






前言
还记得我们之前就讲过学习SD成为炼丹师不?那么今天就来手把手教大家炼丹,看看同一个角色或某种风格的小模型是如何制作出来的。
目录
1 炼丹介绍
2 环境准备
3 Lora模型训练
**一、**炼丹介绍
什么是炼丹?
早在学习SD地第一篇就普及过炼丹师的概念,炼丹师就是指那些专门研究、开发与应用Stable Diffusion模型的专业人士或爱好者,他们在实践中不断优化模型,使其产生更高质量、更具创意的图像。
炼丹种类
在用SD进行AI绘画时,常用的模型我们都可以自行训练:
1大模型,也就是底模和主模型,文件后缀.safetensors ,文件大小2G~7G左右,耗费时间最长,图片最多,算力最多,也是最有效的一种,没有底模根本无法生成图片。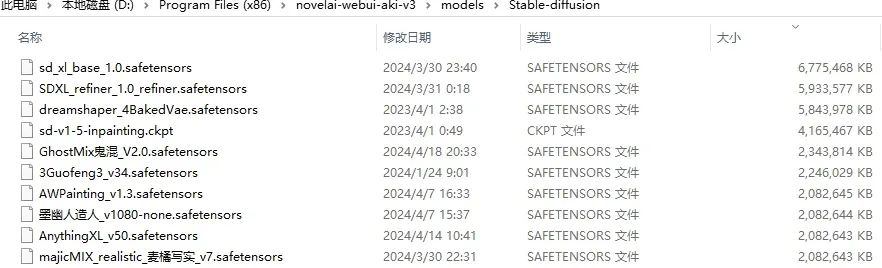
