







NumPy简介
NumPy是一个Python科学计算的基础包,它不仅是Python中使用最多的第三方库,而且还是SciPy,Pandas等数据科学的基础库。NumPy主要提供了以下内容。
(1)快速高效的多维数组对象ndarray。
(2)对数组执行元素级计算以及直接对数组执行数学运算的函数。
(3)读/写硬盘上基于数组的数据集的工具。
(4)线性代数运算、傅里叶变换及随机数生成的功能。
(5)将C、C++、Fortran代码集成到Python的工具。
除了为Python提供快速的数组处理能力外,NumPy在数据分析方面还有另外-个主要作用,即作为算法之间传递数据的容器。对于数值型数据,使用NumPy数组存储和处理数据要比使用内置的Python数据结构高效得多。此外,由低级语言(比如C和Fortran)编写的库可以直接操作NumPy数组中数据,无须进行任何数据复制工作。
NumPy存在的原因
我们都知道Python中的list实际上相当于一个数组的结构,且其中的元素可以是任意对象,而NUmPy中的一个关键数据类型就是关于数组的,那为什么还存在这样一个第三方的数据结构呢???
1、效率问题
实际上,标准的 Python 中,用列表 list 保存数组的数值。列表中 list 保存的是对象的指针。虽然在 Python 编程中隐去了指针的概念,但是数组有指针,Python 的列表 list 其实就是数组。这样如果我要保存一个简单的数组[0,1,2],就需要有 3 个指针和 3 个整数的对象,这样对于 Python 来说是非常不经济的,浪费了内存和计算时间。
2、内存分布问题
同时,列表 list 的元素在系统内存中是分散存储的,而 NumPy 数组存储在一个均匀连续的内存块中。这样数组计算遍历所有的元素,不像列表 list 还需要对内存地址进行查找,从而节省了计算资源。
3、内存访问模式问题
另外在内存访问模式中,缓存会直接把字节块从 RAM 加载到 CPU 寄存器中。因为数据连续的存储在内存中,NumPy 直接利用现代 CPU 的矢量化指令计算,加载寄存器中的多个连续浮点数。另外 NumPy 中的矩阵计算可以采用多线程的方式,充分利用多核 CPU 计算资源,大大提升了计算效率。
当然除了使用 NumPy 外,你还需要一些技巧来提升内存和提高计算资源的利用率。一个重要的规则就是:避免采用隐式拷贝,而是采用就地操作的方式。举个例子,如果我想让一个数值 x 是原来的两倍,可以直接写成 x*=2,而不要写成 y=x*2。
NumPy中的两个重要对象
一、 ndarray
介绍: 它是一个存储单一数据类型的多维数组,解决了多维数组的问题,之后简称“数组”。
数组属性
ndim数组轴(维度)的个数,轴的个数被称作秩,每一个线性的数组成为一个轴(axes),其实秩就是描述轴的数量。shape数组的维度, 例如一个2排3列的矩阵,它的shape属性将是(2,3),这个元组的长度显然是秩,即维度或者ndim属性size数组元素的总个数,等于shape属性中元组元素的乘积。dtype一个用来描述数组中元素类型的对象,可以通过创造或指定dtype使用标准Python类型。不过NumPy提供它自己的数据类型。itemsize数组中每个元素的字节大小。例如,一个元素类型为float64的数组itemsiz属性值为8(=64/8),又如,一个元素类型为complex32的数组item属性为4(=32/8).
创建数组
array() - 创建一维或多维数组。
np.array(object, dtype=None, copy=True, order=’K’, subok=False, ndmin=0)
- object — list或tuple对象。强制参数。
- dtype — 数据类型。可选参数。
- copy — 默认为True,对象被复制。可选参数。
- order — 数组按一定的顺序排列。C - 按行;F - 按列;A - 如果输入为F则按列排列,否则按行排列;K - 保留按行和列排列。默认值为K。可选参数。
- subok — 默认为False,返回的数组被强制为基类数组。如果为True,则返回子类。可选参数。
- ndmin — 最小维数。可选参数。
import numpy as np
a = np.array([1, 2, 3])
b = np.array([[1, 2, 3,4], [4, 5, 6,7], [7, 8, 9,10]])
b[1,1]=10
print a.shape
print b.shape
print a.dtype
print b
你也可以重置数组的属性
b.shape = 4,3
print b
其实上述的例子,都是先创建一个Python序列,然后通过array函数将其转换为数组,这样做显然效率不高,因此,NumPy提供了很多专门用来创建数组的函数:
arange:类似于range函数,指定开始值、终值、和步长来创建一维数组,创建的数组不含终值。
print(np.arange(0,10,1))
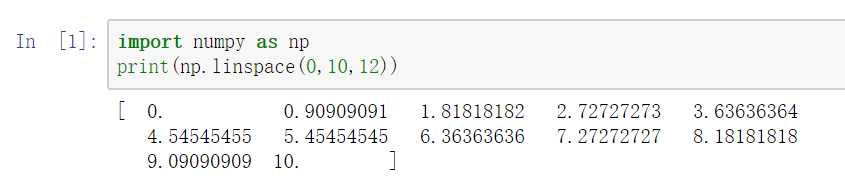
linspace:指定开始值、终值、和元素个数来创建一维数组,默认设置包含终值。
print(np.linspace(0,10,12))
logsapce:生成1(100)-100(102)的20个元素的等比数列
print(np.logspace(0,2,20))

