







总结
就写到这了,也算是给这段时间的面试做一个总结,查漏补缺,祝自己好运吧,也希望正在求职或者打算跳槽的 程序员看到这个文章能有一点点帮助或收获,我就心满意足了。多思考,多问为什么。希望小伙伴们早点收到满意的offer! 越努力越幸运!
金九银十已经过了,就目前国内的面试模式来讲,在面试前积极的准备面试,复习整个 Java 知识体系将变得非常重要,可以很负责任的说一句,复习准备的是否充分,将直接影响你入职的成功率。但很多小伙伴却苦于没有合适的资料来回顾整个 Java 知识体系,或者有的小伙伴可能都不知道该从哪里开始复习。我偶然得到一份整理的资料,不论是从整个 Java 知识体系,还是从面试的角度来看,都是一份含技术量很高的资料。

- 7.11 Java如何获取ArrayList的容量(elementData)大小?
ArrayList顶部有一段很长的注释,大概的介绍了ArrayList。
1.1 原文
/**
-
Resizable-array implementation of the List interface. Implements
-
all optional list operations, and permits all elements, including
-
null. In addition to implementing the List interface,
-
this class provides methods to manipulate the size of the array that is
-
used internally to store the list. (This class is roughly equivalent to
-
Vector, except that it is unsynchronized.)
-
The size, isEmpty, get, set,
-
iterator, and listIterator operations run in constant
-
time. The add operation runs in amortized constant time,
-
that is, adding n elements requires O(n) time. All of the other operations
-
run in linear time (roughly speaking). The constant factor is low compared
-
to that for the LinkedList implementation.
-
Each ArrayList instance has a capacity. The capacity is
-
the size of the array used to store the elements in the list. It is always
-
at least as large as the list size. As elements are added to an ArrayList,
-
its capacity grows automatically. The details of the growth policy are not
-
specified beyond the fact that adding an element has constant amortized
-
time cost.
-
An application can increase the capacity of an ArrayList instance
-
before adding a large number of elements using the ensureCapacity
-
operation. This may reduce the amount of incremental reallocation.
-
Note that this implementation is not synchronized.
-
If multiple threads access an ArrayList instance concurrently,
-
and at least one of the threads modifies the list structurally, it
-
must be synchronized externally. (A structural modification is
-
any operation that adds or deletes one or more elements, or explicitly
-
resizes the backing array; merely setting the value of an element is not
-
a structural modification.) This is typically accomplished by
-
synchronizing on some object that naturally encapsulates the list.
-
If no such object exists, the list should be “wrapped” using the
-
{@link Collections#synchronizedList Collections.synchronizedList}
-
method. This is best done at creation time, to prevent accidental
-
unsynchronized access to the list:
-
List list = Collections.synchronizedList(new ArrayList(…));
-
-
The iterators returned by this class’s {@link #iterator() iterator} and
-
{@link #listIterator(int) listIterator} methods are fail-fast:
-
if the list is structurally modified at any time after the iterator is
-
created, in any way except through the iterator’s own
-
{@link ListIterator#remove() remove} or
-
{@link ListIterator#add(Object) add} methods, the iterator will throw a
-
{@link ConcurrentModificationException}. Thus, in the face of
-
concurrent modification, the iterator fails quickly and cleanly, rather
-
than risking arbitrary, non-deterministic behavior at an undetermined
-
time in the future.
-
Note that the fail-fast behavior of an iterator cannot be guaranteed
-
as it is, generally speaking, impossible to make any hard guarantees in the
-
presence of unsynchronized concurrent modification. Fail-fast iterators
-
throw {@code ConcurrentModificationException} on a best-effort basis.
-
Therefore, it would be wrong to write a program that depended on this
-
exception for its correctness: the fail-fast behavior of iterators
-
should be used only to detect bugs.
-
This class is a member of the
-
Java Collections Framework.