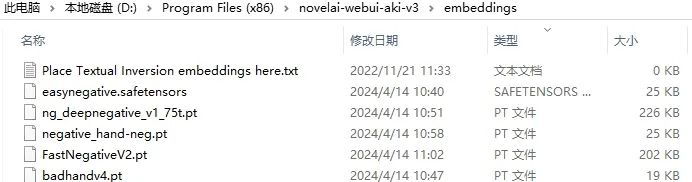
2 embedding模型,文件后缀.pt或.safetensors, 文件大小20KB~300KB,训练简单效果一般,通常用于负面提示词应用,一个embedding相当你输入了一类负面的prompt提示词。
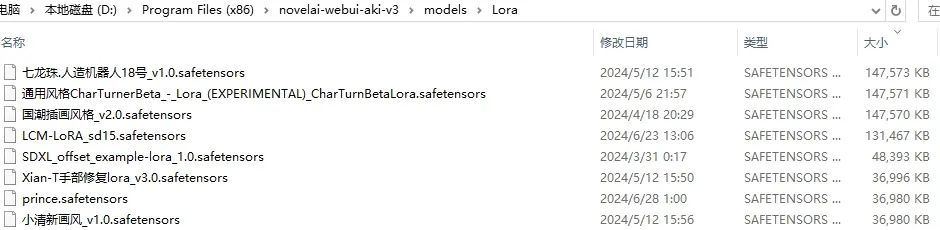
3 Lora模型,就是我们今天要学习的,文件后缀一般是.safetensors,(格式可以互转) 文件大小比embedding大比大模型小,几十MB~几百MB,训练相对容易,现在有了集成安装包就更简单了,硬件要求8G显存以上的卡就可以满足了。
