






前言

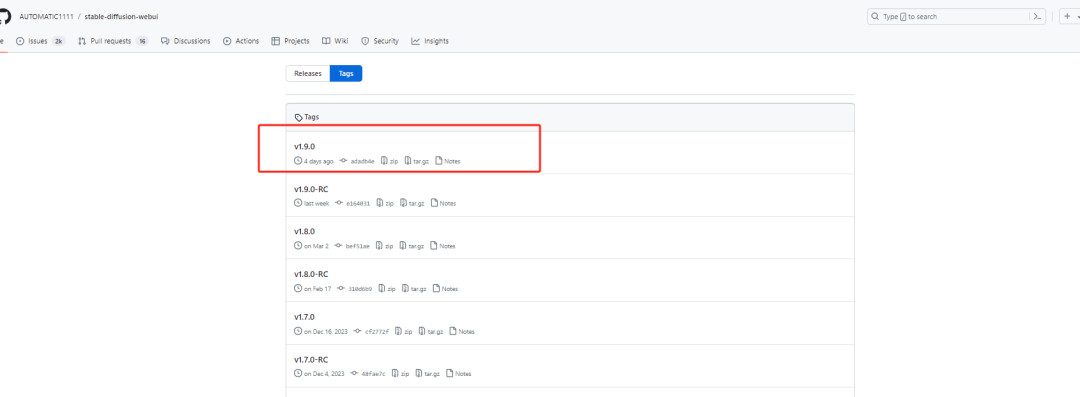
距上次 WebUI v1.8的更新发布刚刚过去一个多月,Stable Diffusion WebUI 这次又又又更新了,老徐关注到Stable Diffusion WebUI作者UTOMATIC1111就在前几天在GitHub上不声不响地将其更新到了最新版—WebUI V1.9.0。
是的,没有错,Stable Diffusion WebUI v1.9.0它来了!
WebUI github地址:
WebUI v1.9.0 Tag github地址:
所有的AI设计工具,模型和插件,都已经整理好了,👇获取~

本次咪咪酱将和大家一起来看下V1.9带来了哪些更新:
根据官方提供的更新描述,老徐大概数了数,本次足足更新了近100多项内容,确切的来说应该是104项****,涉及特性更新、次要更新、扩展和API更新、性能提升、BUG修复、硬件支持及其他内容的更新****。****
下面我们来逐一看看,具体更新了哪些内容:
特性更新(Features):5项

-
根据模型时间步长而不是采样步长进行精炼机切换
xt2img 中旧行为的示例: 此处使用的细化器模型经过最后 200 个时间步的训练。Karras 计划类型,特别是在零信噪比的情况下,极大地改变了在此 50 步采样过程中调用的模型时间步长,这导致精炼器过早切换到默认噪声计划的实际正确设置。在旧配置下,该精炼机的 Karras 采样器的有效正确设置为 0.88。

现在是修复版本: 通过此修复,精炼器的行为与不同计划中的相同设置保持一致,并且不再过早触发。0.8 确实是一个正确的设置。

img2img/inpainting 中旧行为的示例(修复蒙版在头上,添加帽子,去噪强度 0.75): 这个更复杂,差异很微妙。正常计划的有效正确设置是在 0.75 处切换,而对于 Karras 来说,在 0.85 处切换是正确的。因此,使用预期设置 0.8 对于正常计划来说太晚了,而对于 Karras 计划来说则太早了。随着降噪强度变低,问题变得更加严重。 该网格显示修复后的行为。0.8 的切换现在对于两者来说都是正确的。

