






前言

本文正文字数约 3000 字,阅读时间 8 分钟。
我们在以往的文章中已经谈论了许多有关于 AI 生成文本的内容。从本文开始,我将开始向你介绍 AI 生图领域的相关内容。
你或许已经听过甚至使用过诸如 Midjourney、Stable Diffusion 甚至是最近刚发布的 FLUX 这类生图模型。
本文将针对 Stable Diffusion 提供一份初学者入门指南,这也是 Stable Diffusion 系列的第一篇。
无论你是未曾使用过 AI 生图的新手还是已经尝试过各种生图模型了,都将会对 Stable Diffusion 的基本概况有所了解。
所有的AI设计工具,安装包、模型和插件,都已经整理好了,👇获取~
目录
-
• Stable Diffusion 简介
-
• Stable Diffusion 的优势
-
• Stable Diffusion 能做什么
-
• 如何使用 Stable Diffusion
-
• 如何构建提示语
-
• 参数应该如何使用
-
• 图像修复的常见方法
-
• 什么是自定义模型
-
• Negative Prompts
-
• 如何控制图像构造
-
• 总结
本文图像都使用 Mage Space 生成,官网:https://www.mage.space/。
Stable Diffusion 简介
Stable Diffusion 是一种用于生成 AI 图像的潜在扩散模型。它可以生成如同相机拍摄的逼真照片,也可以以专业艺术家的身份来创作艺术作品,同时还能够对图像进行修复等。
Stable Diffusion 基于扩散技术(Diffusion technology),并使用了潜在空间(Latent space)。
扩散技术是通过逐步增加噪声再还原的过程,用来从无序中生成新的图像或数据。而潜在空间是将复杂的高维数据简化为更易处理的低维表示,让模型能更高效地生成结果。