二、环境准备
下载丹炉
目前最简单傻瓜式的就是下载国内B站@秋葉aaaki提供的集成安装包,下载即可用。
提取码:关注公众号发信息"下载丹炉"获取。
安装环境
1 一键更新
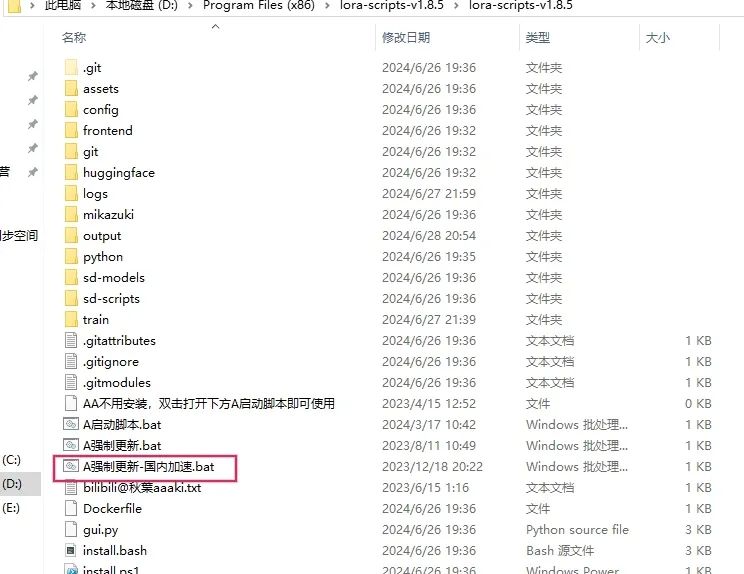
2 安装python
检测win电脑里面的python版本在3.10以上就不用重复安装。
setp1 搜索cmd,打开命令窗口
setp2 输入python 查看版本(需要确定你的python环境变量正确配置,才能用)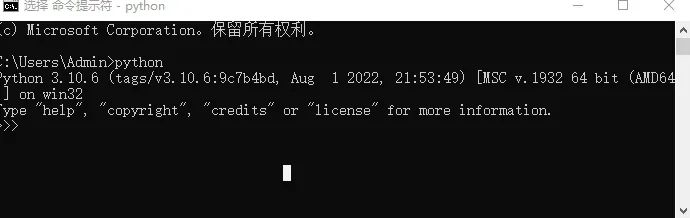
没有安装python的或者版本升级的如下:
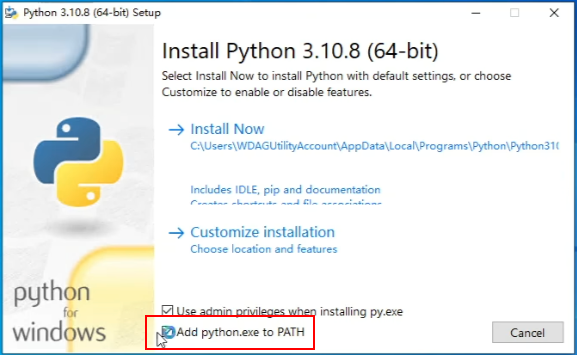