NumPy还提供了其他函数来创建特殊数组,如zeros,eye,diag,one等
zeros:创建值为0的数组
print(np.zeros((2,3)))

eye:创建值类似于单位矩阵的数组
print(np.eye(3))

数组类型类型
ndarray对象中的元素类型可以一致,也可以不一致。
但是如果我们在创建 ndarray对象时使用了 dtype 参数,则数组对象元素类型必须一致,否则报错
例如
f=np.array(range(5),dtype=np.int64)
NumPy以提供高效率的数组著称,这主要归功于索引的易用性,这里介绍一维数组和多维数组的索引方式。
一维数组的索引
一维数组的索引方式很简单,与python中的list索引方式一致
比如对于一维数组
arr = np.arange(10)
#用下标
print(arr[5])
#用切片方式,包括3,不包括5
print(arr[3:5])
#省略前索引
print(arr[:5])
#使用负数索引
print(arr[-1])
#也可以通过索引修改元素的值
arr[2:4] = 100,101
#设置步长
arr[1:-1:2]#2表示每隔一个元素取一个元素
多维数组的索引
比如对于二维数组
arr = np.array([[1,2,3,4,5],[4,5,6,7,8],[7,8,9,10,11]])
#索引第0行第三列和第四列元素【4,5】
print(0,3:5)
#索引第二行第三行中3-5列元素
print(arr[1:,2:])
#索引第二列元素
print(arr[:,2])
结构数组:通过dtype定义结构类型,然后在定义数组的时候array中指定结构数组类型为dtype = persontype
import numpy as np
persontype = np.dtype([('name', np.str_, 16),('age',np.int32), ('chinese', np.int32), ('english', np.int32), ('math', np.int32)])
peoples = np.array([("ZhangFei",32,75,100, 90),("GuanYu",24,85,96,88.5),
("ZhaoYun",28,85,92,96.5),("HuangZhong",29,65,85,100)],
dtype=persontype)
ages = peoples[:]['age']
chineses = peoples[:]['chinese'] #[:]表示选取所有行,['age']选取age列
maths = peoples[:]['math']
englishs = peoples[:]['english']
print np.mean(ages)
print np.mean(chineses)
print np.mean(maths)
print np.mean(englishs)
二、ufunc
介绍: 它是解决对数组进行处理的函数。它能够对数组中的每个元素进行函数操作,计算速度非常的块,因为它都是采用C语言编写的。
算术运算
通过NUmPy可以进行加减乘除,求n次方和取余操作。
x1 = np.arange(1,11,2)
x2 = np.linspace(1,9,5)
print np.add(x1, x2)
print np.subtract(x1, x2)
print np.multiply(x1, x2)
print np.divide(x1, x2)
print np.power(x1, x2)
print np.remainder(x1, x2)#np.mod(x1,x2)也可以
如果你想要对一堆数据有更清晰的认识,就需要对这些数据进行描述性的统计分析,比如了解这些数据中的最大值、最小值、平均值,是否符合正态分布,方差、标准差多少等等。它们可以让你更清楚地对这组数据有认知。
计算数组/矩阵中的最大值函数amax(),最小值函数amin()
import numpy as np
a = np.array([[1,2,3], [4,5,6], [7,8,9]])
print np.amin(a)
print np.amin(a,0)
print np.amin(a,1)
print np.amax(a)
print np.amax(a,0)
print np.amax(a,1)
amin() 用于计算数组中的元素沿指定轴的最小值。
- 对于一个二维数组 a,amin(a) 指的是数组中全部元素的最小值
- amin(a,0) 是按列排序,把元素看成了[1,4,7], [2,5,8], [3,6,9]三个元素,所以最小值为[1,2,3],