-
添加一个选项,使其可以选择具有旧式目录视图而不是树状视图;额外网络排序/搜索控件的UI风格变化。

-
添加用于重新排序回调的UI,支持在扩展元数据中指定回调顺序,这个更新可以让用户对回调(callbacks)进行重新排序,还能将指定的插件重新排序
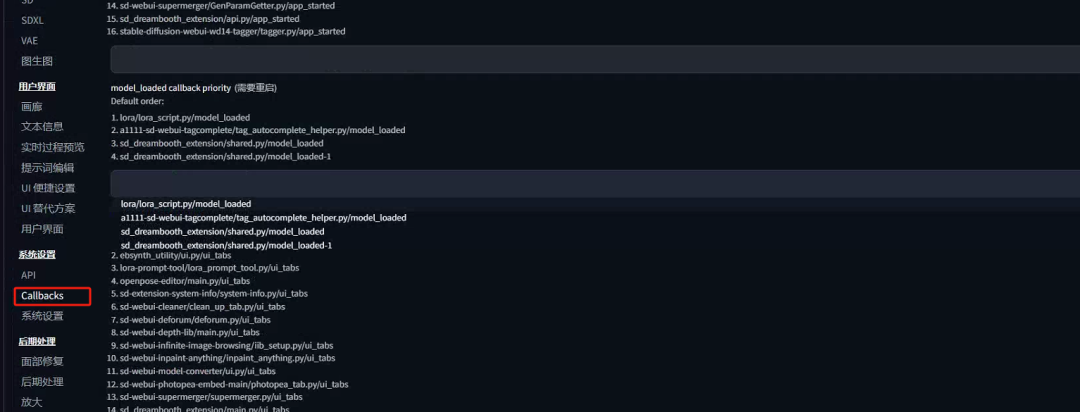
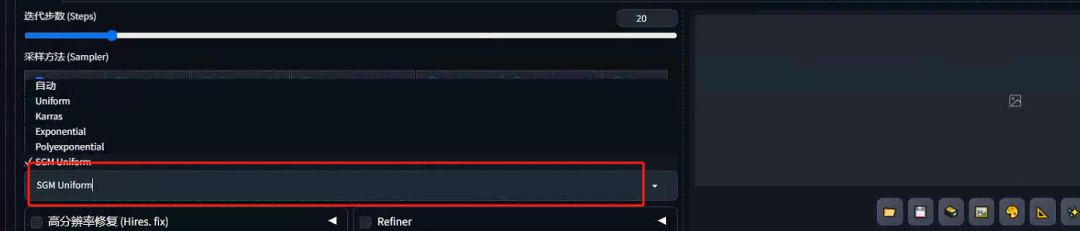
4.SDXL-Lightning模型添加Sgm统一调度器
基于https://huggingface.co/ByteDance/SDXL-Lightning
中的示例代码/工作流程 ,为 SDXL-lightning 系列型号实现了 sgm_uniform 调度程序(还支持 SDXL Lightning LoRA 型号)
为这个自定义调度程序创建了一个新文件,因为我们将来会有越来越多的自定义调度程序。
SDXL 闪电示例(4 步欧拉):

SDXL Lightning LoRA + KXL Delta 示例(4 步欧拉):

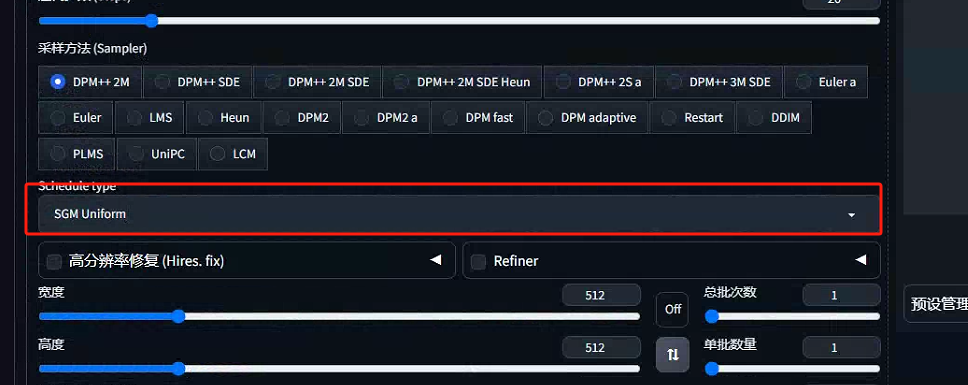
5.在主UI中添加调度器
次要更新(Minor):18项

-
"打开图像目录"按钮现在打开实际目录
-
支持 LyCORIS BOFT 网络推理
-
默认情况下将额外的网卡描述设为纯文本,并可以选择重新启用 HTML格式
-
调整额外网络的句柄大小
-
cmd 命令行参数:–unix-filenames-sanitization和–filenames-max-length
-
以 HTML 表格形式显示额外的网络参数,而不是原始 JSON
-
添加对 LoRA/LoHa/LoKr 的 DoRA(权重分解)支持
-
添加“–no-prompt-history”cmd命令行参数,用来禁用上一次的提示历史记录
-
更新替换预览上的预览
-
仅获取扩展程序的活动 git 分支的更新
-
将放大后处理UI放入折叠面板中
-
支持拖放 URL 来读取infotext信息文本
-
使用 diskcache 库进行缓存
-
允许 PNG-RGBA 用于“附加”选项卡
-
支持嵌入 safetensors 元数据中的封面图像
-
使用 NN 高档时更快的中断
-
Extras upscaler:限制输出图像最大边长的输入字段
-
增加了一个隐藏“附加”选项卡中的后处理选项
扩展和API更新(Extensions and API):8项
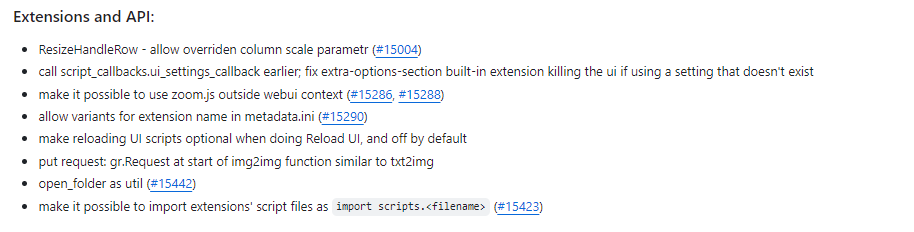
-
ResizeHandleRow-允许覆盖列比例参数
-
修复了调用script_callbacks.ui_settings_callback时如果使用不存在的设置,导致ui崩溃的问题
-
可以在webui上下文之外使用zoom.js
-
允许metadata.ini中使用扩展名的变体
-
使重新加载UI脚本在执行“Reload UI”时是可选的,默认情况下为禁用
-
将请求:gr.Request放在img2img函数的开始,类似于txt2img
-
open_folder作为工具
-
可以将扩展的脚本文件作为导入脚本导入
性能提升(Performance):3项