-
@author Josh Bloch
-
@author Neal Gafter
-
@see Collection
-
@see List
-
@see LinkedList
-
@see Vector
-
@since 1.2
*/
public class ArrayList extends AbstractList
implements List, RandomAccess, Cloneable, java.io.Serializable
{
…
}
1.2 翻译
List接口的大小可变数组的实现。实现了所有可选列表操作,并允许包括null在内的所有元素。除了实现List接口外,此类还提供一些方法来操作内部用来存储列表的数组的大小。(此类大致上等同于Vector类,除了此类是不同步的。)
size、isEmpty、get、set、iterator和listIterator操作都以固定时间运行。add操作以分摊的固定时间运行,也就是说,添加n个元素需要O(n)时间。其他所有操作都以线性时间运行(大体上讲)。与用于LinkedList实现的常数因子相比,此实现的常数因子较低。
每个ArrayList实例都有一个容量。该容量是指用来存储列表元素的数组的大小。它总是至少等于列表的大小。随着向ArrayList中不断添加元素,其容量也自动增长。并未指定增长策略的细节,因为这不只是添加元素会带来分摊固定时间开销那样简单。
在添加大量元素前,应用程序可以使用ensureCapacity操作来增加ArrayList实例的容量。这可以减少递增式再分配的数量。
注意,此实现不是同步的。如果多个线程同时访问一个ArrayList实例,而其中至少一个线程从结构上修改了列表,那么它必须保持外部同步。(结构上的修改是指任何添加或删除一个或多个元素的操作,或者显式调整底层数组的大小;仅仅设置元素的值不是结构上的修改。)这一般通过对自然封装该列表的对象进行同步操作来完成。如果不存在这样的对象,则应该使用Collections.synchronizedList方法将该列表“包装”起来。这最好在创建时完成,以防止意外对列表进行不同步的访问:
List list = Collections.synchronizedList(new ArrayList(…));
此类的iterator和listIterator方法返回的迭代器是快速失败的:在创建迭代器之后,除非通过迭代器自身的remove或add方法从结构上对列表进行修改,否则在任何时间以任何方式对列表进行修改,迭代器都会抛出ConcurrentModificationException。因此,面对并发的修改,迭代器很快就会完全失败,而不是冒着在将来某个不确定时间发生任意不确定行为的风险。
注意,迭代器的快速失败行为无法得到保证,因为一般来说,不可能对是否出现不同步并发修改做出任何硬性保证。快速失败迭代器会尽最大努力抛出ConcurrentModificationException。因此,为提高这类迭代器的正确性而编写一个依赖于此异常的程序是错误的做法:迭代器的快速失败行为应该仅用于检测bug。
此类是Java Collections Framework的成员。
1.3 一语中的
- 底层:ArrayList是List接口的大小可变数组的实现。
- 是否允许null:ArrayList允许null元素。
- 时间复杂度:size、isEmpty、get、set、iterator和listIterator方法都以固定时间运行,时间复杂度为O(1)。add和remove方法需要O(n)时间。与用于LinkedList实现的常数因子相比,此实现的常数因子较低。
- 容量:ArrayList的容量可以自动增长。
- 是否同步:ArrayList不是同步的。
- 迭代器:ArrayList的iterator和listIterator方法返回的迭代器是 fail-fast 的。
如果小伙伴们不了解"fail-fast"机制,可以参考如下文章:
1.4 线程安全性
对ArrayList进行添加元素的操作的时候是分两个步骤进行的,即第一步先在object[size]的位置上存放需要添加的元素;第二步将size的值增加1。由于这个过程在多线程的环境下是不能保证具有原子性的,因此ArrayList在多线程的环境下是线程不安全的。
具体举例说明:在单线程运行的情况下,如果Size = 0,添加一个元素后,此元素在位置 0,而且Size=1;而如果是在多线程情况下,比如有两个线程,线程 A 先将元素存放在位置0。但是此时 CPU 调度线程A暂停,线程 B 得到运行的机会。线程B也向此ArrayList 添加元素,因为此时 Size 仍然等于 0 (注意哦,我们假设的是添加一个元素是要两个步骤哦,而线程A仅仅完成了步骤1),所以线程B也将元素存放在位置0。然后线程A和线程B都继续运行,都增 加 Size 的值。 那好,现在我们来看看 ArrayList 的情况,元素实际上只有一个,存放在位置 0,而Size却等于 2。这就是“线程不安全”了。
如果非要在多线程的环境下使用ArrayList,就需要保证它的线程安全性,通常有两种解决办法:
- 第一,使用synchronized关键字;
- 第二,可以用Collections类中的静态方法synchronizedList();对ArrayList进行调用即可。
- 第三,也可以使用concurrent并发包下的CopyOnWriteArrayList类。
1.5 优劣分析
优点
- ArrayList底层以数组实现,是一种随机访问模式,再加上它实现了RandomAccess接口,因此查找也就是get的时候非常快。
- ArrayList在顺序添加一个元素的时候非常方便,只是往数组里面添加了一个元素而已。
- 根据下标遍历元素,效率高。
- 根据下标访问元素,效率高。
- 可以自动扩容,默认为每次扩容为原来的1.5倍。
缺点
- 插入和删除元素的效率不高。
- 根据元素下标查找元素需要遍历整个元素数组,效率不高。
- 线程不安全。
我们先来看看ArrayList的定义:
public class ArrayList extends AbstractList
implements List,RandomAccess,Cloneable,java.io.Serializable
从中我们可以了解到:
- ArrayList:说明ArrayList支持泛型。
- extends AbstractList :继承了AbstractList。AbstractList提供List接口的骨干实现,以最大限度地减少“随机访问”数据存储(如ArrayList)实现Llist所需的工作。
- implements List:实现了List。实现了所有可选列表操作。
- implements RandomAccess:表明ArrayList支持快速(通常是固定时间)随机访问。此接口的主要目的是允许一般的算法更改其行为,从而在将其应用到随机或连续访问列表时能提供良好的性能。
- implements Cloneable:表明其可以调用clone()方法来返回实例的field-for-field拷贝。
- implements java.io.Serializable:表明该类具有序列化功能。
为什么要先继承AbstractList,而让AbstractList先实现List?而不是让ArrayList直接实现List?