- amin(a,1) 是按行排序,把元素看成了[1,2,3], [4,5,6], [7,8,9]三个元素,所以最小值为[1,4,7]。
- 同理 amax() 是计算数组中元素沿指定轴的最大值。
这里有关于axis参数的解释:Python · numpy · axis
统计最大值最小值之差ptp()
a = np.array([[1,2,3], [4,5,6], [7,8,9]])
print np.ptp(a)
print np.ptp(a,0)
print np.ptp(a,1)
- 对于相同的数组 a,np.ptp(a) 可以统计数组中最大值与最小值的差,即 9-1=8。
- 同样 ptp(a,0) 统计的是沿着 axis=0 轴的最大值与最小值之差,即 7-1=6(当然 8-2=6,9-3=6,第三行减去第一行的 ptp 差均为 6)
- ptp(a,1) 统计的是沿着 axis=1 轴的最大值与最小值之差,即 3-1=2(当然 6-4=2, 9-7=2,即第三列与第一列的 ptp 差均为 2)。
统计数组的百分数percentile()
a = np.array([[1,2,3], [4,5,6], [7,8,9]])
print np.percentile(a, 50)
print np.percentile(a, 50, axis=0)
print np.percentile(a, 50, axis=1)
同样,percentile() 代表着第 p 个百分位数,这里 p 的取值范围是 0-100,如果 p=0,那么就是求最小值,如果 p=50 就是求平均值,如果 p=100 就是求最大值。同样你也可以求得在 axis=0 和 axis=1 两个轴上的 p% 的百分位数。
统计数组中的中位数median(),平均数mean()
a = np.array([[1,2,3], [4,5,6], [7,8,9]])
#求中位数
print np.median(a)
print np.median(a, axis=0)
print np.median(a, axis=1)
#求平均数
print np.mean(a)
print np.mean(a, axis=0)
print np.mean(a, axis=1)
你可以用 median() 和 mean() 求数组的中位数、平均值,同样也可以求得在 axis=0 和 1 两个轴上的中位数、平均值。你可以自己练习下看看运行结果。
统计数组中的加权平均值average()
a = np.array([1,2,3,4])
wts = np.array([1,2,3,4])
print np.average(a)
print np.average(a,weights=wts)
average() 函数可以求加权平均,加权平均的意思就是每个元素可以设置个权重,默认情况下每个元素的权重是相同的,所以 np.average(a)=(1+2+3+4)/4=2.5,你也可以指定权重数组 wts=[1,2,3,4],这样加权平均 np.average(a,weights=wts)=(11+22+33+44)/(1+2+3+4)=3.0。
统计数组中的标准差std(),方差var()
a = np.array([1,2,3,4])
print np.std(a)
print np.var(a)
方差的计算是指每个数值与平均值之差的平方求和的平均值,即 mean((x - x.mean())** 2)。标准差是方差的算术平方根。在数学意义上,代表的是一组数据离平均值的分散程度。所以 np.var(a)=1.25, np.std(a)=1.118033988749895。
三、NumPy排序
排序算法在 NumPy 中实现起来其实非常简单,一条语句就可以搞定。这里你可以使用 sort 函数:
sort(a, axis=-1, kind=‘quicksort’, order=None)
默认情况下使用的是快速排序;在 kind 里,可以指定 quicksort、mergesort、heapsort 分别表示快速排序、合并排序、堆排序。同样 axis 默认是 -1,即沿着数组的最后一个轴进行排序,也可以取不同的 axis 轴,或者 axis=None 代表采用扁平化的方式作为一个向量进行排序。另外 order 字段,对于结构化的数组可以指定按照某个字段进行排序。
a = np.array([[4,3,2],[2,4,1]])
print np.sort(a)
print np.sort(a, axis=None)
print np.sort(a, axis=0)
print np.sort(a, axis=1)
总结
















 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