安装python:
记得勾选:add python.exe to PATH 。自动配置环境变量。
一路下一步傻瓜安装完成即可。
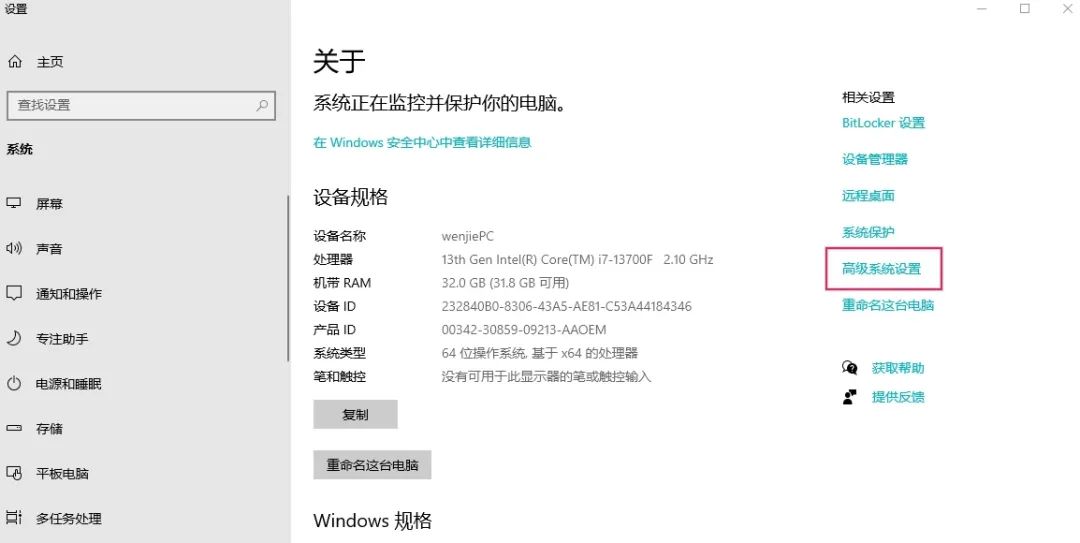
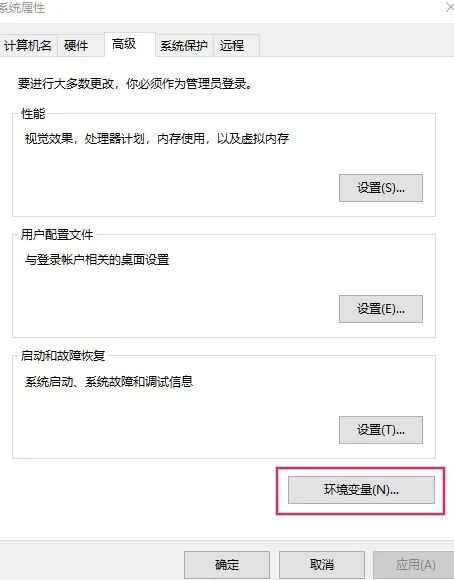
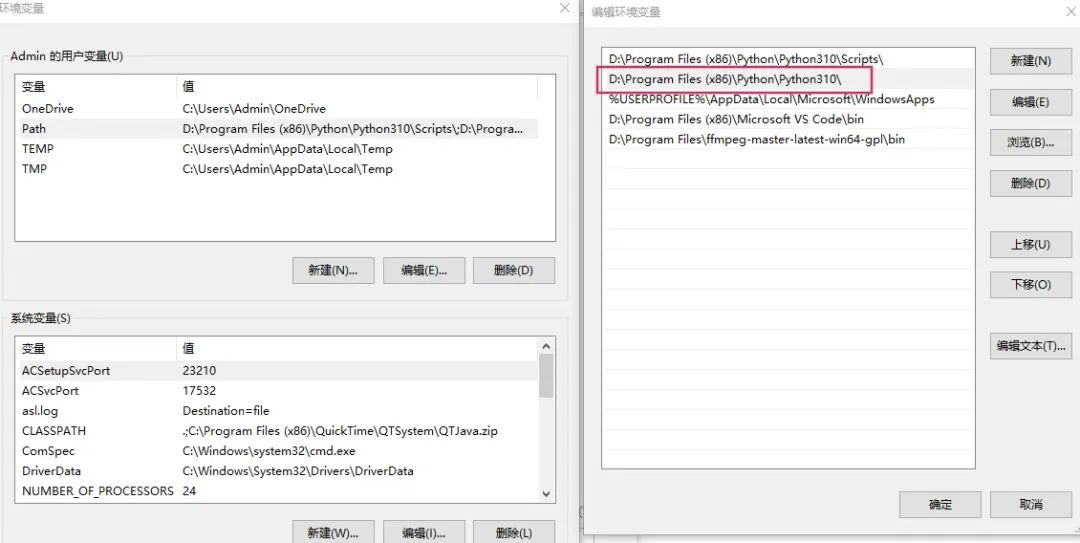
手动配置环境变量:
右键“此电脑”,点击属性,进入设置界面:
三、Lora模型训练
准备图片素材
要求:8G左右的显卡同学,准备512*512的图片素材即可,更牛显卡的不建议超过1024*1024,找同一类风格图片或者同一个人物的不同角度不同姿态的图片。