-
额外网络HTML页面的性能优化
-
额外网络过滤的优化
-
额外网络排序的优化
BUG修复(Bug Fixes):41项
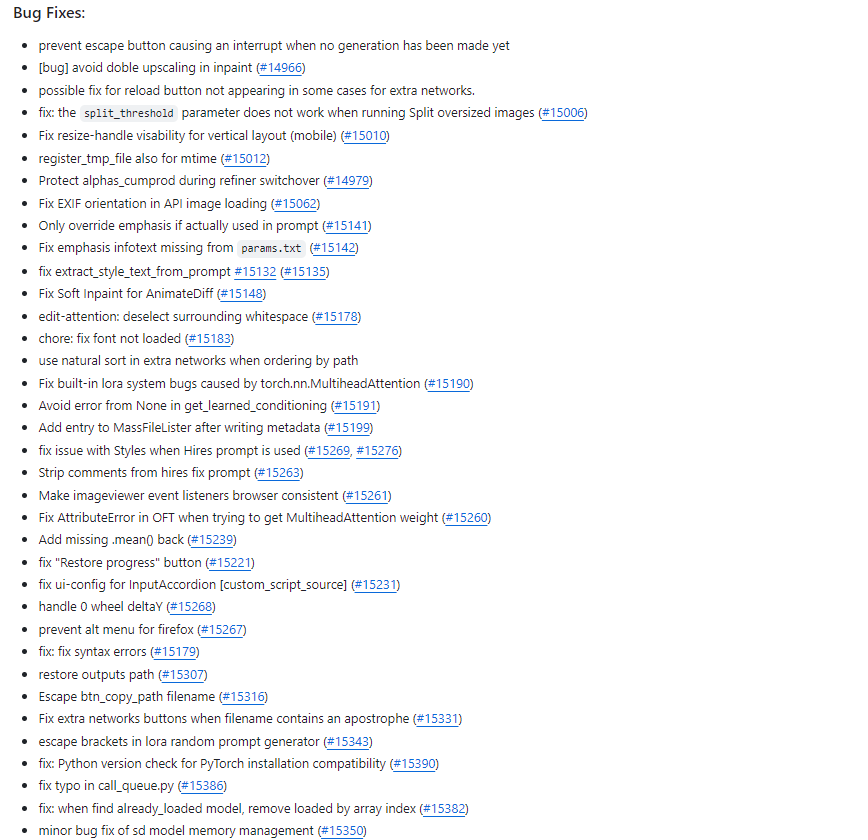

