







文末
我将这三次阿里面试的题目全部分专题整理出来,并附带上详细的答案解析,生成了一份PDF文档
- 第一个要分享给大家的就是算法和数据结构

- 第二个就是数据库的高频知识点与性能优化

- 第三个则是并发编程(72个知识点学习)

- 最后一个是各大JAVA架构专题的面试点+解析+我的一些学习的书籍资料

还有更多的Redis、MySQL、JVM、Kafka、微服务、Spring全家桶等学习笔记这里就不一一列举出来

报错了,看来是不行,所以这个@Target就是一个元注解,可以用来注解注解,也就是标记注解的注解。
关于元注解,一般有以下主要的几个:
-
@Documented 用于制作文档
-
@Target 指定注解的使用位置,不指定的话任何位置都可以使用
-
@Retention(注解的保留策略)
这里单独提一下最后一个也就是声明注解的保留策略@Retention,这个是什么意思呢?
这个保留策略啊,简单来讲就是说你这个注解可以在哪个时间段起作用,这个就得说说我们的代码从写出来,然后编译到执行的主要三个阶段了,画个图就是这样的:
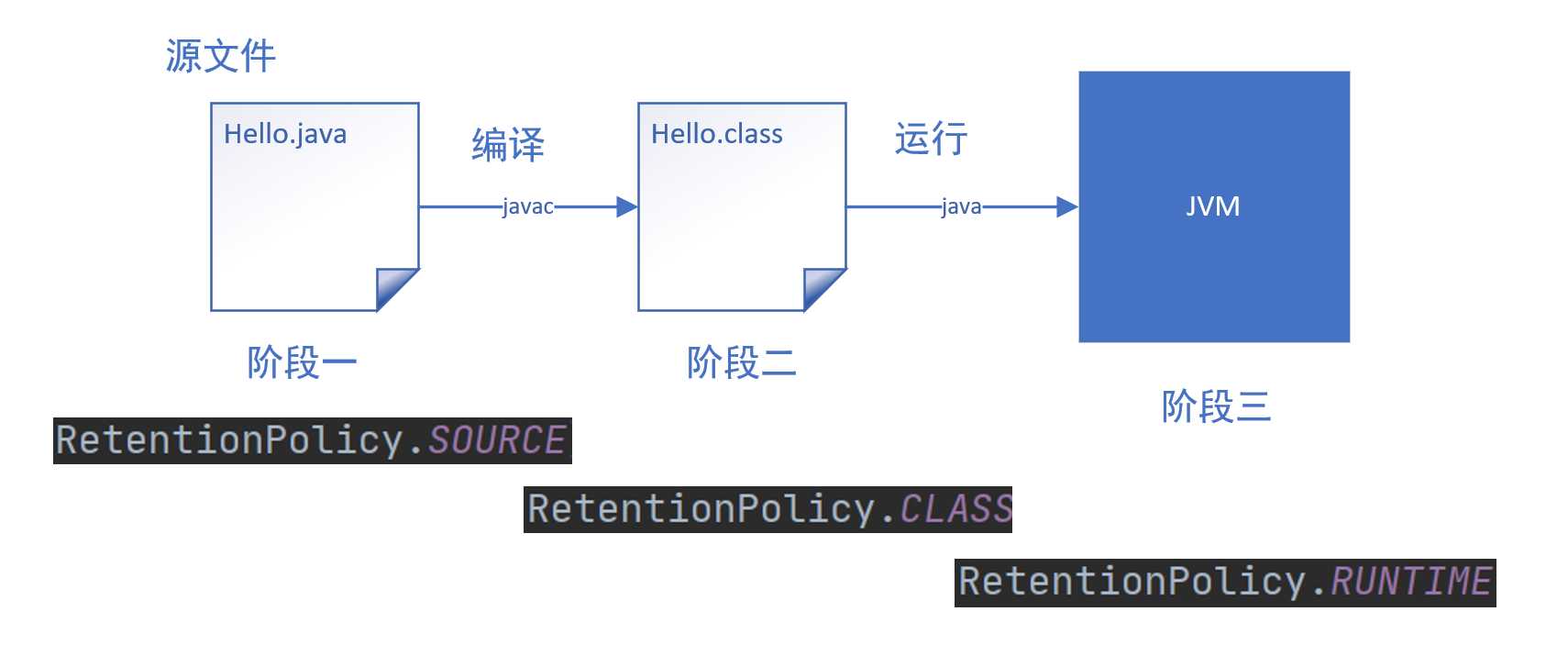