批量裁剪:如果你从网上找图片,尺寸不一样,可以通过SD WEB UI批量裁剪(当然其他图片处理软件批处理也可以做到,比如PS-动作功能、美图秀秀批处理功能等)
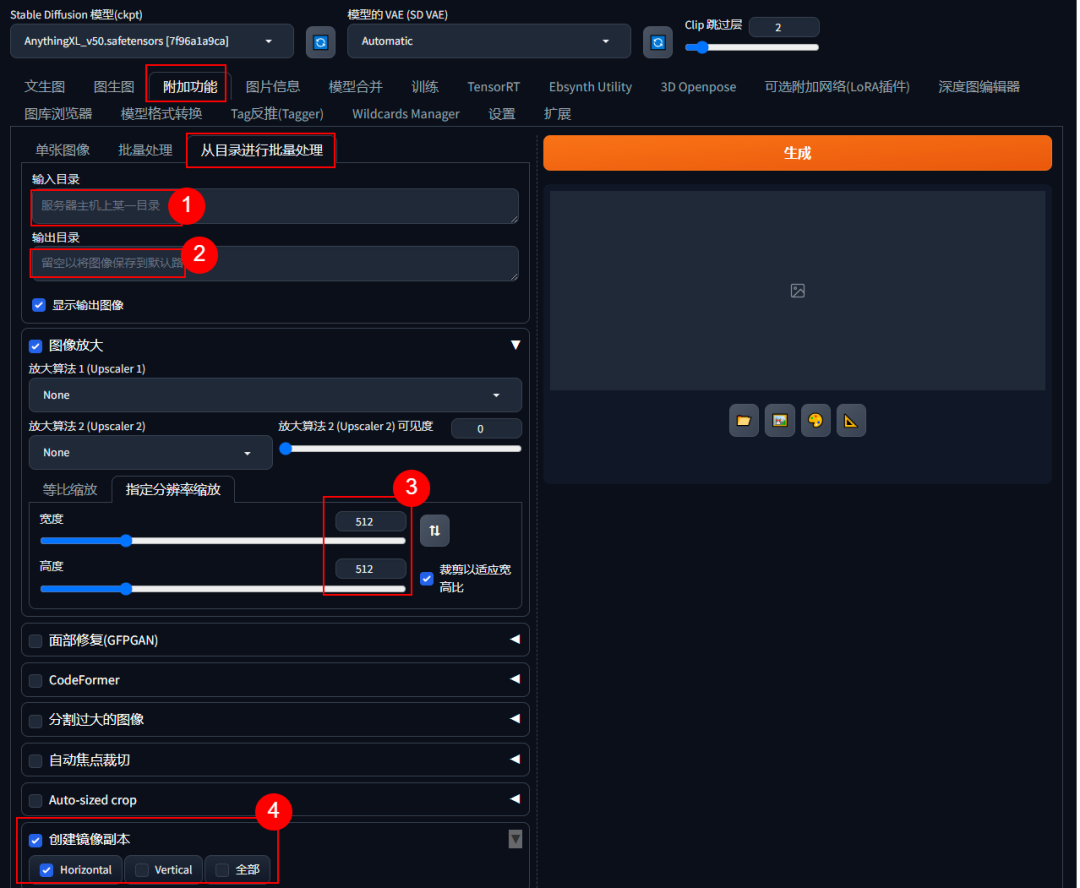
setp1 打开SD WEB UI,附件功能-从目录进行批量处理
setp2 输入图片目录 和 输出目录,路径不要有中文字符。
setp3 图像放大,指定分辨率512*512
setp4 创建镜像,横向or纵向,这样可以多出来一倍的训练图片。
setp5 自动焦点剪切,识别主题的位置剪切。
图片打标
图片剪裁完成后,需要对每个图片进行打标,告诉计算机你这图里都有什么元素。
自动打标:
启动丹炉,双击“A启动脚本.bat”。
输入图片地址,启动即可。
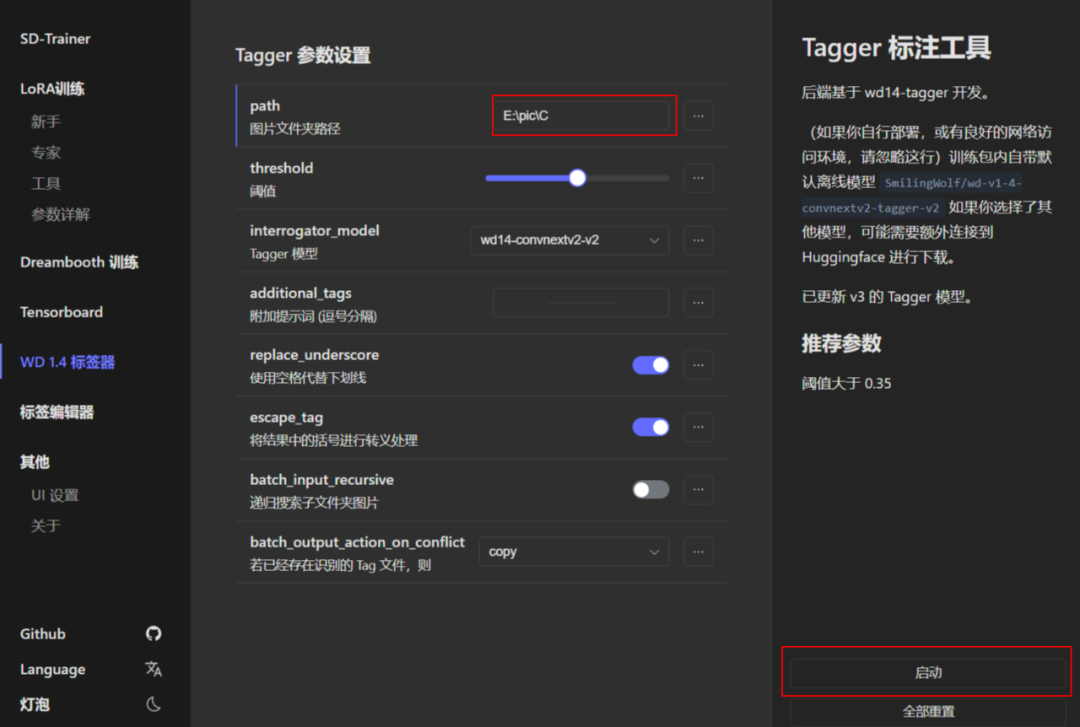