这里是有一个思想,接口中全都是抽象的方法,而抽象类中可以有抽象方法,还可以有具体的实现方法,正是利用了这一点,让AbstractList是实现接口中一些通用的方法,而具体的类, 如ArrayList就继承这个AbstractList类,拿到一些通用的方法,然后自己在实现一些自己特有的方法,这样一来,让代码更简洁,就继承结构最底层的类中通用的方法都抽取出来,先一起实现了,减少重复代码。所以一般看到一个类上面还有一个抽象类,应该就是这个作用。
ArrayList的父类AbstractList也实现了List接口,那为什么子类ArrayList还是去实现一遍呢?
collection 的作者Josh说他写这代码的时候觉得这个会有用处,但是其实并没什么用,但因为没什么影响,就一直留到了现在。
ArrayList的类结构图:
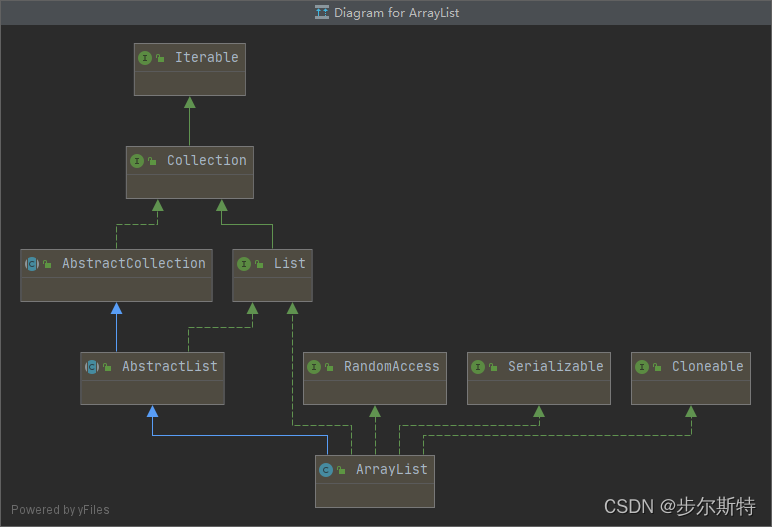
如何查看类的完整结构图可以参考如下文章:
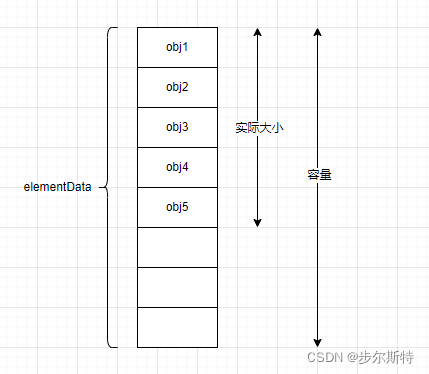
如图所示,ArrayList底层通过数组实现。
一般的时候,我们只需要知道ArrayList的实际大小,但是作为一个优秀的程序员,知道ArrayList数组的容量大小非常重要,如果你想知道如何获取ArrayList的容量大小,可以参考如下文章:
/**
- 初始化默认容量。
*/
private static final int DEFAULT_CAPACITY = 10;
/**
- 指定该ArrayList容量为0时,返回该空数组。
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
-
当调用无参构造方法,返回的是该数组。刚创建一个ArrayList 时,其内数据量为0。
-
它与EMPTY_ELEMENTDATA的区别就是:该数组是默认返回的,而后者是在用户指定容量为0时返回。
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
-
保存添加到ArrayList中的元素。
-
ArrayList的容量就是该数组的长度。
-
该值为DEFAULTCAPACITY_EMPTY_ELEMENTDATA 时,当第一次添加元素进入ArrayList中时,数组将扩容值DEFAULT_CAPACITY。
-
被标记为transient,在对象被序列化的时候不会被序列化。
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
-
ArrayList的实际大小(数组包含的元素个数)。
-
@serial
*/
private int size;
思考:elementData被标记为transient,那么它的序列化和反序列化是如何实现的呢?
