







学习笔记
主要内容包括html,css,html5,css3,JavaScript,正则表达式,函数,BOM,DOM,jQuery,AJAX,vue等等
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
HTML/CSS
**HTML:**HTML基本结构,标签属性,事件属性,文本标签,多媒体标签,列表 / 表格 / 表单标签,其他语义化标签,网页结构,模块划分
**CSS:**CSS代码语法,CSS 放置位置,CSS的继承,选择器的种类/优先级,背景样式,字体样式,文本属性,基本样式,样式重置,盒模型样式,浮动float,定位position,浏览器默认样式

HTML5 /CSS3
**HTML5:**HTML5 的优势,HTML5 废弃元素,HTML5 新增元素,HTML5 表单相关元素和属性
**CSS3:**CSS3 新增选择器,CSS3 新增属性,新增变形动画属性,3D变形属性,CSS3 的过渡属性,CSS3 的动画属性,CSS3 新增多列属性,CSS3新增单位,弹性盒模型

JavaScript
**JavaScript:**JavaScript基础,JavaScript数据类型,算术运算,强制转换,赋值运算,关系运算,逻辑运算,三元运算,分支循环,switch,while,do-while,for,break,continue,数组,数组方法,二维数组,字符串

我们创建HTML文件,Live server打开
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<button id="btn">添加</button>
</body>
<script>
let tempEle
function test(){
let ul = document.createElement("ul")
for(let i=0;i<10;i++){
let li =document.createElement("li")
ul.appendChild(li)