简单来说就是,这两种技术让 Stable Diffusion 大大降低了对计算机的处理需求,所以,Stable Diffusion 也可以在配备了 GPU 的电脑上运行。
Stable Diffusion 的优势
市面上已经有诸如 Midjourney、DALLE 这样的文生图模型了,那为什么还要使用 Stable Diffusion 呢?主要有以下几点优势:
-
• 免费:相对于其他模型动辄一个月几十上百的价格,Stable Diffusion 完全免费
-
• 开源:正是因为 Stable Diffusion 是一个开源项目,所以会有无数的人来一起构建这个社区,有许多的爱好者已经开发出了很多免费的工具和模型
-
• 对计算机的要求不高:Stable Diffusion 运行成本并不高
Stable Diffusion 能做什么
1、文生图
这是 Stable Diffusion 最基本的用法。
与我们使用文本类生成模型类似,只需要提供给模型提示语就可以生成图像了。
比如有这样一句提示语:
gingerbread house, diorama, in focus, white background, toast , crunch cereal
可以得到以下这样的图像:


2、图生图
可以通过一张图片生成一张新的图片。
3、图像编辑
在 Stable Diffusion 中,可以使用 Inpainting 功能来重新生成图像或者将图像缺失的部分修复。
如果你是用过 PS 的话,这个功能有点像 PS 里的智能填充。
4、制作视频
使用 Stable Diffusion 还可以制作视频,主要有两种方式:
-
• 通过文本提示语
-
• 通过另一个视频生成
Deforum 就是一种通过文本提示语制作视频的方式,类似的效果如下。
Deforum 是一款用于制作动画的开源免费软件。它可以利用 Stable Diffusion 的图像生成图像功能来生成一系列图像,并将它们拼接在一起然后来创建视频。官网:https://deforum.github.io/
