







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
import numpy as np
a=np.arange(12).reshape(3,4)
print(a[[0,2],[1,3]])#取相应位置的四个元素
print(a[0:2,1:3])#取行和列的元素
a[a<4]=2 #布尔运算
a[a>5]=0
np.where(a<5,0,1) #三元运算符
b=a.clip(2,3)#小于1的替换为10,大于1的替换为了18
print(a)
print(b)
一维数组
arr[5] #用整数作为下标可以获取数组中的某个元素
arr[3:5] #用范围作为下标获取数组的一个切片,包括arr[3]不包括arr[5]
arr[:5] #省略开始下标,表示从arr[0]开始
arr[-1] #下标可以使用负数,-1表示从数组后往前数的第一个元素
arr[1:-1:2] #第三个参数表示步长,2表示隔一个元素取一个元素,第2,4,…后1
数组值修改
arr[2:4] = 100,101 #下标还可以用来修改元素的值
多维数组3X5
arr[0,3:5] #索引第0行中第3和第4列的元素
arr[2:] #取第3行之后的所有行
arr[[0,2,3]] #取第0,2,3行数据
arr[1:,2:] #索引第2和第3行中第3列、第4列和第5列的元素
arr[:,2] #索引第2列的元素
print(a[[0,2],[1,3]])
print(a[0:2,1:3])
arr[1:,(0,2,3)] #索引第2、3行中第0、2、3列的元素
#mask是一个布尔数组,它索引第1、3行中第2列的元素
mask = np.array([1,0,1],dtype = np.bool)
print('索引结果为:',arr[mask,2])
6.改变数组形态
arr.reshape(3,4) #设置数组的形状
arr.reshape(3,4).ndim) #查看数组维度
np.arange(12).reshape(3,4) #改变一维数组的形状
arr.ravel() #数组展平
arr.flatten() #横向展平 a=np.arange(12).reshape(12,)
arr.flatten('F') #纵向展平
np.hstack((arr1,arr2)) #hstack函数横向组合
np.vstack((arr1,arr2)) #vstack函数纵向组合
np.concatenate((arr1,arr2),axis = 1) #concatenate函数横向组合
np.concatenate((arr1,arr2),axis = 0) #concatenate函数纵向组合
np.hsplit(arr, 2) #hsplit函数横向分割
np.vsplit(arr, 2) #vsplit函数纵向分割
np.split(arr, 2, axis=1) #split函数横向分割
np.split(arr, 2, axis=0) #split函数纵向分割
t[[1,2],:]=t[[2,1],:] #行交换
t[:,[0,2]]=t[:,[2,0]] #列交换
【案例】两个国家的数据方法一起来研究分析,同时保留国家的信息(每条数据的国家来源),应该怎么办
#两个国家的数据方法一起来研究分析,同时保留国家的信息(每条数据的国家来源),应该怎么办
import numpy as np #导入NumPy库
import matplotlib.pyplot as plt
us_file_path="./US\_video\_data\_numbers.csv"
gb_file_path="./GB\_video\_data\_numbers.csv"
#加载国家数据
us_data=np.loadtxt(us_file_path,dtype=int,delimiter=",",skiprows=0,usecols=None,unpack=False)
gb_data=np.loadtxt(gb_file_path,dtype=int,delimiter=",",skiprows=0,usecols=None,unpack=False)
#添加国家信息
#构造全为0的数据
zeros_data=np.zeros((us_data.shape[0],1)).astype(int)
ones_data=np.ones((gb_data.shape[0],1)).astype(int)
#拼接两组数据
us=np.hstack((us_data,zeros_data))
gb=np.hstack((gb_data,ones_data))
data=np.vstack((us,gb))
print(data)
7.创建numpy矩阵
M1=np.mat("1 2 3;4 5 6;7 8 9") #使用分号隔开数据
M2=np.matrix([[1,2,3],[4,5,6],[7,8,9]]) #使用matrix创建矩阵
M3=np.bmat("M1,M2") #使用bmat创建矩阵