}
tempEle = ul
}
btn.onclick=test
</script>
</html>
这次点击内存,我们先不做任何操作,直接点击右上角开始快照,contructor是我们当前活动对象的所有展示,之后再点击一下按钮,再次点击开启快照,在filter中输入 deta 观察两次的活动对象, 在第一次的活动对象中是不存在的,但是在第二次,出现了两个活动对象,这些就是我们创建的dom节点,我们没有添加到界面上,但是却存在在这个内存空间里,就是空间上的浪费,通过堆快照的功能,来找到脚本里面所存在的问题,存在分离dom。
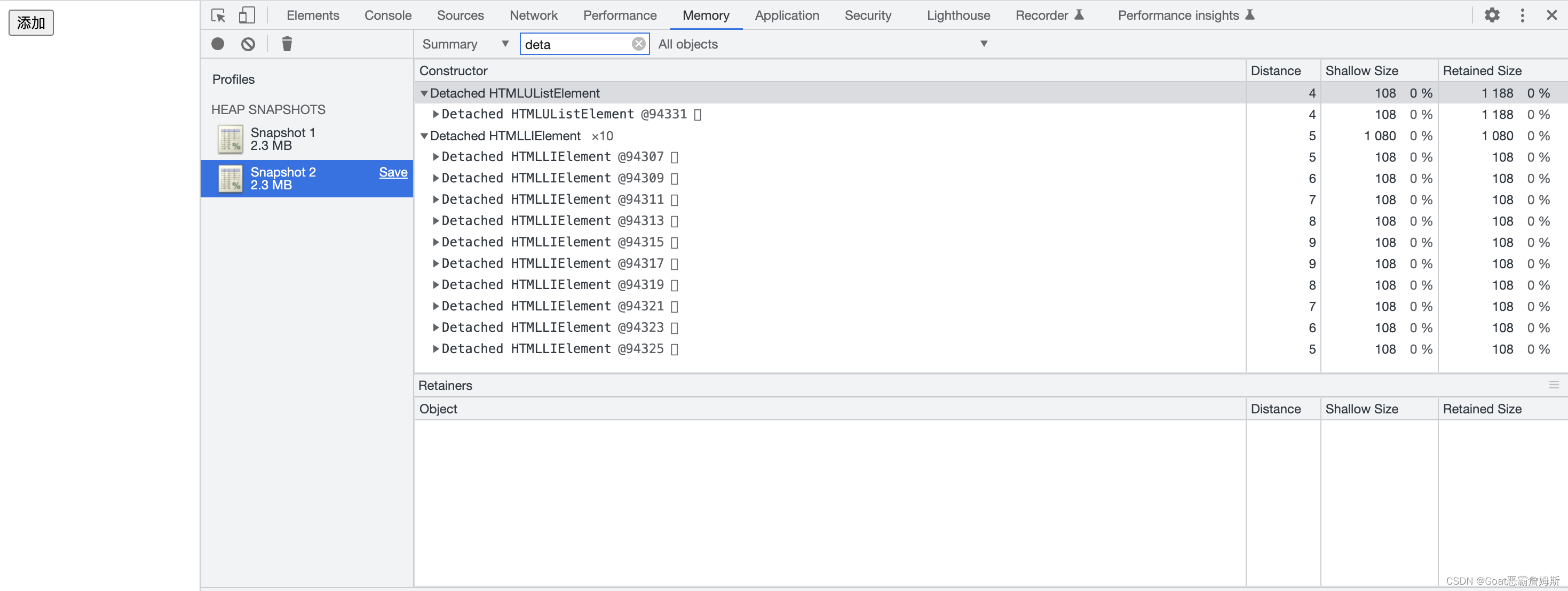
这种情况下怎么解决呢?回到代码,将当前的节点清空即可。
tempEle = null
判断是否存在频繁地垃圾回收:需要借助不同的工具来获取当前内存的一个走势图,然后进行时间段的一个分析,从而得到判断。
为什么要去判断这个呢?因为在GC工作的时候,当前的应用程序是停止的,如果GC频繁地工作,时间过长,对于web应用就很不友好,会处于一个假死的状态,对于用户来说就会感到卡顿,所以要确定是否当前应用在使用时存在频繁地垃圾回收。通过两种方式来判断:
- Timeline中频繁的上升下降:如果蓝色js内存走势条一直往上瞬间往下,然后再很短的时间内重复这样的操作,也就是上去下来,上去下来,中间时间间隔很短,则意味着它一直在做频繁地垃圾回收,出现这样的情况后,必须要定位到相应的时间节点,然后看看具体是什么操作导致了这样的现象产生,接着回到代码进行处理就可以了。
- 任务管理器中数据频繁地增加减小:显示会更加简单,就是一个数值的变化,正常来说,当页面完成渲染后,没有其他的操作,无论是dom内存,还是js内存都应该是一个无变化的数值或者变化很小,如果存在频繁的GC回收时,就会瞬间增大,瞬间减小,所以如果是这样的话,就是存在频繁的gc回收,带来的问题就是,用户会感到卡顿,但从内部来说,代码存在一些对内存操作不当的行为,让我们当前GC不断地进行工作来回收释放相应的空间。
V8引擎的工作流程:
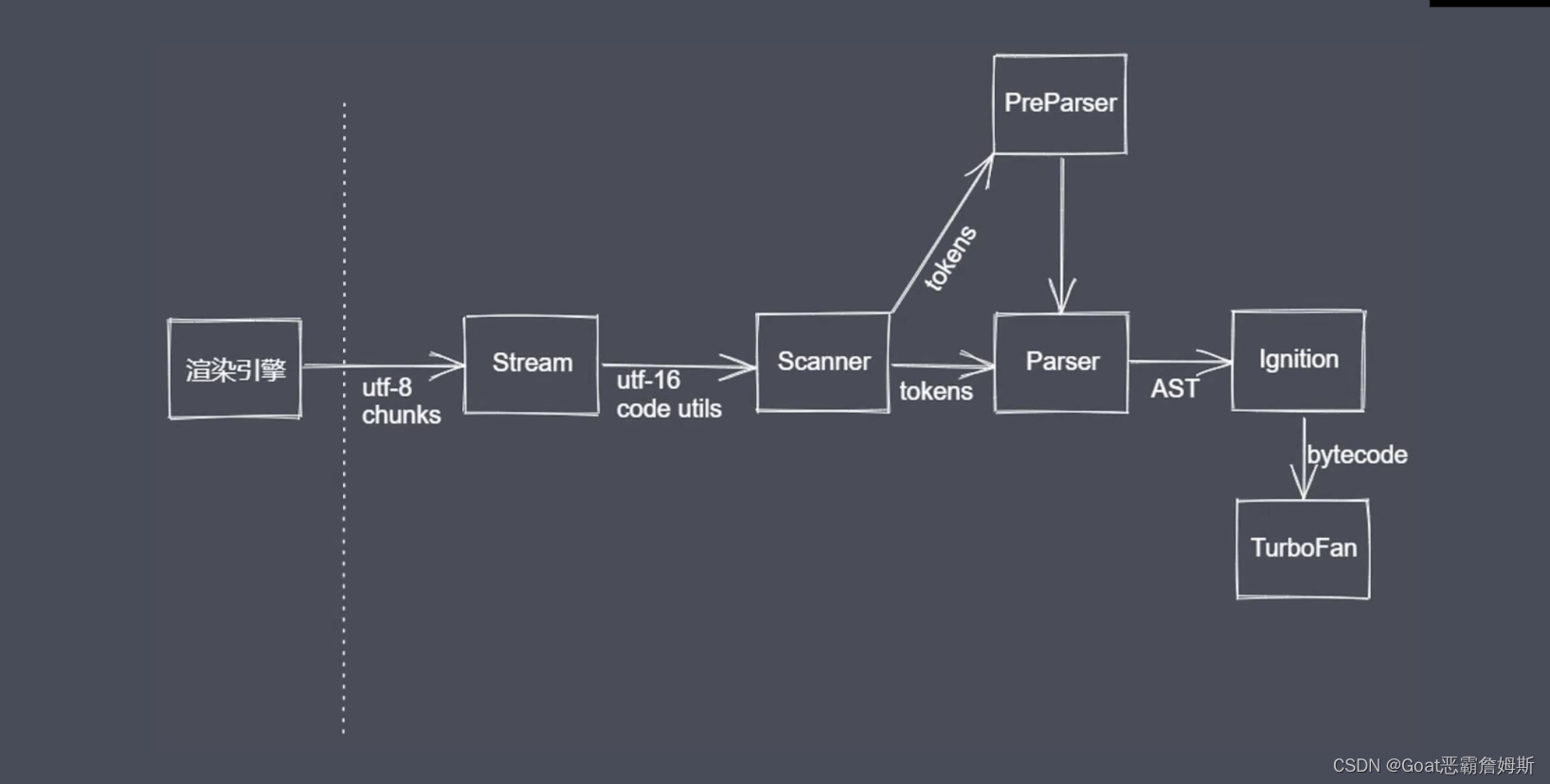
本身是个引用程序,也是js的运行环境,在浏览器中用于解析和编译js代码 ,内部也存在很多的子模块,如图scanner是一个扫描器,对纯文本的js代码进行词法的分析,把代码分子成不同的tokens,会得到一个词语的单元,指在语法上没有办法再分割的最小单位,可能是一个单个字符,也可能是字符串,例如:
const username= "Hello"
扫描后大概是下面的样子,当然只是形象的表示,并不代表就是这样子的:
[
{
"type":"Keyword",
"value":"const"
},
{
"type":"Identifier",
"value":"username"
},
{
"type":"Punctuator",
"value":"="
},
{
"type":"String",
"value":"Hello"
}
]
下面就到了Parser解析器, 把上述词法分析出的tokens转换成抽象的ast语法树,同时也会做语法校验,如果有错就会抛出错误。如下:
{
"type":"Program",
"body":[
{
"type":"VariableDeclaration",
"declarations":[
"type":"VariableDeclarator",
"id":{
"type":"identifier",
"name":"username"
},
"init":{
"type":"Literal",
"value":"Hello",
"raw":"Hello",
},
],
"kind":"const"
}
],
"sourceType":"script"
}
parser的解析有两种情况,预解析preparser和全量解析parser。
preparser:比如在代码中我们声明了很多变量,但并没有每个都使用,此时如果做全量解析,要转为字节码等,但我们最后又不去执行,会有很多无用功,所以有了预解析,会跳过未被使用的代码,不会生成ast,但会产生一些相应的scope信息,这些信息没有变量的引用和声明,因为在这里并不是真正的执行。但是作用域的信息,我们这里是有的,同时也会依据规范来抛出特定的错误,不是全量解析,所以不会全部抛出,解析速度会更快,因为做的事情会少一些。如下:
function fn1(){
console.log('fn1')
}
function fn2(){
console.log('fn2')
}
fn2()
fn1没有被执行,那么fn1就是预解析, 不会生成ast,但仍然会生成作用域的信息。
parser全量解析:会立即解析所有立即执行的代码,会生成相应的ast语法树,同样也会确定更多的信息,其实对应着我们执行上下文的创建,内存中构建具体scopes(作用域),scopes chain信息,变量引用,声明等,这些都是在预解析和解析阶段完成的,但此时代码是并未执行的,会抛出所有的错误。分析一段代码:
// 声明时未被调用,因此会被认为是不会被执行的代码,进行预解析
function foo(){
console.log('foo')
}
// 声明时未调用,因此会被认为是不会被执行的代码,进行预解析
function fn(){
console.log('fn2')
}
//函数立即执行,只进行一次全量解析
(function bar(){
console.log('fn2')
})()
// 执行foo,那么再对foo进行全量解析,此时foo函数被解析了两次
foo()
如果我们在foo函数中再声明一个函数,那么还是一样会执行预解析,然后调用时全量解析,解析了两次,所以嵌套层级太深也会导致多次的解析操作,因此书写代码也要减少不必要的函数嵌套。
ignition :是V8提供的一个解释器
把之前生成的抽象的ast语法树把它转变为字节码bytesCode,同时收集在下个编译阶段需要的一些信息,可以把这个过程看作是预编译的过程,不过基于性能考虑,其实不会把编译和预编译区分特别明显,因为有些代码在预编译就可以直接执行。
TurboFan :是V8提供的编译器模块,利用上个阶段收集到的信息,把这些字节码来转化为我们具体的汇编代码,之后可以开始代码执行,也就是后续需要理解和分析的堆栈执行过程。
