








网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
⏩你是不是曾经出现使用分布式进行性能测试,出现很多 4xx 系列错误,而单机执行性能测试却没有;你是不是曾经出现,分布式时错误率升高,而单机时,同并发数,错误率要低很多;你是不是曾经出现,分布式请求,服务端日志,有大量锁冲突?
这些问题,如果你脚本中使用了‘CSV Data Set Config’,那么这些错误,很可能就是因为这个元件每次读数据只能从第 1 行开始读取的原因造成的。
这个坑,我曾经也遇到了,而且一度让我痛苦了几天,不过,后来我找到 4 种解决办法,今天,我就来给大家讲一种技术难度最低的方法。
☑️打开 jmeter 的插件管理,在 ‘available plugins’中搜索‘CSV’,勾选一个叫 ‘Random CSV Data Set’的插件,点击右下角的‘Apply Changes and Restart JMeter’下载安装这个插件。待下载成功自动重启之后,在 jmeter 的配置元件中,我们将找到‘bzm - Random CSV Data Set Config’元件。
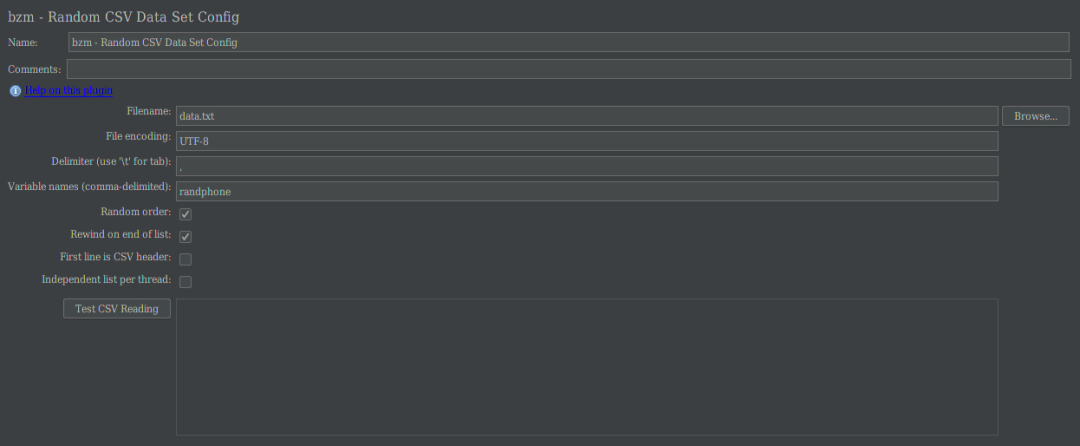
你可以**点击下面的‘Test CSV Reading’来看下数据的顺序,你会发现,每次取的数据顺序都是不一样的。**这样,就很好解决了分布式时取数相同的问题了。方法非常简单。
⏩接下来,我们来对比看下这个元件的性能。
首先添加 ‘CSV Data Set Config’元件,读取一份大于 10000 行的数据文件,定义一个变量接收,然后,用一个调试取样器,应用这个变量, 设在 1000 的并发用户,持续运行 120s,保存脚本,采用 CLI 模式运行,查看运行时资源使用情况。

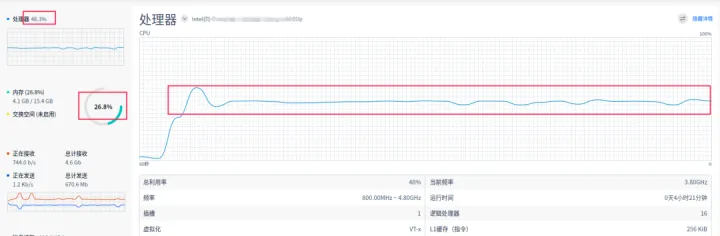
从监控到数据看,1000 的并发,120 秒中内,总共执行了 59830295 次请求,平均每秒 498141.6 次/s,我本机 CPU 使用率上升到约 48.3%,内存使用率约为 26.8%。
⏩现在,把元件换成 ‘bzm - Random CSV Data Set Config’,其他都不变了。采用 CLI 模式来运行,查看监控数据。


从监控到数据看,1000 的并发,120 秒中内,总共执行了 20860718 次请求,平均每秒 172912.8 次/s,我本机 CPU 使用率上升到约 66.5%,内存使用率约为 26.7%。
☑️从两个元件的测试结果来看,官方的 CSV Data Set Config 性能要优于 bzm - Random CSV Data Set Config,实际工作中,你可以根据你的实际情况来选择。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
**















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