这个我已经画的很清楚了吧,一般来说,我们的注解都是要保留到运行期间的,所以一般就是这样:
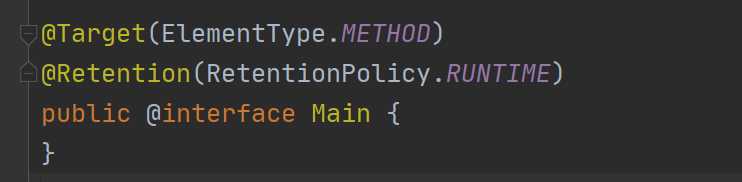
当然,具体情况具体对待。
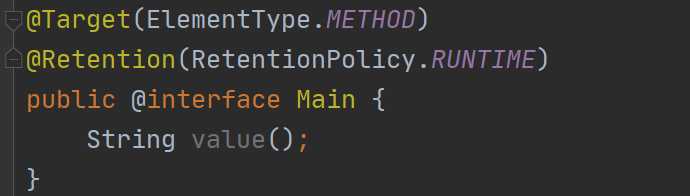
到这里你可能发现,这个注解里面可以有参数?当然是可以的,我这里简单演示下,下面讲到注解的语法的时候你就知道了:
然后再看下使用:
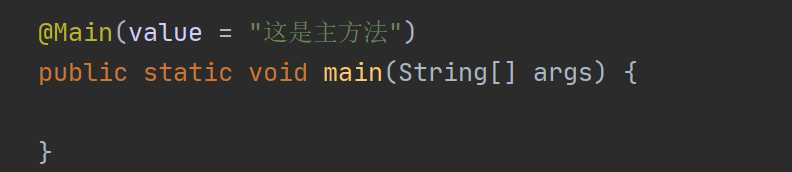
其实还是蛮简单的!
注解的基本使用语法
=========
接下来我们就来看看注解的语法吧,就是注解具体是如何使用的。
对于注解,我们知道了如何去定义它,比如简单定义一个注解:
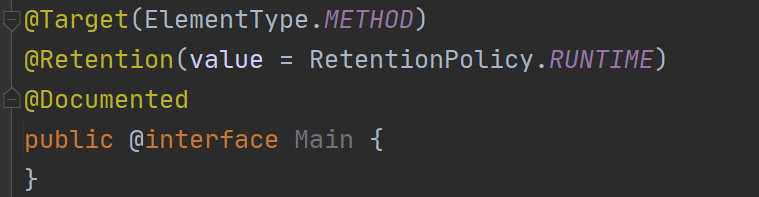
这很简单,我们继续去看,对于注解还可以定义属性:
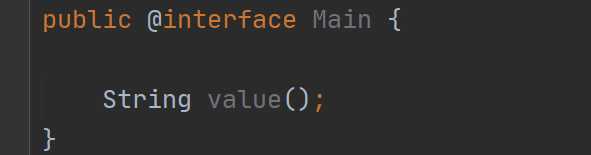
虽然这个属性看起来很像方法,但是人家就是属性,注解还是比较特殊的,那么现在我们来使用下这个注解:
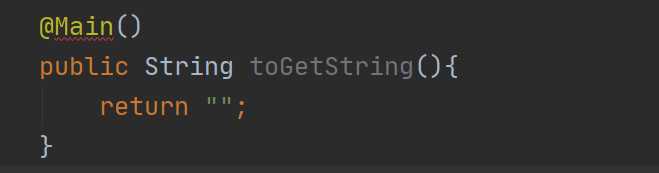