被标记为transient的属性在对象被序列化的时候不会被保存。
ArrayList自定义了它的序列化和反序列化方式。详情请查看writeObject(java.io.ObjectOutputStream s)和readObject(java.io.ObjectOutputStream s)方法。
ArrayList提供了三种构造方法:
- ArrayList(int initialCapacity):构造一个指定容量为capacity的空ArrayList。
- ArrayList():构造一个初始容量为 10 的空列表。
- ArrayList(Collection<? extends E> c):构造一个包含指定 collection 的元素的列表,这些元素是按照该 collection 的迭代器返回它们的顺序排列的。
5.1 ArrayList( int initialCapacity)
/**
-
构造一个指定初始化容量为capacity的空ArrayList。
-
@param initialCapacity ArrayList的指定初始化容量
-
@throws IllegalArgumentException 如果ArrayList的指定初始化容量为负。
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
5.2 ArrayList()
/**
- 构造一个初始容量为 10 的空列表。
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
5.3 ArrayList(Collection<? extends E> c)
/**
-
构造一个包含指定 collection 的元素的列表,这些元素是按照该 collection 的迭代器返回它们的顺序排列的。
-
@param c 其元素将放置在此列表中的 collection
-
@throws NullPointerException 如果指定的 collection 为 null
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
ArrayList有以下核心方法:
| 方法名 | 时间复杂度 |
| — | — |
| get(int index) | O(1) |
| add(E e) | O(1) |
| add(add(int index, E element)) | O(n) |
| remove(int index) | O(n) |
| set(int index, E element) | O(1) |
6.1 get( int index)
/**
-
返回list中索引为index的元素
-
@param index 需要返回的元素的索引
-
@return list中索引为index的元素
-
@throws IndexOutOfBoundsException 如果索引超出size
*/
public E get(int index) {
//越界检查
rangeCheck(index);
//返回索引为index的元素
return elementData(index);
}
/**
-
越界检查。
-
检查给出的索引index是否越界。
-
如果越界,抛出运行时异常。
-
这个方法并不检查index是否合法。比如是否为负数。
-
如果给出的索引index>=size,抛出一个越界异常
*/
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
- 返回索引为index的元素
*/
@SuppressWarnings(“unchecked”)
E elementData(int index) {
return (E) elementData[index];
}
从代码中可以看到,因为ArrayList底层是数组,所以它的get方法非常简单,先是判断一下有没有越界,之后就直接通过数组下标来获取元素。get方法的时间复杂度是O(1)。
6.2 add(E e)
/**
-
添加元素到list末尾.
-
@param e 被添加的元素
-
@return true
*/
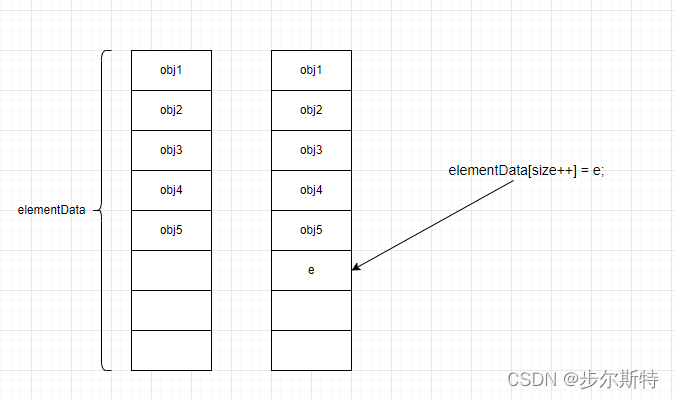
public boolean add(E e) {
//确认list容量,如果不够,容量加1。注意:只加1,保证资源不被浪费
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
从源码中可以看到,add(E e)有两个步骤:
- 空间检查,如果有需要进行扩容
- 插入元素
空间检查和扩容的介绍在下面。
空间的问题解决后,插入过程就显得非常简单。
6.3 扩容方法
/**
-
增加ArrayList容量。
-
@param minCapacity 想要的最小容量
*/
public void ensureCapacity(int minCapacity) {
// 如果elementData等于DEFAULTCAPACITY_EMPTY_ELEMENTDATA,最小扩容量为DEFAULT_CAPACITY,否则为0
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)? 0: DEFAULT_CAPACITY;
//如果想要的最小容量大于最小扩容量,则使用想要的最小容量。
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
/**
-
数组容量检查,不够时则进行扩容,只供类内部使用。
-
@param minCapacity 想要的最小容量
*/
private void ensureCapacityInternal(int minCapacity) {
// 若elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA,则取minCapacity为DEFAULT_CAPACITY和参数minCapacity之间的最大值
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
/**
-
数组容量检查,不够时则进行扩容,只供类内部使用
-
@param minCapacity 想要的最小容量
*/
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// 确保指定的最小容量 > 数组缓冲区当前的长度
if (minCapacity - elementData.length > 0)
//扩容
grow(minCapacity);
}
/**
-
分派给arrays的最大容量
-
为什么要减去8呢?
