







总结
这份面试题几乎包含了他在一年内遇到的所有面试题以及答案,甚至包括面试中的细节对话以及语录,可谓是细节到极致,甚至简历优化和怎么投简历更容易得到面试机会也包括在内!也包括教你怎么去获得一些大厂,比如阿里,腾讯的内推名额!
某位名人说过成功是靠99%的汗水和1%的机遇得到的,而你想获得那1%的机遇你首先就得付出99%的汗水!你只有朝着你的目标一步一步坚持不懈的走下去你才能有机会获得成功!
成功只会留给那些有准备的人!

也就是可以通过excludes指定不想要显示的字段,很好理解
二、高阶查询
1布尔组合查询
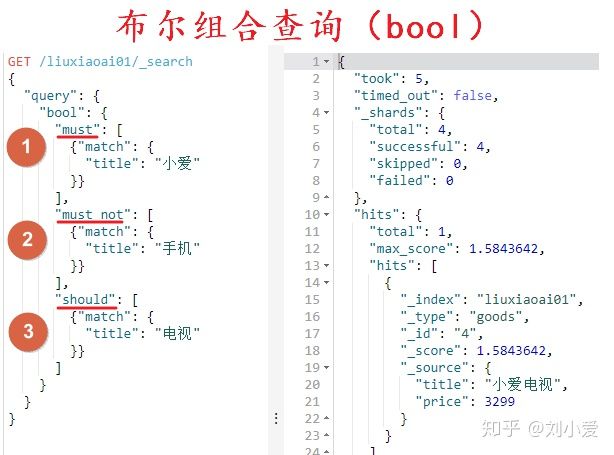
关键字是bool,它本身并不是一种查询方式,而是将查询方式通过逻辑运算组合起来了。
①must
翻译过来就是必须的意思,可以填写多个查询条件(中括号本身表示的也就是数组)
多个查询条件通过must连接,相当于以前常用的and,说白了也就是逻辑运算符“与”。
②must_not
刚好就和上述must相反,说白了也就是逻辑运算符“与”。
③should
通用的道理:多个查询条件通过should连接,相当于以前常用的or,说白了也就是逻辑运算符“与”。
ps:关于其格式使用,不要看它图中好像挺复杂的样子,其实都可以通过工具有提示,并且这些写多了基本也就知道了。
2范围查询
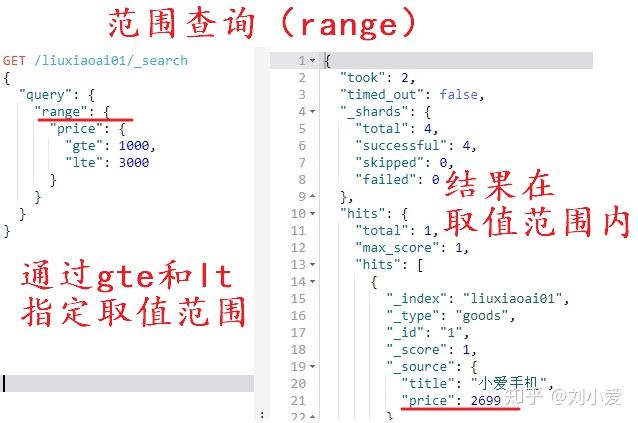
商品都有自己的价格,用户可以通过设定价格区间搜索到对应的商品。
range就可以实现范围查询,其中通过四种字符说明查询的区间。
-
gt:表示大于
-
get:表示大于等于
-
lt:表示小于
-
lte:表示小于等于
3模糊查询
实际应用中用户搜索时输入的词条与实际词条存在偏差,但也能搜索到对应的数据,这就需要使用到模糊查询了。
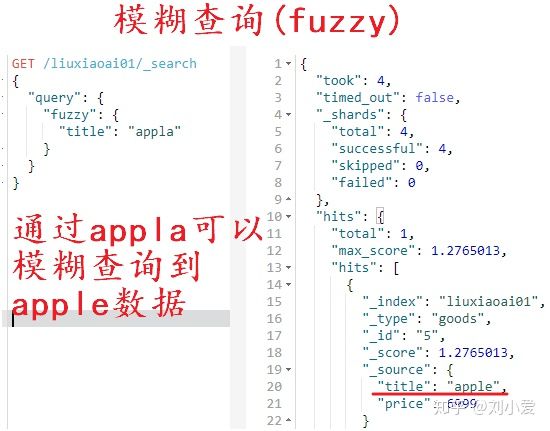
关键字是fuzzy,翻译过来也就是模糊的。
上述例子中,我添加了一个apple数据,查询的时候通过appla就可以模糊查询到,但是偏差的编辑距离不能超过2,其中也可以通过fuzziness来指定允许的编辑距离。
此外还有过滤,排序这些操作,并且上述这些操作一般都是组合起来使用的,其实无外乎就是记住关键字:
-
关于过滤对应的也就是filter。
-
关于排序也就对应着sort。
三、聚合aggregations
Elasticsearch中的聚合包含多种类型,最常用的有两种:
①桶(bucket)
其实蛮好理解的,比如上海现在一直在执行的垃圾分类,就有多个桶:干垃圾桶、湿垃圾桶、有害垃圾桶以及可回收物桶。
所以桶的作用就在于按照某种方式对数据进行分组,它只负责分组,不进行运算。
②度量(metrics)
也就是我们以前学的聚合函数,比如求平均值、最大值、最小值以及求和…等这些运算。
2聚合的使用

在使用之前,我们需要创建一个索引库并添加数据,作为聚合的测试数据。
cars索引库,有color和make两个字段,字段类型都为keyword,也就是不分词。
也就是关于汽车的一个索引库,有颜色和生产商这两个字段。
根据我们这两天的学习情况就可以简单地实现,具体添加了哪些数据就不做说明了。
桶的使用

size表示是查询条数,我这里设置为1,主要在于一个了解,重点在于聚合结果。
aggs也就是聚合aggregations的简写,说明这是一个聚合查询:
-
popular_make:聚合名,这是自定义的一个名称,尽量见名知义即可。
-
terms:划分桶的方式,有多种方式,这里是根据词条划分。
-
field:划分桶的字段,这里根据make划分。
这样聚合之后,索引库中的数据就根据field这个字段划分成了4个桶:例子中也就是"honda"、“ford”、“toyota”、“bmw”。
elasticsearch中关于桶的划分方式有多种:
最后

















 85
85











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