这个时候它会报错,告诉我们需要一个value值,其实也好理解,你的注解定义中定义的有一个value属性,那么你在使用的时候就需要把这个属性值给用上,那你说我可不可以不用,可以的,那定义注解属性的时候就需要给属性添加默认值,就是这样:
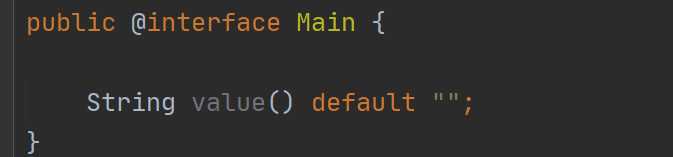
可以设置成一个空字符串也可以设置成具体的值。除此之外我们还可以设置多个属性值,像这样:
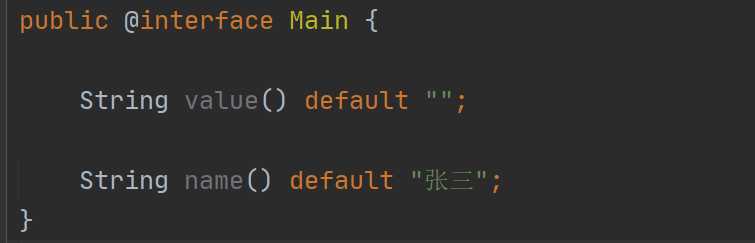
这里就有知识点了,如果你在使用的时候只是给一个属性值赋值,那么在使用的时候可以这样:
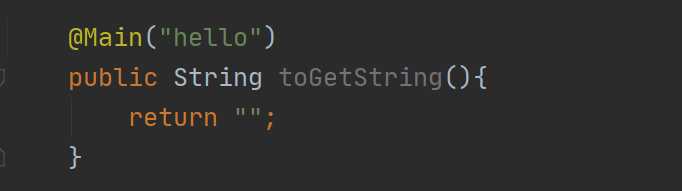
那有人可能疑问,我这个hello对应的是value还是name啊,默认对应的都是value,所以这个要牢记。
但是给多个属性值赋值的时候就必须指明具体的属性名称了,就是这样:
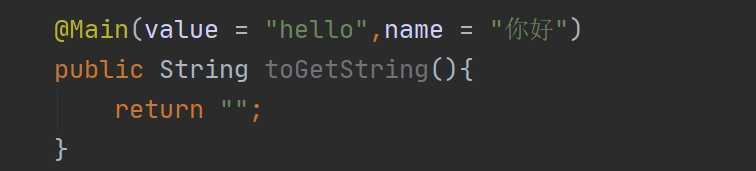
PS:通过上面的介绍我们会发现注解一个比较奇怪的地方,就是对于注解而言,我们可以定义属性,但是注解的属性长得真的像方法,但是在注解里面,它就是属性,就可以直接赋值,这里需要注意下!
