




既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
这时候我们基本确定瓶颈在logstash上。logstash部署在服务端,主要处理接收filebeat(部署在节点机)推送的日志,对其进行正则解析,并将结构化日志传送给ES存储。对于每一行日志进行正则解析,需要耗费极大的计算资源。而节点CPU负载恰巧又不高,这个时候我们就要想办法拓宽logstash的pipeline了,毕竟我们一天要收集18亿条日志。
ELFK部署架构图如下所示:
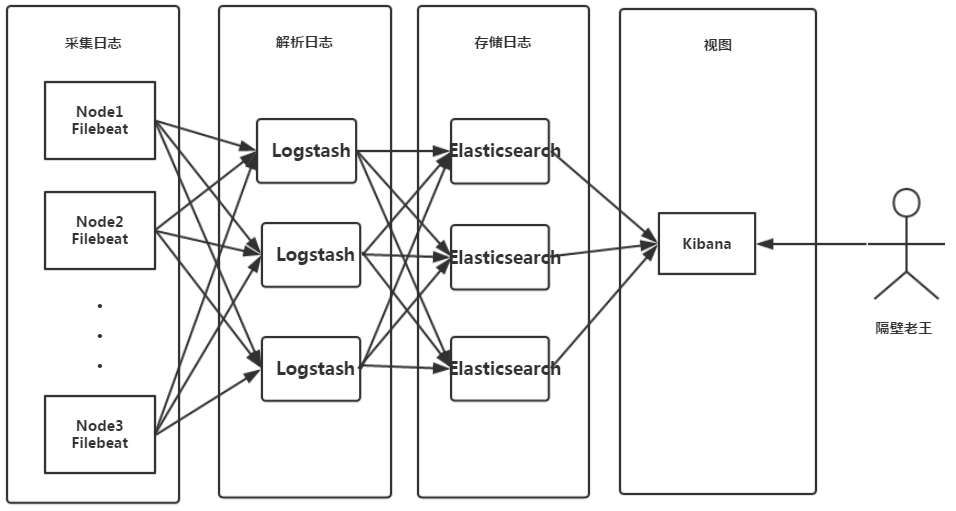
影响logstash性能因素如下:
logstash是一个pipeline,数据流从input进来,在filter进行正则解析,然后通过output传输给ES。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 795
795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