堆栈操作
分析堆栈方面的处理操作的主要目的是可以本质上分析一段代码的执行过过程,另一方面后续如果想要分析一段代码执行时所涉及到性能问题,可以从堆栈层面上考虑一下执行流程,可以看看性能消耗。
js代码在执行时一定需要一个环境,浏览器下面会有它自己的js执行引擎比如说V8,代码最终会被转为可以被识别的机器码,那这些字符串类型的机器码具体是在哪里执行呢?这块会用到环境执行栈(ECStack,execution context stack),浏览器在渲染界面的时候,会去在计算机的内存当中开辟一个内存空间,专门来用于执行js代码,而这个栈内存就是我们所说的执行环境栈,但是不同的区域又要保持互相的独立,不能相互影响,全局执行上下文管理全局的代码执行,某一个私有的执行上下文管理它自己的局部代码,这样就可以区分不同的区域代码执行了。
以全局执行上下文为例:
在全局执行上下文当中,可能会同时存在很多个变量声明,这些内容又存在哪里呢?底层给出了一个VO(G)的全局变量对象,它肯定占据了一片空间,我们就认为所有的变量的声明都被放在这个对象中所占据的空间里,有了这些之后全局里的代码就可以进栈执行了。例如我们连续调用多个函数,但是无论怎么操作,全局的执行上下文都是存在的,因此在这个栈底永远都有一个ECG——全局执行上下文。
而代码的执行步骤,针对全局来说,肯定要做编译,包含之前所提到的词法分析,语法分析,预解析的过程等,接下就是代码执行了,如图:
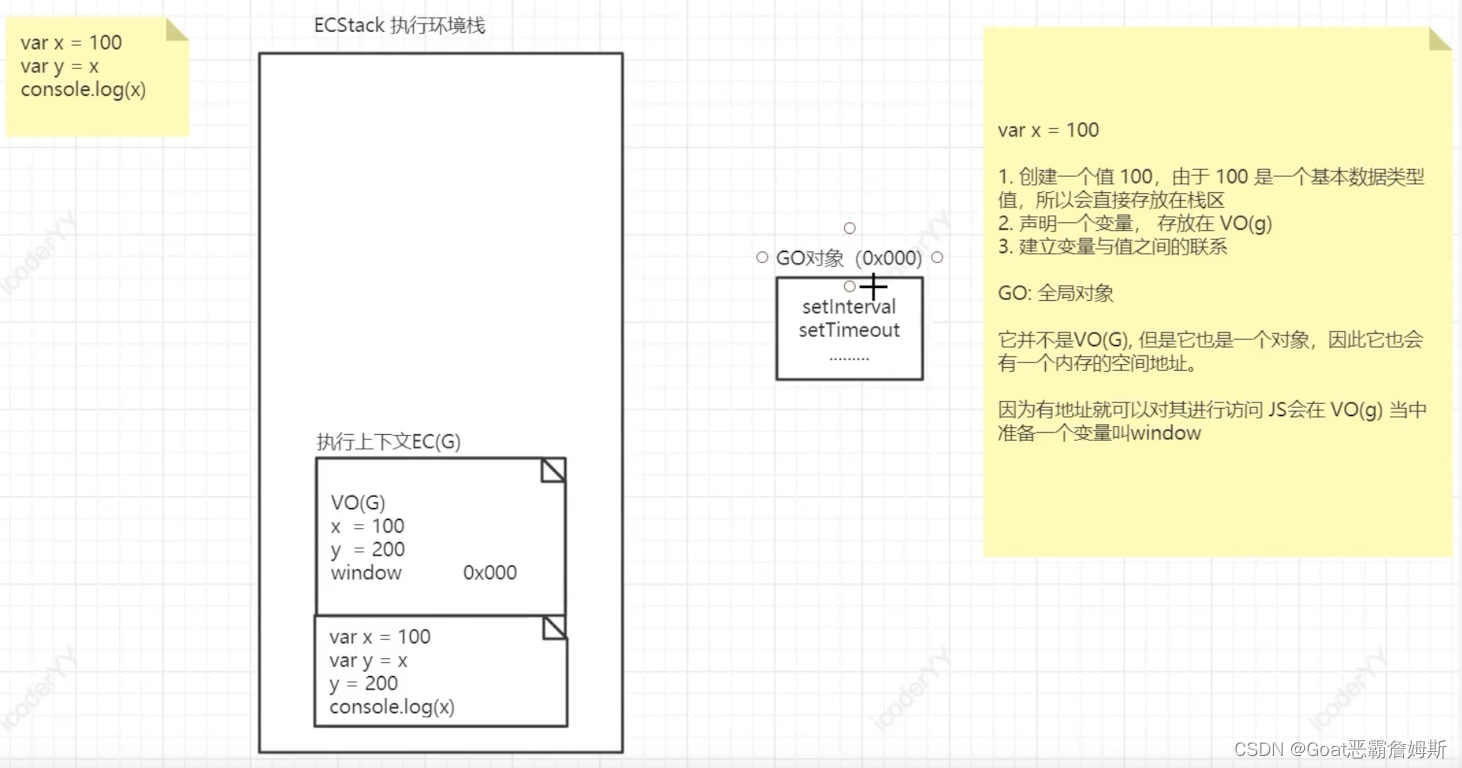
ECStack全局执行栈就是在浏览器申请开辟的内存空间,代码编译前会有个进入执行环境站栈的操作,x,y是属于全局执行上下文中,被存放在全局变量对象VO(G)中,先创建一个值,比如创建100,100是基本数据类型,会放在栈区,然后再声明一个变量x,存放在VO(G),最后建立值与变量的联系,同理在VO(G)里面会再创建y,也同样与100建立联系。
在执行完毕后出站,然后创建的值和声明的变量都会被释放掉,但是变量有可能引用了另外的对象地址,那么被引用的对象不一定会被释放掉。