-
因为某些VM会在数组中保留一些头字,尝试分配这个最大存储容量,可能会导致array容量大于VM的limit,最终导致OutOfMemoryError。
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
-
扩容,保证ArrayList至少能存储minCapacity个元素
-
第一次扩容,逻辑为newCapacity = oldCapacity + (oldCapacity >> 1);即在原有的容量基础上增加一半。第一次扩容后,如果容量还是小于minCapacity,就将容量扩充为minCapacity。
-
@param minCapacity 想要的最小容量
*/
private void grow(int minCapacity) {
// 获取当前数组的容量
int oldCapacity = elementData.length;
// 扩容。新的容量=当前容量+当前容量/2.即将当前容量增加一半。
int newCapacity = oldCapacity + (oldCapacity >> 1);
//如果扩容后的容量还是小于想要的最小容量
if (newCapacity - minCapacity < 0)
//将扩容后的容量再次扩容为想要的最小容量
newCapacity = minCapacity;
//如果扩容后的容量大于临界值,则进行大容量分配
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData,newCapacity);
}
/**
- 进行大容量分配
*/
private static int hugeCapacity(int minCapacity) {
//如果minCapacity<0,抛出异常
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
//如果想要的容量大于MAX_ARRAY_SIZE,则分配Integer.MAX_VALUE,否则分配MAX_ARRAY_SIZE
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
看完了代码,可以对扩容方法总结如下:
- 进行空间检查,决定是否进行扩容,以及确定最少需要的容量
- 如果确定扩容,就执行grow(int minCapacity),minCapacity为最少需要的容量
- 第一次扩容,逻辑为newCapacity = oldCapacity + (oldCapacity >> 1);即在原有的容量基础上增加一半。
- 第一次扩容后,如果容量还是小于minCapacity,就将容量扩充为minCapacity。
- 对扩容后的容量进行判断,如果大于允许的最大容量MAX_ARRAY_SIZE,则将容量再次调整为MAX_ARRAY_SIZE。至此扩容操作结束。
6.4 add( int index, E element)
/**
-
在制定位置插入元素。当前位置的元素和index之后的元素向后移一位
-
@param index 即将插入元素的位置
-
@param element 即将插入的元素
-
@throws IndexOutOfBoundsException 如果索引超出size
*/
public void add(int index, E element) {
//越界检查
rangeCheckForAdd(index);
//确认list容量,如果不够,容量加1。注意:只加1,保证资源不被浪费
ensureCapacityInternal(size + 1); // Increments modCount!!
// 对数组进行复制处理,目的就是空出index的位置插入element,并将index后的元素位移一个位置
System.arraycopy(elementData, index, elementData, index + 1,size - index);
//将指定的index位置赋值为element
elementData[index] = element;
//实际容量+1
size++;
}
从源码中可以看到,add(E e)有三个步骤:
- 越界检查
- 空间检查,如果有需要进行扩容
- 插入元素
越界检查很简单
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
空间检查和扩容的介绍在上面。
空间的问题解决后,插入过程就显得非常简单。
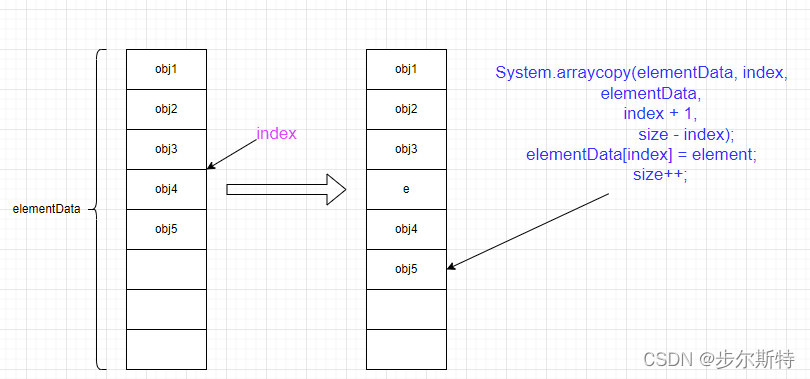
add(int index, E e)需要先对元素进行移动,然后完成插入操作,也就意味着该方法有着线性的时间复杂度,即O(n)。
6.5 remove( int index)
/**
-
删除list中位置为指定索引index的元素
-
索引之后的元素向左移一位
-
@param index 被删除元素的索引
-
@return 被删除的元素
-
@throws IndexOutOfBoundsException 如果参数指定索引index>=size,抛出一个越界异常
*/