打完后,看看图片文件夹,每个图片都多了一个txt文件:
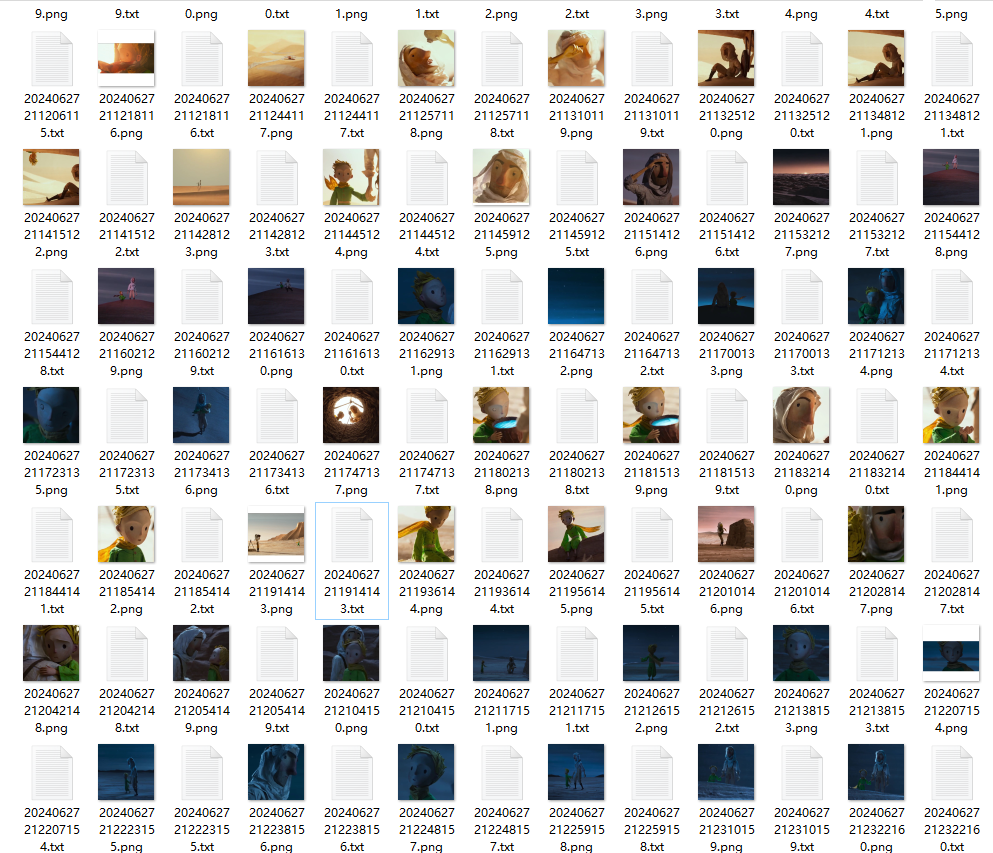
手动修改tag:
最好自己检查下每个txt文件,里面的标签是否准确,对不满意的prompt,自行手动修改即可。
注意:不能有空的txt文件,按文件大小倒序找到这些文件,手动填写prompt即可。
丹炉配置
1、启动丹炉,双击“A启动脚本.bat”
2、选择你的底模,可以从你之前SD web UI里面去找,这里网上很多,不同底模适合不同类型的模型训练。我这里要训练纸片人风格的,用了“AnythingXL_v50.safetensors ”,注意不要有中文路径。然后设置分辨率和丹的名称。
