







获取所有的图片
allImageList = []
for k in urlList:
try:
request = urllib.request.Request(k, headers=headers)
r = urllib.request.urlopen(request)
html = r.read().decode().replace(‘\n’,‘’)
imgList = re.findall(r’<img.*?src=“(.*?)”', html, re.S)
allImageList+=imgList
except Exception as e:
pass
这里的请求其实也是要用多线程爬取的,所有后续会补上!
#### 1.2.4 数据保存 (单线程)
for i, img in enumerate(allImageList[:102]):
print(f"正在保存第{i + 1}张图片 路径:{img}“)
resp = requests.get(img)
with open(f’./image/{img.split(”/")[-1]}', ‘wb’) as f: # 保存到这个image路径下
f.write(resp.content)
#### 1.2.4 数据保存 (多线程)
* 引入多进程模块
import threading
多线程
def download_imgs(imgList,limit):
threads = []
T = [
threading.Thread(target = download, args=(url,i))
for i, url in enumerate(imgList[:limit + 1])
]
for t in T:
t.start()
threads.append(t)
return threads
* 编写下载函数
def download(img_url,name):
resp = requests.get(img_url)
try:
resp = requests.get(img_url)
with open(f’./images/{name}.jpg’, ‘wb’) as f:
f.write(resp.content)
except Exception as e:
print(f"下载失败: {name} {img_url} -> {e}“)
else:
print(f"下载完成: {name} {img_url}”)
就很随机
## 实验 2
### 2.1 题目
>
> 使用scrapy框架复现作业①
>
>
>
### 2.2 思路
#### 2.2.1 setting.py
* 解除限制
ROBOTSTXT_OBEY = False
* 设置保存图片的路径
IMAGES_STORE = r’.\images’ # 保存文件的路径
* 打开pipelines
ITEM_PIPELINES = {
‘weatherSpider.pipelines.WeatherspiderPipeline’: 300,
}
* 设置请求头
DEFAULT_REQUEST_HEADERS = {
‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’,
‘Accept-Language’: ‘en’,
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.16 Safari/537.36’,
}
#### 2.2.2 item.py
* 设置要爬取的字段
class WeatherspiderItem(scrapy.Item):
number = scrapy.Field()
pic_url = scrapy.Field()
#### 2.2.3 wt\_Spider.py
* 发送请求
def start\_requests(self):
yield scrapy.Request(self.start_url, callback=self.parse)
* 获取页面所有的`a标签`
def parse(self, response):
html = response.text
urlList = re.findall('<a href="(.\*?)" ', html, re.S)
for url in urlList:
self.url = url
try:
yield scrapy.Request(self.url, callback=self.picParse)
except Exception as e:
print("err:", e)
pass
* 再次请求所有的a标签下面的网址,再找所有的图片返回
def picParse(self, response):
imgList = re.findall(r'<img.\*?src="(.\*?)"', response.text, re.S)
for k in imgList:
if self.total > 102:
return
try:
item = WeatherspiderItem()
item['pic\_url'] = k
item['number'] = self.total
self.total += 1
yield item
except Exception as e:
pass
* 那么与存入数据库类似,`数据处理`全部都应该在`pipelines.py`中处理,也就是说,pipelines还是要发送请求
#### 2.2.4 pipelines.py
* 导入setting信息
from weatherSpider.settings import IMAGES_STORE as images_store # 读取配置文件的信息
from scrapy.pipelines.images import ImagesPipeline
settings = get_project_settings()
* 编写保存函数
def get\_media\_requests(self, item, info):
image_url = item["pic\_url"]
yield Request(image_url)
* 这里优化的话,应该保存文件的时候重命名会好一点!
## 实验 3
### 3.1 题目
>
> 爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在 imgs路径下。
>
>
>
### 3.2 思路
#### 3.2.1 setting.py
* 解除限制
ROBOTSTXT_OBEY = False
* 数据库配置
HOSTNAME = ‘127.0.0.1’
PORT = 3306
DATABASE = ‘scrapy_douban’
USERNAME = ‘root’
PASSWORD = ‘root’
* 请求头
DEFAULT_REQUEST_HEADERS = {
‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’,
‘Accept-Language’: ‘en’,
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.16 Safari/537.36’,}
* 开启pipelines
ITEM_PIPELINES = {
‘doubanSpider.pipelines.DoubanspiderPipeline’: 300,
}
#### 3.2.2 item.py
* 定义爬取的内容字段
class DoubanspiderItem(scrapy.Item):
number = scrapy.Field()
name = scrapy.Field()
direct = scrapy.Field()
actor = scrapy.Field()
info = scrapy.Field()
score = scrapy.Field()
movie_img = scrapy.Field()
#### 3.2.3 db\_Spider.py
* 观察网页,发现翻页规律
第二页