8.矩阵运算
matr1+matr2 #矩阵相加
matr1-matr2 #矩阵相减
matr1\*matr2 #矩阵相乘
np.multiply(matr1,matr2)) #对应元素相乘
matr1.T #转置
matr1.H #共轭转置(实数的共轭就是其本身)
matr1.I #逆矩阵
matr1.A #返回二维数组的视图
9.ufunc函数
不同形状的数组之间执行算术运算具有广播机制:

x = np.array([1,2,3])
y = np.array([4,2,6])
x + y #数组相加
x - y #数组相减
x \* y #数组相乘
x / y #数组相除
x \*\* y #数组幂运算:1,4,729
x < y #[ True False False]
x > y;x == y;x >= y;x <= y;x != y
np.all(x == y)) #np.all()表示逻辑and:True
np.any(x == y)) #np.any()表示逻辑or :False
10.利用numpy进行统计分析
(1) 二进制数据存储
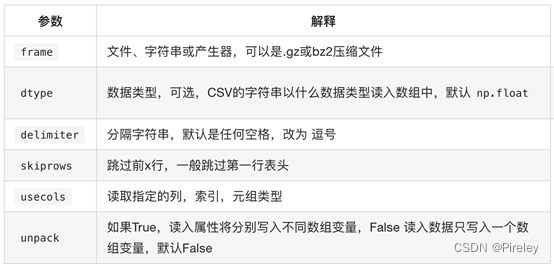
np.loadtxt(fname,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)
import numpy as np #导入NumPy库
arr = np.arange(100).reshape(10,10) #创建一个数组
np.save("F:/python/save\_arr",arr) #保存数组np.save("save\_arr.npy",arr)
print('保存的数组为:\n',arr)
二进制文件
np.save("F:/python/save\_arr",arr) #单个数组存储
np.savez('../savez\_arr',arr1,arr2) #多个数组存储
np.load("../tmp/save\_arr.npy") #读取含有单个数组的文件
np.load("../tmp/savez\_arr.npz") #读取含有多个数组的文件
print('读取的数组1为:',loaded_data1['arr\_0'])
print('读取的数组2为:',loaded_data1['arr\_1'])
文本文件
arr = np.arange(0,12,0.5).reshape(4,-1)
print('创建的数组为:',arr)
#fmt ="%d"为指定保存为整数
np.savetxt("../tmp/arr.txt", arr, fmt="%d", delimiter=",")
#读入的时候也需要指定逗号分隔
loaded_data = np.loadtxt("../tmp/arr.txt",delimiter=",")
print('读取的数组为:',loaded_data)
loaded_data = np.genfromtxt("../tmp/arr.txt", delimiter = ",")
print('读取的数组为:',loaded_data)
(2) 统计分析
1) 排序Sort,Argsort,lexsort
Sort
np.random.seed(42) #设置随机种子
arr = np.random.randint(1,10,size = 10) #生成随机数
arr.sort() #直接排序
arr = np.random.randint(1,10,size = (3,3)) #生成3行3列的随机数
arr.sort(axis = 1) #沿着横轴排序
arr.sort(axis = 0) #沿着纵轴排序
Argsort
print('排序后数组为:',arr.argsort()) #返回值为重新排序值的下标
lexsort
a = np.array([3,2,6,4,5])
b = np.array([50,30,40,20,10])
c = np.array([400,300,600,100,200])
d = np.lexsort((a,b,c)) #lexsort函数只接受一个参数,即(a,b,c)
#多个键值排序是按照最后一个传入数据计算的
print('排序后数组为:',list(zip(a[d],b[d],c[d])))
2) 去重unique与重复数据
去重
names = np.array(['小明', '小黄', '小花', '小明',
'小花', '小兰', '小白'])
print('创建的数组为:',names)
print('去重后的数组为:',np.unique(names))
重复
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
996)]
[外链图片转存中…(img-mtDcCzo5-1715280720997)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