总结:
基本数据类型都是按值操作
基本数据类型值存放在栈内存
栈内存和堆内存(引用数据用的)都属于计算机内存,如果用的太多对我们的使用会有性能的影响。
GO:全局对象,它并不是VO(G),但也是个对象,因此也会有一个内存的空间地址。
js会在VO(G)中准备一个变量叫window,可以直接通过window访问GO的全局对象,对应的栈区里存的只是一个地址,指向GO全局对象。
引用类型堆栈操作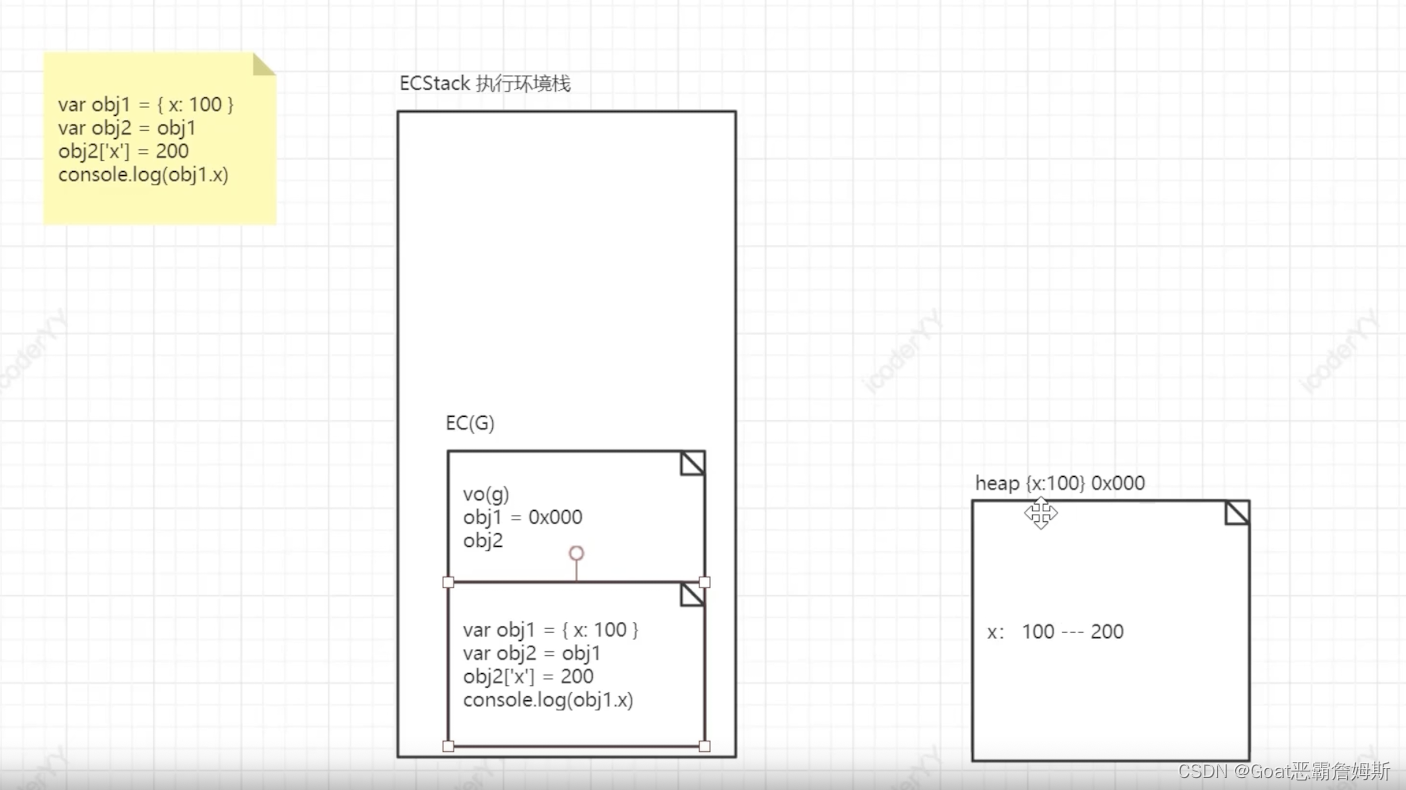 在全局执行上下文执行时还是一样,会先在全局变量VO(G)中创建变量,然后在堆内存中创建对象数据,地址以十六进制表示,在全局变量对象中建立数据联系,obj1所指向的是其实就是数据所在堆内存中的地址。obj2也是指向相同的地址,obj2修改x的值,因为是个地址引用,所以会在对应的堆内存中找到x并且改值,在这里obj1的x属性也会改变。
在全局执行上下文执行时还是一样,会先在全局变量VO(G)中创建变量,然后在堆内存中创建对象数据,地址以十六进制表示,在全局变量对象中建立数据联系,obj1所指向的是其实就是数据所在堆内存中的地址。obj2也是指向相同的地址,obj2修改x的值,因为是个地址引用,所以会在对应的堆内存中找到x并且改值,在这里obj1的x属性也会改变。
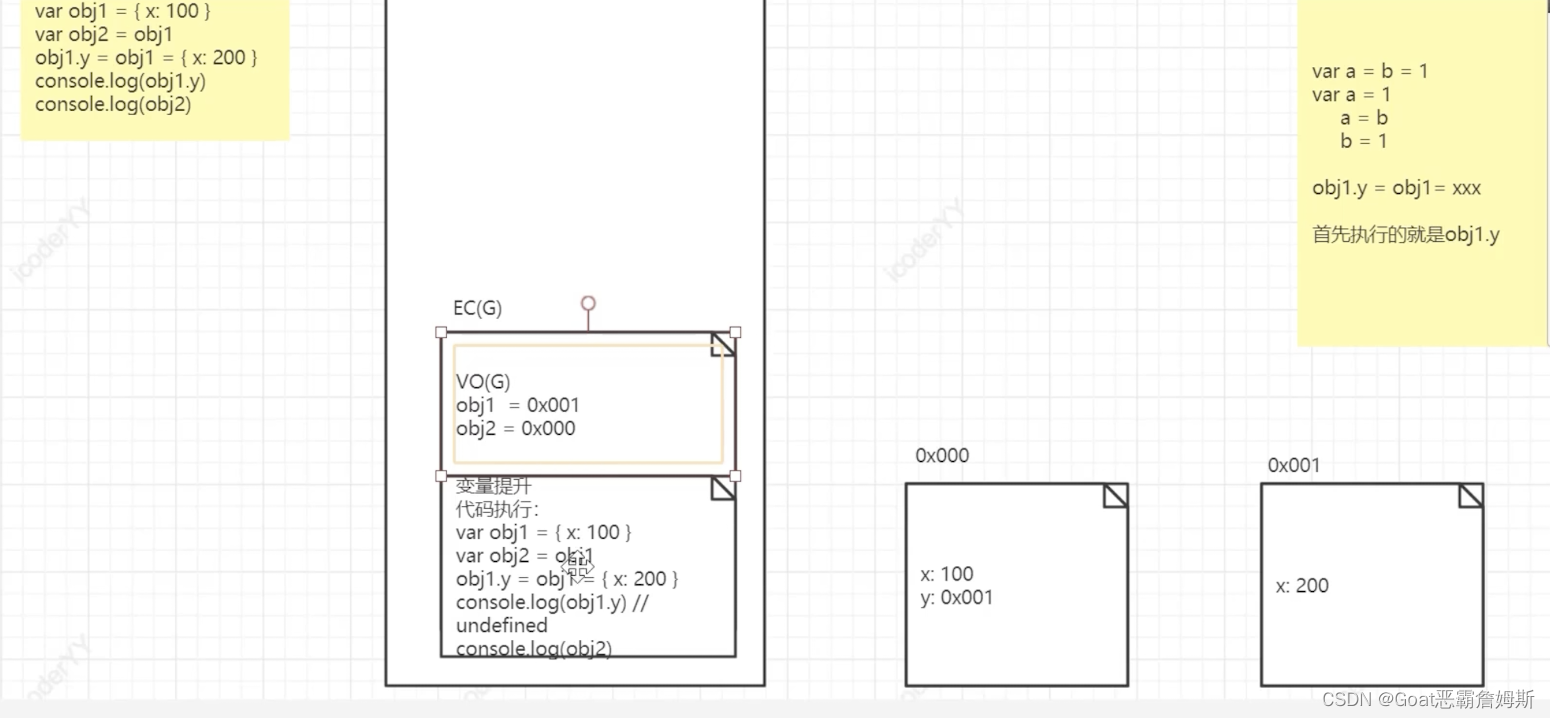
重复的就不再赘述,在这里比较难理解的是obj1.y先执行,创建新内存指向0x001,obj1指向为0x000,再执行obj1={x:200},此时obj的指向1已经改变了为0x001,那么此时0x001并不存在y属性,所以打印为undefined,obj2的引用地址为0x000那么此时,obj2是含有y属性的。
函数堆栈处理
对于函数的处理会有稍微的不同,在全局创建一个函数,那么在全局变量对象中会声明变量,同时在堆内存创建空间存储函数,也是以十六进制地址的形式来表示,内容是以字符串的形式存储,但是函数的地址会被保存在栈内存中,调用时直接通过地址访问函数,创建函数时就已经确定了它的作用域,也就是创建函数时所在的执行上下文,全局创建作用域就是全局执行上下文。