属性的类型
=====
上面简单介绍了注解的属性,那么这些属性都是可以取哪些类型值呢?大致有如下这么多:
-
基本数据类型
-
String
-
枚举
-
Class
-
注解类型
-
数组(以上类型的一维数组)
关于数组的看个例子,比如这样:
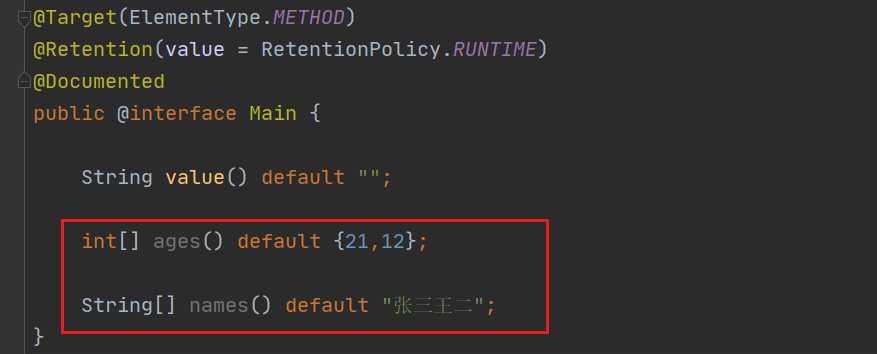
使用的时候也是同样的道理:

如何真正的理解注解
=========
我们平常对于注解之所以忽视的原因在于,很多地方只需要我们去使用,比如这样:
至于注解是怎么定义的以及注解是怎么起作用的都不太了解,好像需要我们自定义注解的也都很少,所以不去系统化的学习注解的话,会忽略掉注解的很多东西,只会使用,也就是@XXX
那么,从今天开始,我希望你能够记住,对于注解而言,它一定有如下三个流程:
-
定义注解
-
使用注解
-
读取并执行相应流程
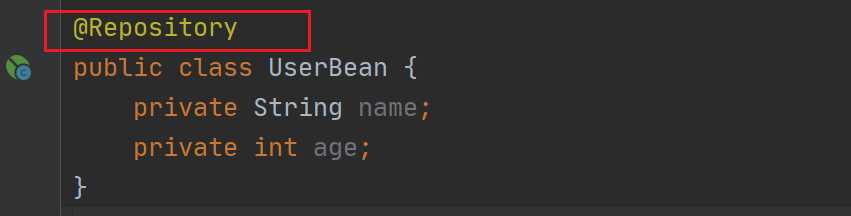
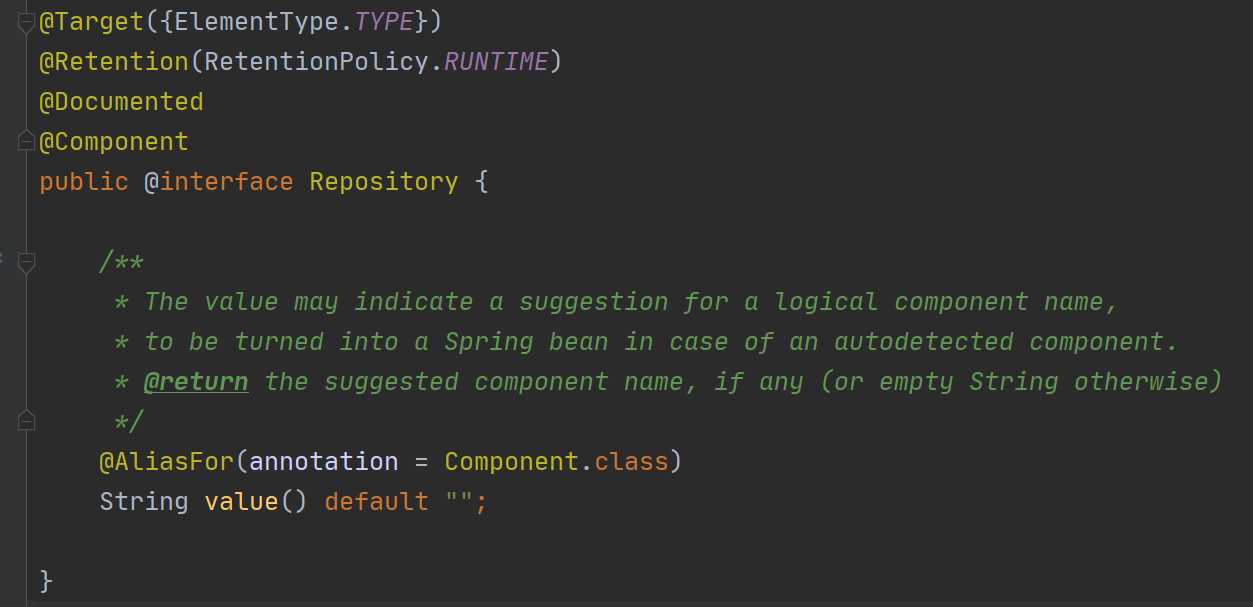
下面我们就以@Repository这个注解来看看这三个流程,首先是定义注解,这个我们可以在IDEA中按住Ctrl点进去@Repository来看,是这样的:
](http://www.ithuangqing.vip/wp-content/uploads/2020/07/wp_editor_md_4185e9864c1c7fc41fb1173d6526a9df.jpg)
这个就是@Repository注解的定义,接着我们看看@Repository的使用:
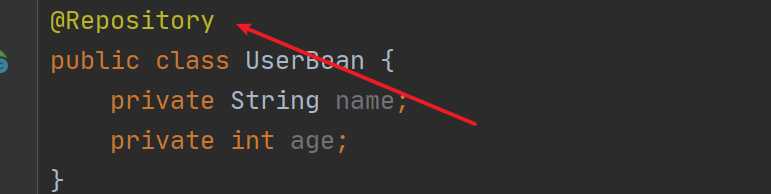
然后就是对注解的读取了,怎么读取呢?很多人对这块是比较模糊的,这也是对注解理解最大的障碍所在。
我们一般就是使用注解,对于注解的定义和读取这块一般都是框架什么的给我们搞定了,我们不看源码一般不知道是怎么回事的,也就不清楚注解到底是怎么运行起来的,简单的理解就是注解需要靠反射去读取,然后做相应的处理。
