







性能调节
一、性能故障排除
Logstash建议在修改配置项以提高性能的时候,每次只修改一个配置项并观察其性能和资源消耗(cpu、io、内存)。性能检查项包括:
1、检查input和output设备
日志存储的速度和它所连接的服务的速度一样快。日志存储只能像输入和输出目的地一样快速地消耗和生成数据!
1、检查系统指标
1)、CPU
启动后需要检查CPU是否被大量使用,检查命令top -H(检查所有的进程,特别关注logstash的进程使用资源情况)。如果CPU使用率一直很高(我遇到过cpu使用率一直为200%左右),则直接查询下面检查jvm堆内存信息。
2)、Memory
Logstash运行在java虚拟机上,所以依赖为其分配的堆内存。如果应用程序使用的总内存超过物理内存,则会导致内存交换(可参见es文档中的内存交换部分)。
3)、io
1、磁盘io
需要定时进行检查磁盘饱和度:Logstash的很多文件处理插件可能会导致磁盘饱和;由于配置或位置原因可能导致logstash写入大量的error日志,导致磁盘饱和;所以在linux上建议使用iostat, dstat等共计进行监控。
2、网络io
Logstash的input、output插件的执行可能导致大量的网络io的堆积,可以使用dstat or iftop等工具进行监控。
2、检查jvm堆
1)、如果堆大小过低,CPU利用率通常会通过屋顶,从而导致JVM不断地进行垃圾收集。
2)、快速检查这个问题的方法是将堆大小增加一倍,看看性能是否有所改善。不要将堆大小增加到物理内存的数量。至少为操作系统和其他进程留出1 GB的空间。
3)、使用专门的工具对jvm进行精确的监控
4)、一定要确保将最小(Xms)和最大值(Xmx)堆分配大小设置为相同的值,以防止堆在运行时调整大小,这是一个非常昂贵的过程(我使用yum安装之后的值就不相等,再加上分配的内存过小,导致CPU一致非常的高)。
3、检查工作线程设置
1)、可以使用-w以增加output和filter的工作线程数(尽量设置为cpu核数的倍数)。
2)、每个output插件都可以单独设置其线程数(提高插件细性能),但是设置值不要大于pipeline的工作线程数。
3)、可以配置pipeline.batch.size参数,比如当你使用了Elasticsearch的output插件的时候,经常会使用批量操作。
二、调优和剖析日志记录的性能
1、配置参数调优
可以通过调节以下配置项,对性能进行调优:
1)、pipeline.workers
该参数可控制output或filter插件的工作线程数(只能设置正整数),当发现事件正在备份或CPU没有饱和,则可以增加工作线程,以提高性能。
2)、pipeline.batch.size