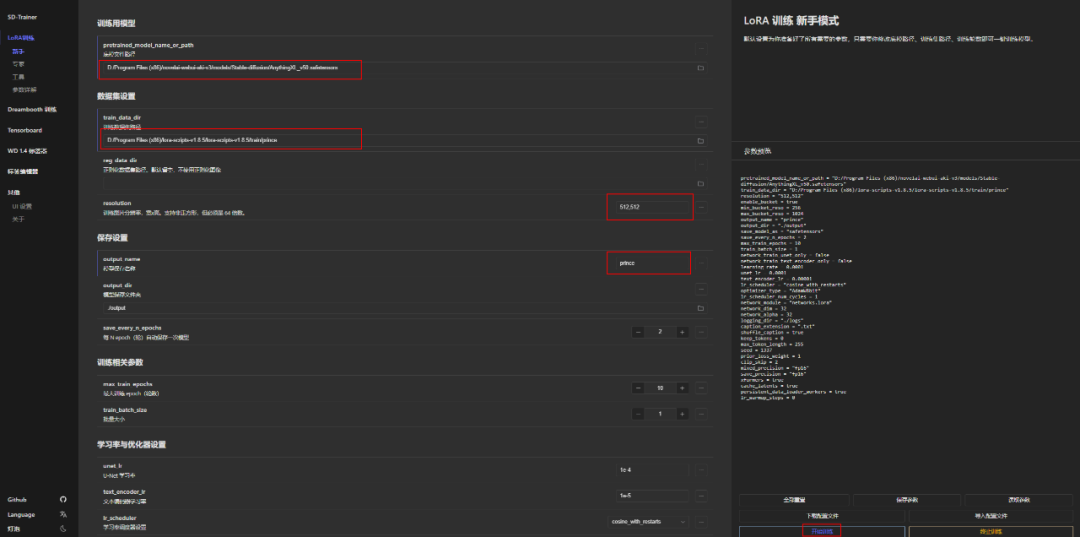
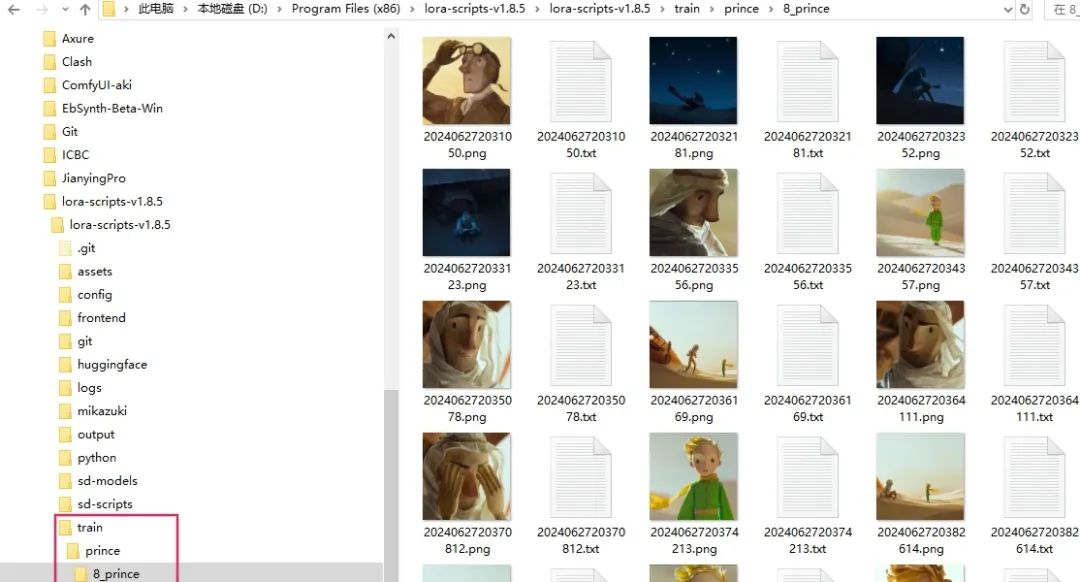
3、选择刚才准备的图片素材,路径需要设置下,放在这个目录里:
…/train/XXX/8_XXX
XXX- 本次训练的项目名称自取英文即可,文件结构按这个来就行。
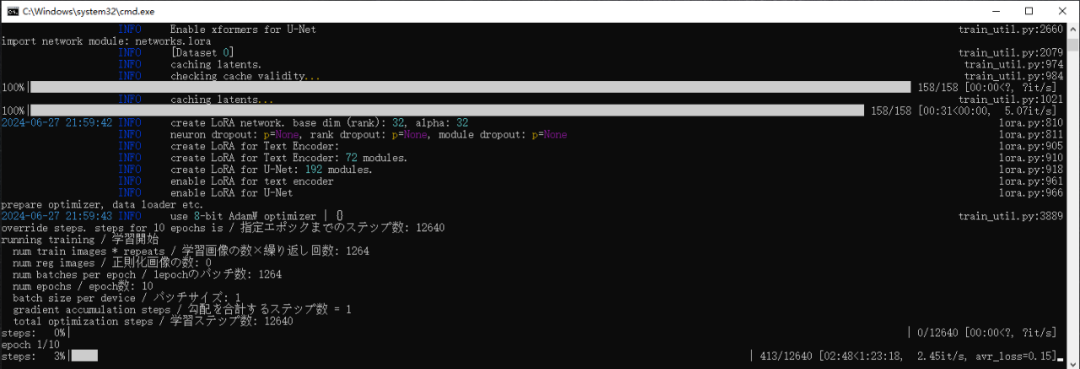
4、一切准备就绪,启动训练,交给时间吧@-@等着炼丹训练完成。祝你好运!
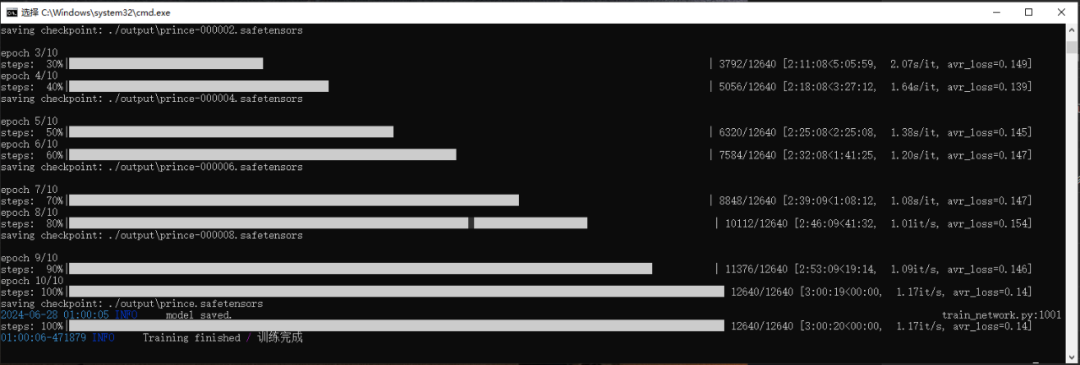
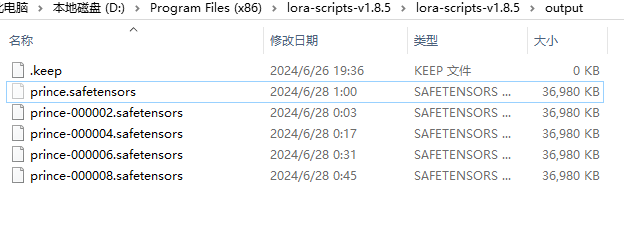
模型测试
把练好的模型,放在SD WEB UI测试你的模型吧!!