第三页

所以我们就看到规律了!
* 初始信息
page = 0
start_url = 'https://movie.douban.com/top250'
next_url = 'https://movie.douban.com/top250?start=%s&filter='
* 爬取信息
lis = response.xpath('//\*[@id="content"]/div/div[1]/ol/li')
for k in lis:
number = k.xpath('div/div[1]/em/text()').extract()
title = k.xpath('div/div[2]/div[1]/a/span[1]/text()').extract()
directT = k.xpath('div/div[2]/div[2]/p[1]/text()').extract()
score = k.xpath('div/div[2]/div[2]/div/span[2]/text()').extract()
info = k.xpath('div/div[2]/div[2]/p[2]/span/text()').extract()
img_url = k.xpath('div/div[1]/a/img/@src').extract()
tmp = directT[0].split("主演:")
* 错误处理
这里有两个地方需要处理
1. 导演和演员
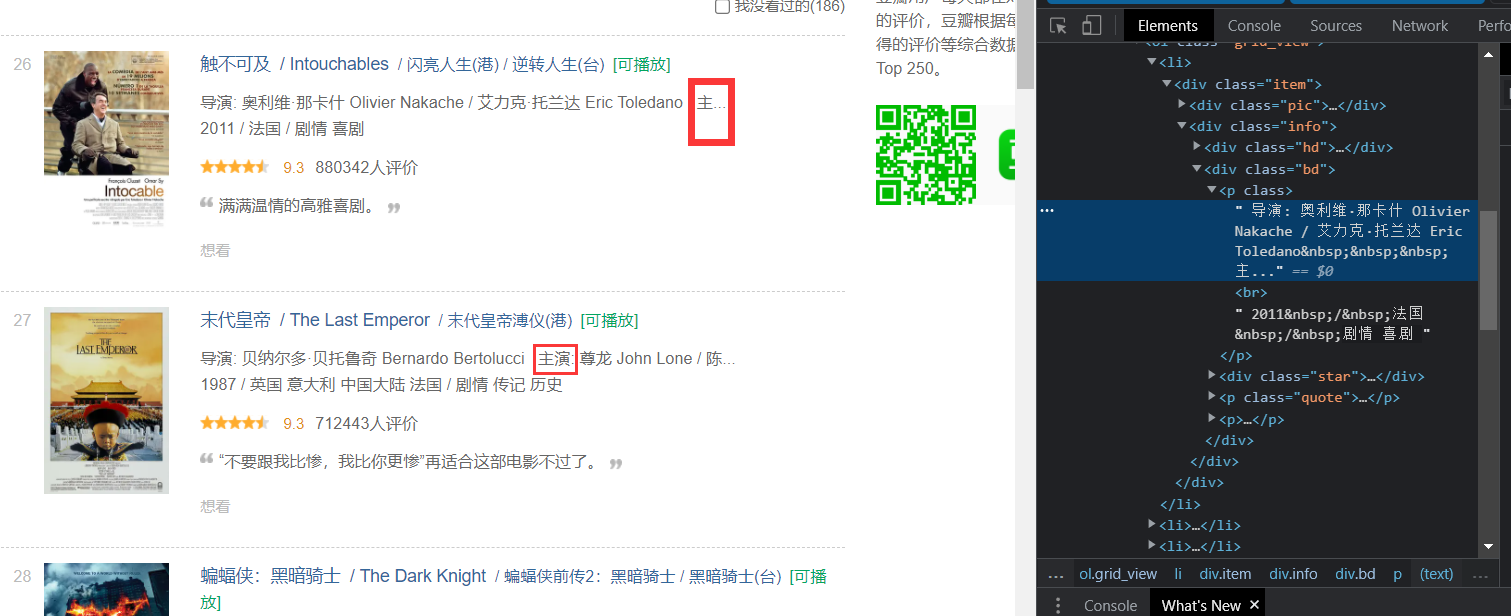
我是按照字符串分割进行选择这个`导演`和`主演`的!所有可能只出现`主`这个字的情况
所有进行以下处理
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化学习资料的朋友,可以戳这里无偿获取](https://bbs.csdn.net/topics/618317507)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 40
40

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