函数执行,就是将堆内存中的字符串形式的代码执行,执行过程中会生成一个新执行上下文来管理函数体当中的代码,私有执行上下文EC,其中就包括当前上下文中的变量区域AO,具体包括:
1.确定作用域链,包括当前执行上下文,上级执行上下文。
2.确定this的指向,全局指向window。
3.初始化argumens对象。
4.形参赋值,也就是变量声明,会存储在AO中,变量的储存的方式与上述全局的一致。
5.变量提升,有使用var的话。
6.执行代码。
执行结束后,出栈释放,在局部作用域内的变量会被释放,但是堆内存的地址还是存在的,只是断了与局部变量之间的引用关系,其他的地方还是会正常引用。
闭包堆栈处理
函数的处理基本不变,但是出现了父子函数,父子函数的处理也都是相同的,在代码执行完毕之后,正常情况下是要出栈的,如果把父函数释放了,那么子函数也被释放了,但是子函数被外部的变量引用着,那么就会存在变量找不到值的问题,所以当前的父函数是不能释放的,创建的执行上下文不能被释放,这就是闭包的现象。执行完毕后,子函数的变量以及作用域会得到释放。
闭包是一种机制,通过私有上下文来保护当中变量的机制。我们也可以认为当我们创建的某一个执行上下文不被释放的时候就形成了闭包,可以起到保护,保存数据。
闭包垃圾回收
浏览器都自有垃圾回收(内存管理,V8为例)
释放对空间和栈空间,栈空间的数据如果外部没有引用,就会被释放掉,当前堆内存如果被引用,就不能被释放,如果后续不再使用内存里的数据,也可以自己主动释放置空,浏览器就会对其回收。
当前上下文中是否有内容,被其他上下文的变量所占用,如果有则无法释放(闭包),我们置空即可(置为null)
学习笔记
主要内容包括html,css,html5,css3,JavaScript,正则表达式,函数,BOM,DOM,jQuery,AJAX,vue等等
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
HTML/CSS