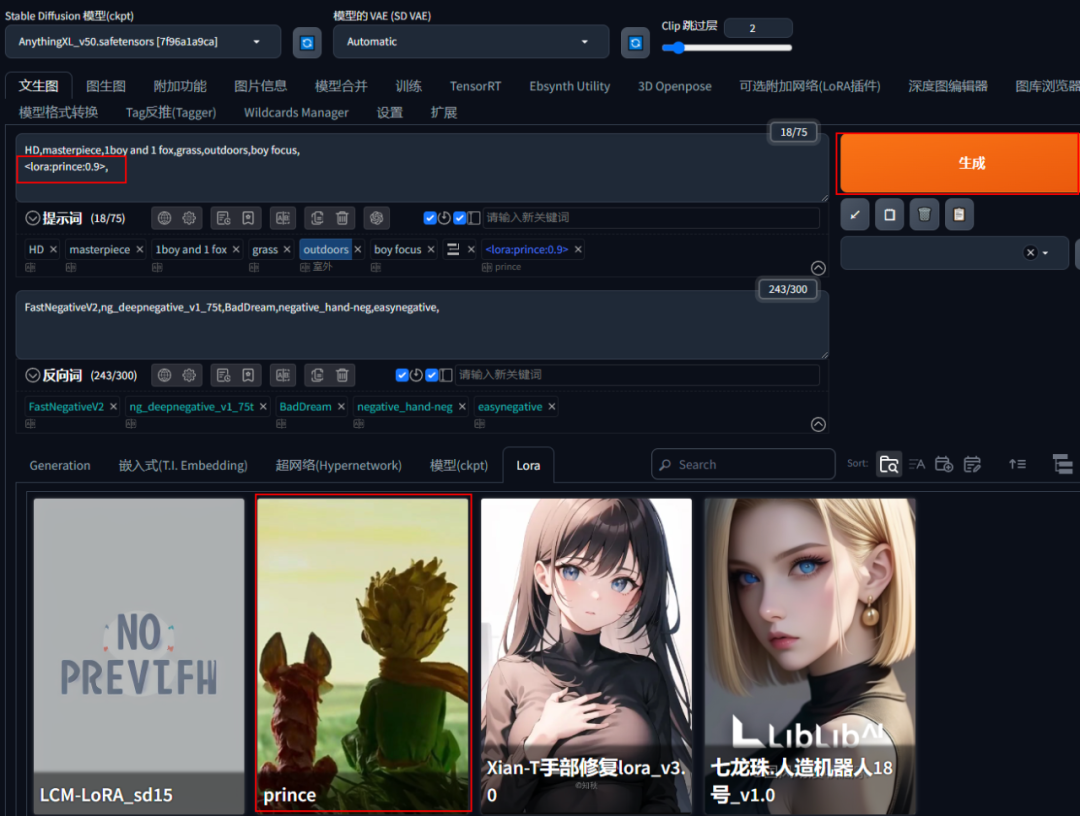

如何训练LorA
对于很多刚学习AI绘画的小伙伴而言,想要提升、学习新技能,往往是自己摸索成长,不成体系的学习效果低效漫长且无助。
如果你苦于没有一份Lora模型训练学习系统完整的学习资料,这份网易的《Stable Diffusion LoRA模型训练指南》电子书,尽管拿去好了。
包知识脉络 + 诸多细节。节省大家在网上搜索资料的时间来学习,也可以分享给身边好友一起学习。
由于内容过多,下面以截图展示目录及部分内容,完整文档领取方式点击下方微信卡片,即可免费获取!


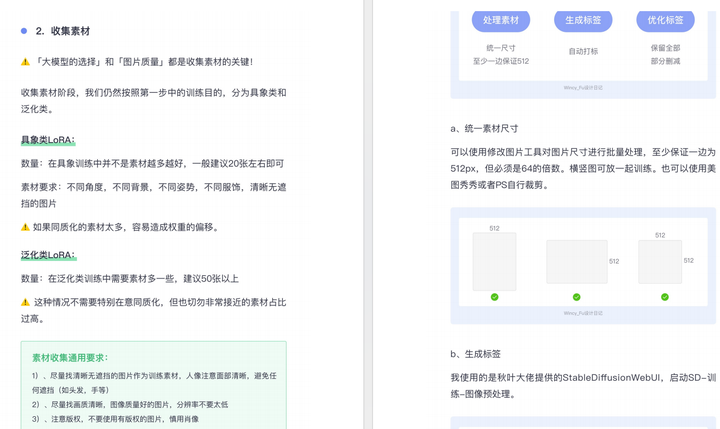
篇幅有限,这里就不一一展示了,有需要的朋友可以点击下方的卡片进行领取!

















 2728
2728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