设置批量执行event的最大值,该值是用于input的批量处理事件值,再打包发送给filter和output,增加该值可以在一定范围内提高性能,但是需要增加额外的内存开销。
3)、pipeline.batch.delay
批处理的最大等待值(input需要按照batch处理的最大值发送到消息队列,但是不能一直等,所以需要一个最大的超时机制)。
2、默认管道设置的修改建议
1)、管道中所有运行中的event都与配置参数:pipeline.workers和pipeline.batch.size有关,而间歇接收大型事件的管道需要足够的内存来处理这些峰值,需要相应的设置LS_HEAP_SIZE值。
2)、测量每一个参数的变化,以确保它增加而不是减少性能。
3)、确保logstash额外留足够的内存,以应对突然增加的事件消耗。
4)、一般pipeline.workers的数量要大于Cpu的核心数,因为output的io等待会消耗大量的空闲时间。
5)、Java中的线程有名称,您可以使用jstack、top和VisualVM图形工具来确定给定线程使用哪些资源。
6)、在Linux平台上,logstash用一些描述性的东西来标记所有的线程。例如,输入显示为基础。
3、JVM heap
堆内存对logstash来说的非常重要的,一般要求将初始值和最大值设置为一致(防止动态调整堆内存大小的消耗),并且需要对堆内存进行调整,调整的同时需要使用VisualVM工具来对堆进行检测。特别的Monitor 窗格,对于检查堆分配是否足以满足当前工作负载非常有用。
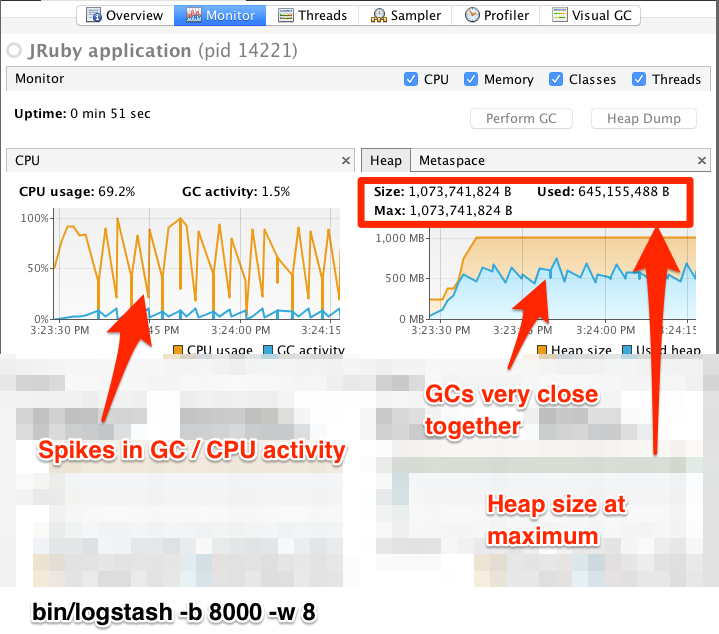
如下示例图1是配置了太多的event,而图二则配置了合适的event。分别如下:
pipeline_overload.png
pipeline_correct_load.png
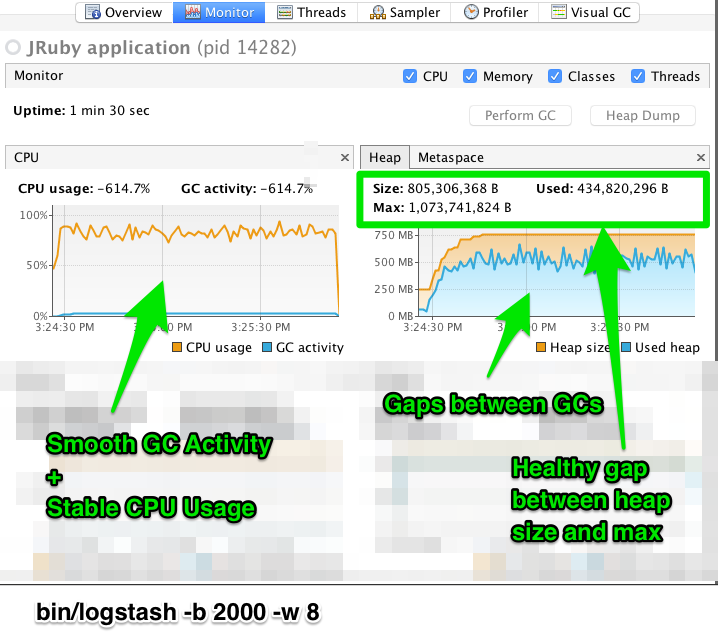
在第一个例子中,我们看到CPU没有得到很好的使用。实际上,JVM经常需要停止VM的 full GC。Full GC是过度内存压力的常见症状(我们项目遇到过)。这在CPU图表上的spiky模式中是可见的。在更高效配置的示例中,GC图形模式更加平滑,CPU使用的方式更加统一。您还可以看到,在分配的堆大小之间有足够的空间,并且允许最大限度地允许JVM GC使用大量的空间。
使用与优秀的VisualGC插件类似的工具来检查深度GC统计数据,表明在高效的Eden 区GC中,分配过多的虚拟机花费的时间非常少,而在资源密集型的老代 full GCs中花费的时间比较少。















 495
495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