**HTML:**HTML基本结构,标签属性,事件属性,文本标签,多媒体标签,列表 / 表格 / 表单标签,其他语义化标签,网页结构,模块划分
**CSS:**CSS代码语法,CSS 放置位置,CSS的继承,选择器的种类/优先级,背景样式,字体样式,文本属性,基本样式,样式重置,盒模型样式,浮动float,定位position,浏览器默认样式

HTML5 /CSS3
**HTML5:**HTML5 的优势,HTML5 废弃元素,HTML5 新增元素,HTML5 表单相关元素和属性
**CSS3:**CSS3 新增选择器,CSS3 新增属性,新增变形动画属性,3D变形属性,CSS3 的过渡属性,CSS3 的动画属性,CSS3 新增多列属性,CSS3新增单位,弹性盒模型
JavaScript
**JavaScript:**JavaScript基础,JavaScript数据类型,算术运算,强制转换,赋值运算,关系运算,逻辑运算,三元运算,分支循环,switch,while,do-while,for,break,continue,数组,数组方法,二维数组,字符串

单相关元素和属性
**CSS3:**CSS3 新增选择器,CSS3 新增属性,新增变形动画属性,3D变形属性,CSS3 的过渡属性,CSS3 的动画属性,CSS3 新增多列属性,CSS3新增单位,弹性盒模型
[外链图片转存中…(img-hn1nkPES-1715484708386)]
JavaScript
**JavaScript:**JavaScript基础,JavaScript数据类型,算术运算,强制转换,赋值运算,关系运算,逻辑运算,三元运算,分支循环,switch,while,do-while,for,break,continue,数组,数组方法,二维数组,字符串
[外链图片转存中…(img-QnDJzJgd-1715484708386)]















 4600
4600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