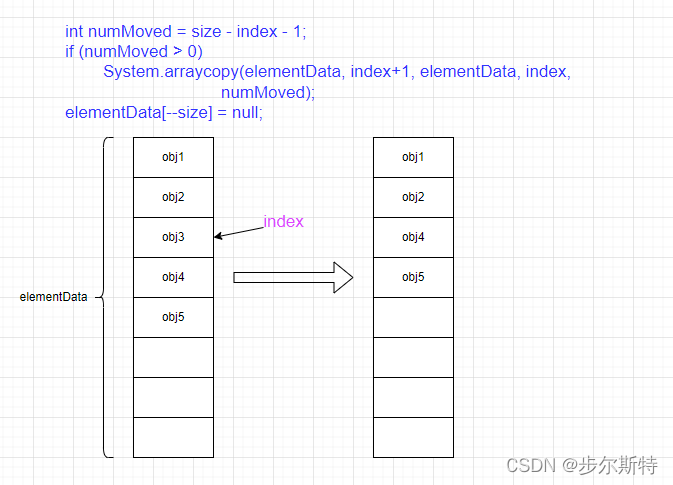
public E remove(int index) {
//检查索引是否越界。如果参数指定索引index>=size,抛出一个越界异常
rangeCheck(index);
//结构性修改次数+1
modCount++;
//记录索引为inde处的元素
E oldValue = elementData(index);
// 删除指定元素后,需要左移的元素个数
int numMoved = size - index - 1;
//如果有需要左移的元素,就移动(移动后,该删除的元素就已经被覆盖了)
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
// size减一,然后将索引为size-1处的元素置为null。为了让GC起作用,必须显式的为最后一个位置赋null值
elementData[–size] = null; // clear to let GC do its work
//返回被删除的元素
return oldValue;
}
/**
-
越界检查。
-
检查给出的索引index是否越界。
-
如果越界,抛出运行时异常。
-
这个方法并不检查index是否合法。比如是否为负数。
-
如果给出的索引index>=size,抛出一个越界异常
*/
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
看完代码后,可以将ArrayList删除指定索引的元素的步骤总结为:
- 检查索引是否越界。如果参数指定索引index>=size,抛出一个越界异常
- 将索引大于index的元素左移一位(左移后,该删除的元素就被覆盖了,相当于被删除了)。
- 将索引为size-1处的元素置为null(为了让GC起作用)。
注意:为了让GC起作用,必须显式的为最后一个位置赋null值。上面代码中如果不手动赋null值,除非对应的位置被其他元素覆盖,否则原来的对象就一直不会被回收。
6.6 set( int index, E element)
/**
-
替换指定索引的元素
-
@param 被替换元素的索引
-
@param element 即将替换到指定索引的元素
-
@return 返回被替换的元素
-
@throws IndexOutOfBoundsException 如果参数指定索引index>=size,抛出一个越界异常
*/
public E set(int index, E element) {
//检查索引是否越界。如果参数指定索引index>=size,抛出一个越界异常
rangeCheck(index);
//记录被替换的元素
E oldValue = elementData(index);
//替换元素
elementData[index] = element;
//返回被替换的元素
return oldValue;
}
这里可以看到modCount的用处,当modCount发生改变后,立刻抛出ConcurrentModificationException异常。通过之前的分析可以知道当列表内容被修改时modCount会增加。也就是说如果在遍历ArrayList的过程中有其他线程修改了ArrayList,那么将抛出ConcurrentModificationException异常
6.7 indexOf(Object o)
indexOf(Object o)方法的作用是从头开始查找与指定元素相等的元素,如果找到,则返回找到的元素在元素数组中的下标,如果没有找到返回-1。与该方法类似的是lastIndexOf(Object o)方法,该方法的作用是从尾部开始查找与指定元素相等的元素。
查看该方法的源码可知,该方法从需要查找的元素是否为空的角度分为两种情况分别讨论。这也意味着该方法的参数可以是null元素,也意味着ArrayList集合中能够保存null元素。方法实现的逻辑也比较简单,直接循环遍历元素数组,通过equals方法来判断对象是否相同,相同就返回下标,找不到就返回-1。这也解释了为什么要把情况分为需要查找的对象是否为空两种情况讨论,不然的话空对象调用equals方法则会产生空指针异常。
// 从首开始查找数组里面是否存在指定元素
public int indexOf(Object o) {
if (o == null) { // 查找的元素为空
for (int i = 0; i < size; i++) // 遍历数组,找到第一个为空的元素,返回下标
if (elementData[i]==null)
return i;
} else { // 查找的元素不为空
for (int i = 0; i < size; i++) // 遍历数组,找到第一个和指定元素相等的元素,返回下标
if (o.equals(elementData[i]))
return i;
}
// 没有找到,返回空
return -1;
}
6.8 forEach(Consumer<? super E> action)
遍历列表 ,这里我们先来看一下源码是怎么写的:
/**
-
The number of times this list has been structurally modified.