但是我想你一定和我一样好奇,为啥加了个@Repository注解之后,这个UserBean就被装载进Sring容器中生成了一个bean呢?
还记得我在最开始就一直在说的吗?注解是需要有专门的程序取读取的,然后根绝读取到的注解获取的信息去执行相应的操作。
所以这里,在Spring源码中,一定有某个或者某些程序在做这个事情。
注解的读取(注解如何起作用)
==============
上面说了注解的定义何使用,在这里单独把注解的读取拿出来说下,因为这点事理解注解的重点,很多人觉得对注解不理解的一个原因就在于不清楚加了个注解之后到底干了啥?
也就是注解到底是如何起作用的?搞明白这个,将对你理解注解有极大的帮助。
注解主要被反射读取
=========
对于注解的读取,一般就是通过反射技术来实现,这里就有知识点了,对于反射而言,它只能读取内存中的字节码信息,然后还记得之前我们说的注解的作用域@Target吗?
它里面有几个主要的作用域,也就是这张图片,再来回顾下:
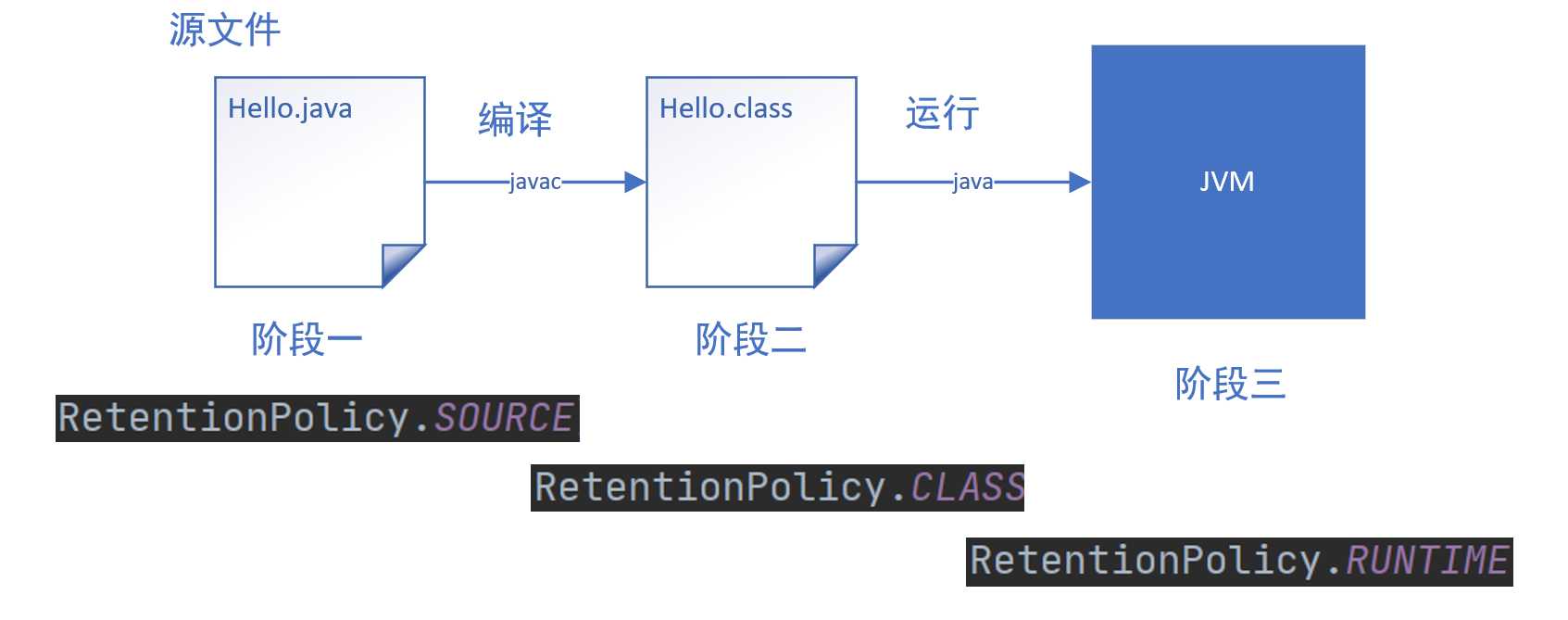
对于RetentionPolicy.CLASS而言,这个就是指的字节码这一阶段,这个时候这个字节码文件是由Java源文件通过javac编译生成,这个时候class字节码文件其实还是在磁盘内,并没有进入内存中。
而反射只能取读取内存中的字节码信息,所以注解的保留策略也就是这个@Target只能是RUNTIME,也即运行的时候仍然可以读取。
我的理解(精华)
========
很多人对注解不理解,或者觉得很模糊的一个原因就是你让我定义一个注解,我也能按照基本的注解语法去定义一个注解,你说怎么使用注解我也知道在类,方法等上面使用 @+注解名称的方式,但是也就到此为主了,更进一步的理解就有点模糊了,比如:
-
为什么要这样用?
-
原理是什么,怎么起作用的?
你想啊,我们就这样在类或者方法上面写了这么一个@+注解名称就行了?后续是怎么起作用的呢?这里你得首先清楚,注解有三大步骤:
-
定义注解
-
使用注解
-
读取注解(这块是大部分人缺少的,也是大部分人对注解不理解的关键所在)
