果构建Fiber对象。
step 3: Fiber链表如何构建。
step 4: 如何渲染真实DOM
到底什么是Fiber?
Fiber 是一个执行单元
在 React 15 中,将 VirtualDOM 树整体看成一个任务进行递归处理,任务整体庞大执行耗时且不能中断。
在 React 16 中,将整个任务拆分成了一个一个小的任务进行处理,每一个小的任务指的就是一个 Fiber 节点的构建。
任务会在浏览器的空闲时间被执行,每个单元执行完成后,React 都会检查是否还有空余时间,如果有就交还主线程的控制权。
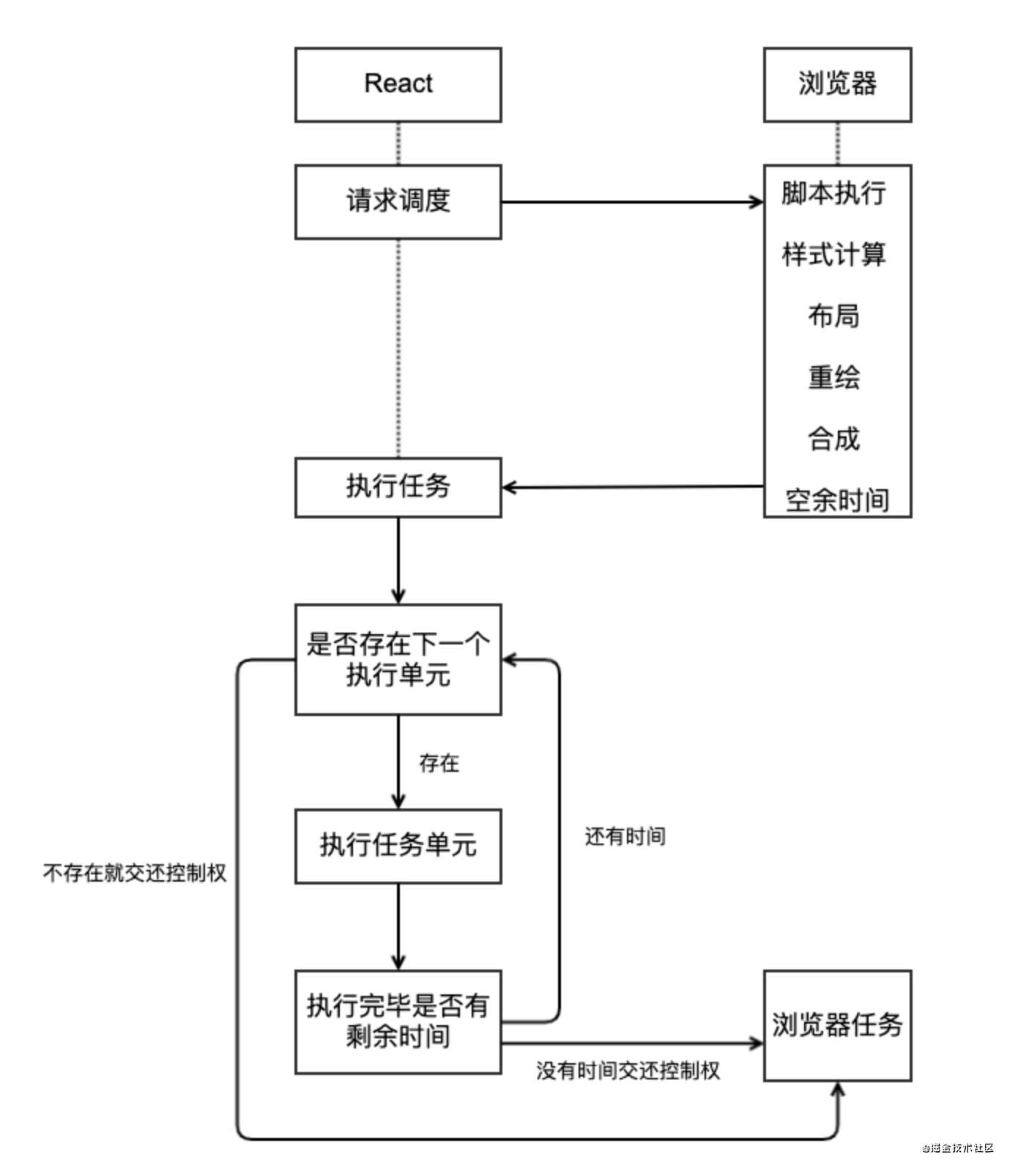
// 哦哈呦,我帮你把Fiber对象身上挂的属性尽量给你列出来了。 恐怖不? 😱 头皮发麻不
type Fiber = {
/************************ DOM 实例相关 *****************************/
// 标记不同的组件类型, 值详见 WorkTag
tag: WorkTag,
// 组件类型 div、span、组件构造函数
type: any,
// 实例对象, 如类组件的实例、原生 dom 实例, 而 function 组件没有实例, 因此该属性是空
stateNode: any,
/************************ 构建 Fiber 树相关 ***************************/
// 指向自己的父级 Fiber 对象
return: Fiber | null,
// 指向自己的第一个子级 Fiber 对象
child: Fiber | null,
// 指向自己的下一个兄弟 iber 对象
sibling: Fiber | null,
// 在 Fiber 树更新的过程中,每个 Fiber 都会有一个跟其对应的 Fiber
// 我们称他为 current <==> workInProgress
// 在渲染完成之后他们会交换位置
// alternate 指向当前 Fiber 在 workInProgress 树中的对应 Fiber
alternate: Fiber | null,
/************************ 状态数据相关 ********************************/
// 即将更新的 props
pendingProps: any,
// 旧的 props
memoizedProps: any,
// 旧的 state
memoizedState: any,
/************************ 副作用相关 ******************************/
最后
为了帮助大家更好的了解前端,特别整理了《前端工程师面试手册》电子稿文件。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