-
Structural modifications are those that change the size of the
-
list, or otherwise perturb it in such a fashion that iterations in
-
progress may yield incorrect results.
-
This field is used by the iterator and list iterator implementation
-
returned by the {@code iterator} and {@code listIterator} methods.
-
If the value of this field changes unexpectedly, the iterator (or list
-
iterator) will throw a {@code ConcurrentModificationException} in
-
response to the {@code next}, {@code remove}, {@code previous},
-
{@code set} or {@code add} operations. This provides
-
fail-fast behavior, rather than non-deterministic behavior in
-
the face of concurrent modification during iteration.
-
Use of this field by subclasses is optional. If a subclass
-
wishes to provide fail-fast iterators (and list iterators), then it
-
merely has to increment this field in its {@code add(int, E)} and
-
{@code remove(int)} methods (and any other methods that it overrides
-
that result in structural modifications to the list). A single call to
-
{@code add(int, E)} or {@code remove(int)} must add no more than
-
one to this field, or the iterators (and list iterators) will throw
-
bogus {@code ConcurrentModificationExceptions}. If an implementation
-
does not wish to provide fail-fast iterators, this field may be
-
ignored.
*/
protected transient int modCount = 0;//操作数,since abstract AbstractList.java
@Override
public void forEach(Consumer<? super E> action) {
// 确保不为空
Objects.requireNonNull(action);
final int expectedModCount = modCount;
@SuppressWarnings(“unchecked”)
final E[] elementData = (E[]) this.elementData;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
action.accept(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
/**
-
Checks that the specified object reference is not {@code null}. This
-
method is designed primarily for doing parameter validation in methods
-
and constructors, as demonstrated below:
-
-
public Foo(Bar bar) {
-
this.bar = Objects.requireNonNull(bar); -
}
-
@param obj the object reference to check for nullity
-
@param the type of the reference
-
@return {@code obj} if not {@code null}
-
@throws NullPointerException if {@code obj} is {@code null}
*/
public static T requireNonNull(T obj) {//since final class Objects.java
if (obj == null)
throw new NullPointerException();
return obj;
}
6.9 clear()方法
/**
-
Removes all of the elements from this list. The list will
-
be empty after this call returns.
从列表中删除所有元素。该调用返回后,列表将为空。
*/
public void clear() {
modCount++;
// clear to let GC do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
这里我们做一个小demo:
package com.uncle;
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.HashMap;
public class Main {
public static void main(String[] args) throws Exception {
HashMap hashMap = new HashMap();
ArrayList arrayList = new ArrayList();
Main main = new Main();
arrayList.add(main);
arrayList.add(main);
arrayList.add(main);
arrayList.add(main);
arrayList.add(main);
arrayList.add(main);
arrayList.add(main);
arrayList.add(main);
arrayList.add(main);
arrayList.add(main);
arrayList.add(main);
Class<? extends ArrayList> aClass = arrayList.getClass();
Field elementData = aClass.getDeclaredField(“elementData”);
elementData.setAccessible(true);
Object[] objects = (Object[]) elementData.get(arrayList);
arrayList.clear();
System.out.println(objects.length);
System.out.println(arrayList.size());
}
}
显然,容量虽然扩容了,但是里面的有效元素全部清空了。
迭代器模式(Iterator Pattern):提供一种方法来访问聚合对象中的各个元素,而不用暴露这个对象的内部表示。
在Java中,ArrayList的迭代器有两种:Iterator和ListIterator。