再理解下什么是注解,与注释一字之差,肯定有相似之处,两者都是提供额外信息的,好比备注,注释是给我们程序员看到,看到注释我们知道某个类是干啥的,有啥用,看到方法的注释,我们知道这个方法有什么作用需要什么参数以及参数的含义等等,那么注解嘞,注解其实是给程序看到,当程序读到注解,会从注解这里得到一些信息,知道该如何处理被该注解标记的类或方法等。
好好理解上面的,我们下面再以Spring的一个例子来加以说明。
对于Spring简单的大家都知道IOC吧,直白点就是不用你new对象,需要什么直接从Spring容器中获取,那么首先就需要把我们的bean注册到Spring容器中吧,这个一般有xml配置方式和注解方式,当然我们这里要说的是注解方式,也就是使用@+注解名称的形式,举个简单的例子,如下:
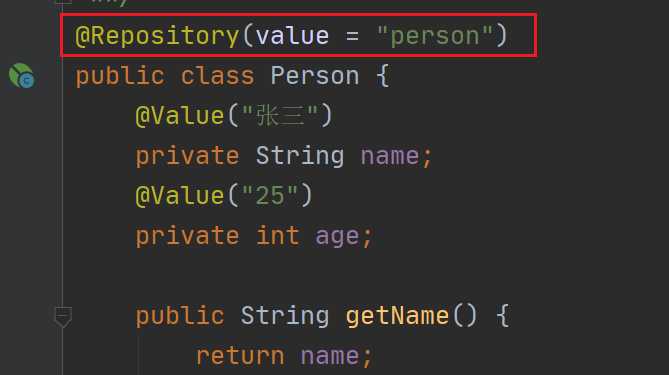
这个注解熟悉吧,它就是可以把我们的Person类注册到Spring容器中去,当然,这里就是在对这个注解的使用,我们点进去看看这个注解是怎么定义的:
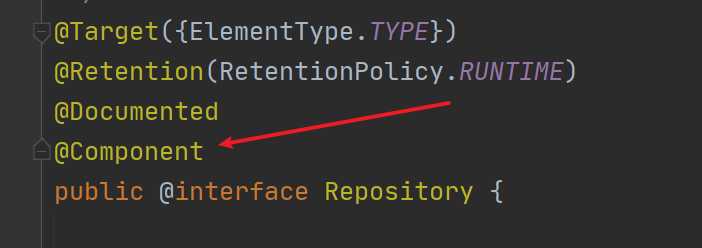
这个定义我们应该已经熟悉了,对于@Component也是一个注解,它其实是最基础的把类注册到Spring容器中的注解,后来的像我们现在说的@Repositoy以及@Service和@Controller这些都是在@Component的基础上发而来。
这里就需要注意了,其实这几个注解不管是哪个,都要清楚明白的一点就是,要它们啥用,之所以需要这些注解,就是希望在哪个类上使用这些注解,就自动把这个类注册到Spring容器中,这个要比我们写xml配置简单的多,我们就在一个类上写个@Repositoy,它就被注册到Spring容器中了?
是不是很神奇,然后看下注解的定义,也很简单,没啥东西啊,怎么就自动注册到Spring容器中了呢?