-
阻止在还没有生成时按Escape键导致中断
-
避免在inpainting中发生双重放大
-
可能修复在某些情况下额外网络的重载按钮不出现的问题
-
修复当运行Split oversized images时split_threshold参数不工作的问题
-
修复垂直布局(移动设备)的调整手柄可见性
-
注册_tmp_file也考虑mtime
-
在精炼器切换时保护alphas_cumprod
-
修复API图像加载中的EXIF方向
-
仅在提示中实际使用时覆盖强调
-
修复从params.txt中缺失的强调信息文本
-
修复extract_style_text_from_prompt
-
修复AnimateDiff的Soft Inpaint
-
edit-attention:取消选择周围的空白区域
-
chore:修复未加载的字体
-
在按路径排序时使用自然排序对额外网络进行排序
-
修复内置lora系统由于torch.nn.MultiheadAttention引起的错误
-
避免在get_learned_conditioning中出现None错误
-
在写入元数据后添加MassFileLister的条目
-
修复使用Hires提示时的样式问题
-
从hires fix prompt中删除注释
-
使imageviewer事件监听器在浏览器中保持一致
-
修复OFT中尝试获取MultiheadAttention权重时的AttributeError
-
重新添加.mean()
-
修复"恢复进度"按钮
-
修复InputAccordion [custom_script_source]的ui-config
-
处理0 wheel deltaY
-
防止Firefox中的alt菜单
-
修复:修复语法错误
-
恢复输出路径
-
Escape btn_copy_path filename
-
修复包含撇号的文件名时的额外网络按钮
-
修复lora随机提示生成器中的转义括号
-
修复:修复PyTorch安装兼容性的Python版本检查
-
修复call_queue.py中的typo
-
修复:当找到已加载的模型时,通过数组索引删除已加载的模型
-
修复sd模型内存管理的小bug
-
修复CodeFormer权重
-
修复:从ordered_callbacks_map中移除脚本回调
-
修复有限的文件写入
-
修复额外单图像API在放大失败时的行为
-
错误处理paste_field callables
硬件支持(Hardware):4项
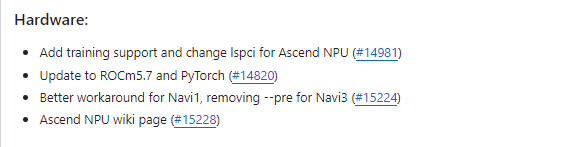
-
为Ascend NPU添加训练支持并更改lspci
-
更新至ROCm5.7和PyTorch
-
Navi1的更好解决方法,删除Navi3的预处理
-
Ascend NPU wiki页面
其他(Other):25项
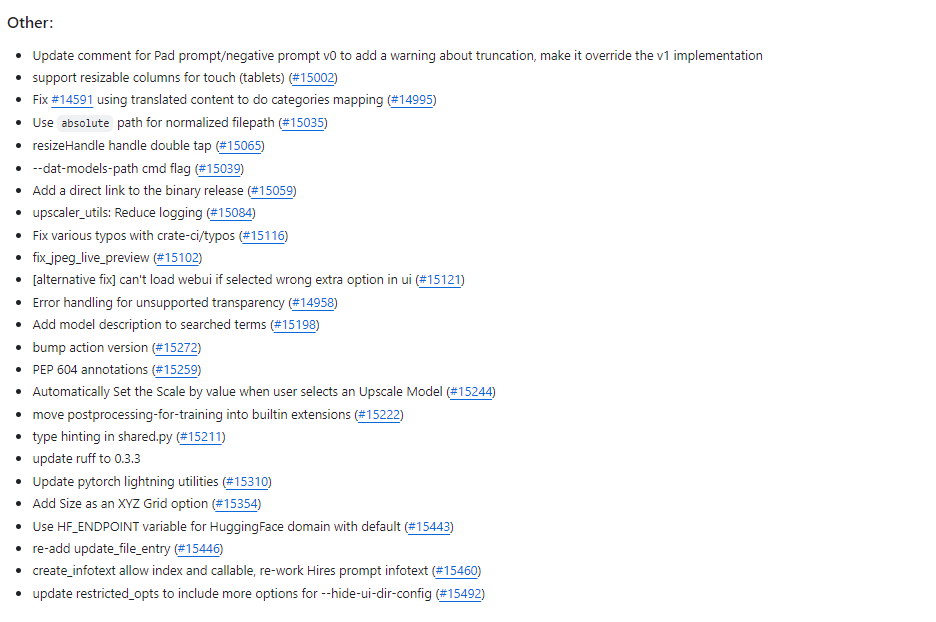
-
更新Pad prompt/negative prompt v0的注释,添加关于截断的警告,并使其覆盖v1实现
-
支持触摸屏上的可调整列大小
-
修复使用翻译内容进行类别映射的问题
-
使用absolute绝对路径进行归一化文件路径
-
调整resizeHandle的双击操作
-
–dat-models-path cmd命令行标志
-
添加直接链接到二进制发布的链接
-
upscaler_utils:减少日志记录
-
使用 crate-ci/typos 修复各种拼写错误
-
修复jpeg_live_preview
-
[替代修复] 如果在 ui 中选择了错误的额外选项,则无法加载 webui
-
修复不支持透明度时的错误处理
-
将模型描述添加到搜索词中
-
bump action版本
-
PEP 604注释
-
当用户选择放大模型时,自动设置比例的值
-
将postprocessing-for-training移动到内置扩展中
-
在shared.py中添加类型提示
-
更新ruff至0.3.3
-
更新PyTorch Lightning工具
-
添加Size作为一个XYZ网格选项
-
使用HF_ENDPOINT变量为HuggingFace域名设置默认值
-
重新添加update_file_entry
-
create_infotext允许索引和callable,重新设计Hires prompt信息文本
-
更新restricted_opts以包含更多用于–hide-ui-dir-config的选项
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!
















 1466
1466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