7.1 Iterator
迭代器是一个用来遍历并选择序列中的对象。Java的Iterator的只能单向移动。
案例
在写如何实现之前,先看一个使用迭代器Iterator小例子:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Test {
@org.junit.Test
public void test() {
List list = new ArrayList<>();
list.add(“1”);
list.add(“2”);
list.add(“3”);
list.add(“4”);
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
String str = (String) iterator.next();
System.out.println(str);
iterator.remove();
}
System.out.println(list.size());
}
}
运行结果
1
2
3
4
0
方法
-
iterator(),list.iterator()用来从容器对象中返回一个指向list开始处的迭代器。
-
next(),获取序列中的下个元素。
-
hasNext(),检查序列中向下是否还有元素。
-
remove(),将迭代器最近返回的一个元素删除。这也意味着调用remove()前需要先调用next()。
实现
迭代器模式中有四个角色:
- 抽象聚合类Aggregate。在ArrayList的Iterator迭代器实现中,没有抽象聚合类。虽然它实现了AbstractList,实现了List,但它向外部提供的创建迭代器的方法iterator()是它自己的。
- 具体聚合类ConcreteAggregate。在ArrayList的Iterator迭代器实现中,指的是ArrayList。
- 抽象迭代器Iterator。在ArrayList的Iterator迭代器实现中,指的是Iterator接口。
- 具体迭代器ConcreteIterator。在ArrayList中的Iterator迭代器实现中,指的是Itr。
ArrayList代码片段
public class ArrayList
{
/**
-
保存添加到ArrayList中的元素。
-
ArrayList的容量就是该数组的长度。
-
该值为DEFAULTCAPACITY_EMPTY_ELEMENTDATA 时,当第一次添加元素进入ArrayList中时,数组将扩容值DEFAULT_CAPACITY。
-
被标记为transient,在对象被序列化的时候不会被序列化。
*/
transient Object[] elementData;
// ArrayList的实际大小(数组包含的元素个数)。
private int size;
/**
- 返回一个用来遍历ArrayList元素的Iterator迭代器
*/
public Iterator iterator() {
return new Itr();
}
/**
- AbstractList.Itr的最优化的版本
*/
private class Itr implements Iterator {
int cursor; // 下一个要返回的元素的索引
int lastRet = -1; // 最近的被返回的元素的索引; 如果没有返回-1。
int expectedModCount = modCount;
/**
- 判断是否有下一个元素
*/
public boolean hasNext() {
//如果下一个要返回的元素的索引不等于ArrayList的实际大小,则返回false
return cursor != size;
}
/**
- 返回下一个元素
*/
@SuppressWarnings(“unchecked”)
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
/**
- 删除最近的一个被返回的元素
*/
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
@Override
@SuppressWarnings(“unchecked”)
public void forEachRemaining(Consumer<? super E> consumer) {
Objects.requireNonNull(consumer);
final int size = ArrayList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
}
Iterator
import java.util.function.Consumer;
public interface Iterator {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException(“remove”);
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}
Itr.java
ArrayList的内部类
7.2 ListIterator
ListIterator是一个更加强大的Iterator的子类型。它只能用于各种List类的访问。它最大的优点是可以双向移动。它还可以产生相对于迭代器在列表中指向的当前位置的前一个和后一个元素的索引,并且可以使用set()方法替换它访问过的最后一个元素。
Kafka进阶篇知识点

Kafka高级篇知识点

44个Kafka知识点(基础+进阶+高级)解析如下

由于篇幅有限,小编已将上面介绍的**《Kafka源码解析与实战》、Kafka面试专题解析、复习学习必备44个Kafka知识点(基础+进阶+高级)都整理成册,全部都是PDF文档**
Exception ex) {
throw new ConcurrentModificationException();
}
}
@Override
@SuppressWarnings(“unchecked”)
public void forEachRemaining(Consumer<? super E> consumer) {
Objects.requireNonNull(consumer);
final int size = ArrayList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
}
Iterator
import java.util.function.Consumer;
public interface Iterator {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException(“remove”);
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}
Itr.java
ArrayList的内部类
7.2 ListIterator
ListIterator是一个更加强大的Iterator的子类型。它只能用于各种List类的访问。它最大的优点是可以双向移动。它还可以产生相对于迭代器在列表中指向的当前位置的前一个和后一个元素的索引,并且可以使用set()方法替换它访问过的最后一个元素。
Kafka进阶篇知识点
[外链图片转存中…(img-OvqHNM77-1715624408790)]
Kafka高级篇知识点
[外链图片转存中…(img-pcE3xF7F-1715624408790)]
44个Kafka知识点(基础+进阶+高级)解析如下
[外链图片转存中…(img-ojUQWgkU-1715624408790)]
由于篇幅有限,小编已将上面介绍的**《Kafka源码解析与实战》、Kafka面试专题解析、复习学习必备44个Kafka知识点(基础+进阶+高级)都整理成册,全部都是PDF文档**















 2859
2859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