还记得之前说的注解三大步骤嘛?首先你需要定义一个注解,然后就是使用注解,那么注解是怎么起作用的就需要有程序去读注解,这个注解就好比一个标志,一个标签一样,比如这里的@Repositoy,当一个类被这个注解标志,那么当特有的程序去读到这个注解的时候,这个程序就知道,哦,原来是要把这类注册到Spring容器中啊,那么程序怎么知道要把这个类注册到Spring容器中呢?这就是 @Repositoy 告诉它的。另外我们知道注解一般可以设置一个value属性值,可以通过反射技术拿到之类的,那么在具体的将这个类注册到Spring容器的过程中可能就会用到这个value属性值,比如设置成bean的名字。
我们一般使用了注解,在Spring配置文件中就需要配置注解的包扫描:
<context:component-scan base-package=“com.ithuangqing.*”/>
1
这个其实就是在扫描,看看哪个类上使用到了@Repositoy这些注解,扫描到的就需要特殊处理将其注册到Spring容器。想一下,这里Spring其实就会对这个标签进行解析,核心代码:
registerBeanDefinitionParser(“component-scan”, new ComponentScanBeanDefinitionParser());
1
然后具体的处理流程就是在ComponentScanBeanDefinitionParser处理,代码如下:
@Override
public BeanDefinition parse(Element element, ParserContext parserContext) {
String basePackage = element.getAttribute(BASE_PACKAGE_ATTRIBUTE);
basePackage = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(basePackage);
String[] basePackages = StringUtils.tokenizeToStringArray(basePackage,
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
// Actually scan for bean definitions and register them.
ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element); //得到扫描器
Set beanDefinitions = scanner.doScan(basePackages); //扫描文件,并转化为spring bean,并注册
registerComponents(parserContext.getReaderContext(), beanDefinitions, element); //注册其他相关组件
return null;
}
1234567891011121314
上述代码的主要作用就是扫描base-package 下的文件,然后把它转换为Spring中的bean结构,接着将其注册到容器中……
怎么样,是不是越来越看不懂代码?很正常,这里只需要大家记住,注解是会被特有的程序去读取,然后去做相关的处理的,而这个处理逻辑,一般就比较复杂了,尤其框架中。
获取注解的属性
=======
上面讲解的关于注解是如何起作用的是很重要的,一定要理解,下面我们聊聊注解使用的最后一步:特有的程序去读取注解。
注解使用最终是需要依靠程序去读取注解,得到注解的一些信息,然后才判断接下来应该去做什么事情,那么接下来我们就要知道注解的属性值该如何获取。
其实注解的属性,用到的技术就是反射,反射是一个很重要的知识点,以后会单独写文通俗易懂的去聊一聊的。
接下来我们来看如何使用反射来获取注解的属性。,主要就是一下三个基本的方法:
/*是否存在对应 Annotation 对象/
public boolean isAnnotationPresent(Class<? extends Annotation> annotationClass)
{
return GenericDeclaration.super.isAnnotationPresent(annotationClass);
}
/*获取 Annotation 对象/
public A getAnnotation(Class annotationClass)
{
return (A) annotationData().annotations.get(annotationClass);
}
/*获取所有 Annotation 对象数组/
public Annotation[] getAnnotations()
{
return AnnotationParser.toArray(annotationData().annotations);
}
1234567891011121314151617
然后接下来看一段简单的代码:演示利用注解获取注解属性
public class Test {
public static void main(String[] args) throws Exception {
Class testClass = Test.class;
Method toGetString = testClass.getMethod(“toGetString”);
//获取注解对象
Main main = toGetString.getAnnotation(Main.class);
System.out.println(main.value());
}
@Main(“这是自定义注解的value值”)
public static String toGetString() {
return “”;
}
}
总结
三个工作日收到了offer,头条面试体验还是很棒的,这次的头条面试好像每面技术都问了我算法,然后就是中间件、MySQL、Redis、Kafka、网络等等。
- 第一个是算法
关于算法,我觉得最好的是刷题,作死的刷的,多做多练习,加上自己的理解,还是比较容易拿下的。
而且,我貌似是将《算法刷题LeetCode中文版》、《算法的乐趣》大概都过了一遍,尤其是这本
《算法刷题LeetCode中文版》总共有15个章节:编程技巧、线性表、字符串、栈和队列、树、排序、查找、暴力枚举法、广度优先搜索、深度优先搜索、分治法、贪心法、动态规划、图、细节实现题

《算法的乐趣》共有23个章节:


- 第二个是Redis、MySQL、kafka(给大家看下我都有哪些复习笔记)
基本上都是面试真题解析、笔记和学习大纲图,感觉复习也就需要这些吧(个人意见)

- 第三个是网络(给大家看一本我之前得到的《JAVA核心知识整理》包括30个章节分类,这本283页的JAVA核心知识整理还是很不错的,一次性总结了30个分享的大知识点)

23个章节:**
[外链图片转存中…(img-WUybM1Yi-1715623743852)]
[外链图片转存中…(img-MONdBCaA-1715623743853)]
- 第二个是Redis、MySQL、kafka(给大家看下我都有哪些复习笔记)
基本上都是面试真题解析、笔记和学习大纲图,感觉复习也就需要这些吧(个人意见)
[外链图片转存中…(img-OZJet8p3-1715623743853)]
- 第三个是网络(给大家看一本我之前得到的《JAVA核心知识整理》包括30个章节分类,这本283页的JAVA核心知识整理还是很不错的,一次性总结了30个分享的大知识点)
[外链图片转存中…(img-hnMjRMqL-1715623743853)]














 601
601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