而通过视频生成视频是一个更高级的话题,可以在掌握了文本生成图像和图像生成图像之后再深入研究。
如何使用 Stable Diffusion
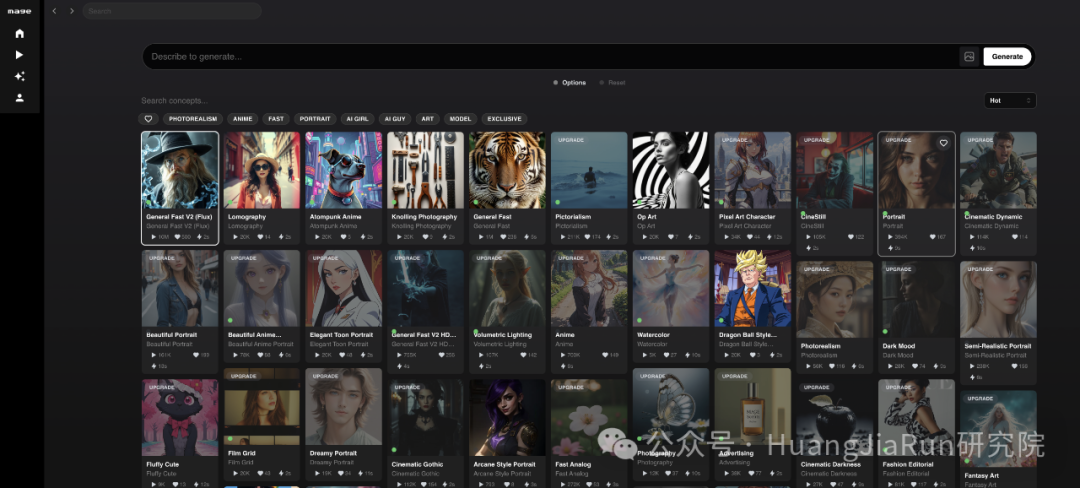
在线生成器
对于初学者可以直接使用以下这些免费的在线生成器:
-
• Mage Space:https://www.mage.space/
-
• PlayGround:https://playground.com/
-
• Dream Studio:https://beta.dreamstudio.ai/generate
-
• Dezgo:https://dezgo.com/text2image/sdxl
当然,这里只是给出了一部分在线生成器,更多的在线生成器,可以在网上搜索找到。
高级 GUI
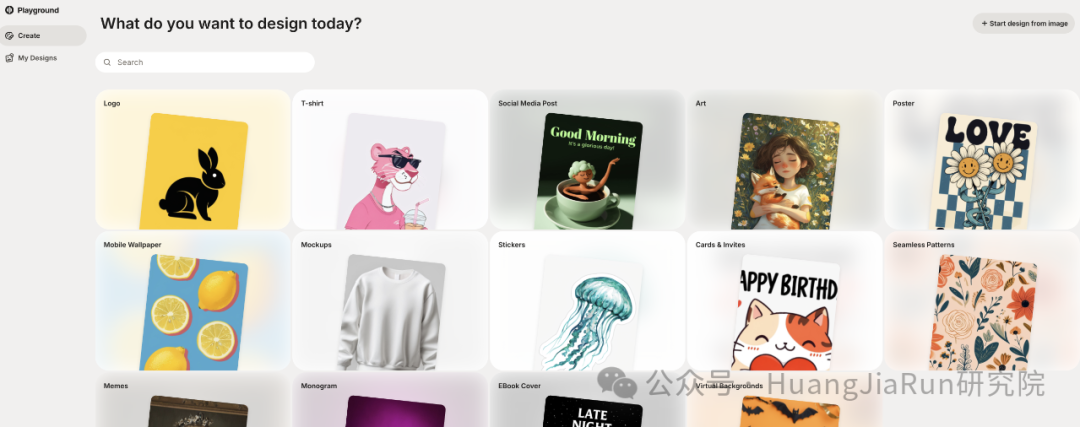
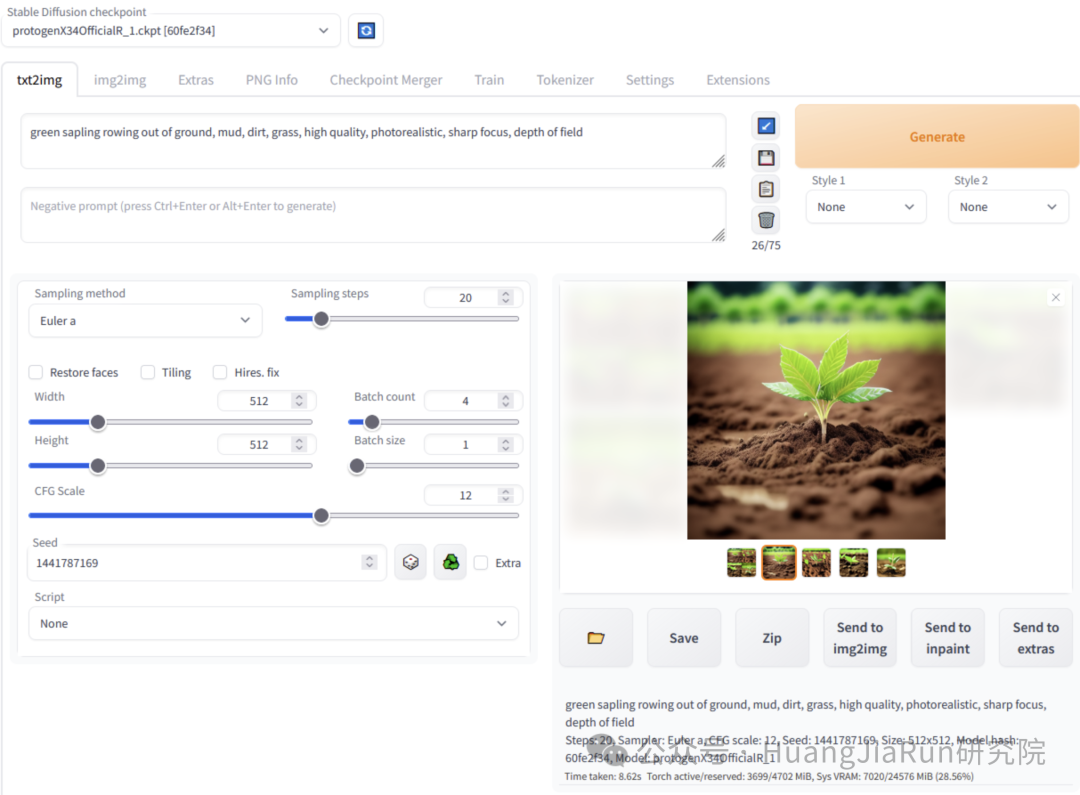
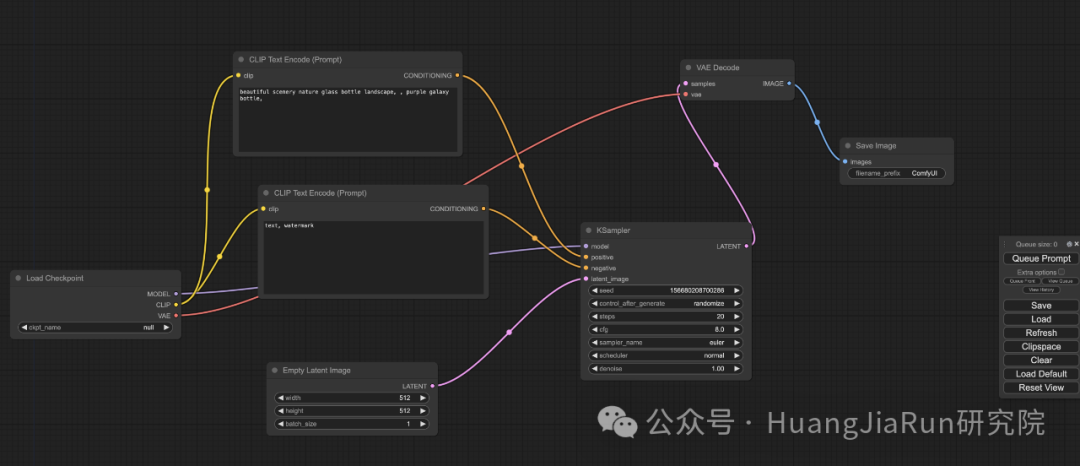
如果不满足于免费生成器所带来的功能,那么可以尝试更高级的 GUI,比如 AUTOMATIC1111、ComfyUI。这种工具提供了更丰富的功能:
-
• 高级提示语技巧
-
• 使用 Inpainting 来修复图像
-
• 图生图
-
• 通过指令来对图像进行编辑
-
• 可视化工作流
如何构建提示语
就像我们使用 Kimi、ChatGPT 这类文本生成模型一样,在生成图像的时候,要构建一个好的提示语依然需要学习很多的内容。
但是万变不离其宗,最基本的原则依然是尽可能详细地描述主题,并且确保包含强有力的关键词来定义风格。
使用提示语生成器是学习构建提示语的很好的方式。它能辅助我们来一步步地构建提示语,以及教会我们使用重要的关键词。
对于初学者来说,学习一组强大的关键词就像我们学习一门新语言的词汇一样重要,熟练的掌握了这些关键词之后才能够非常快速地创造出我们想要的图像。
生成高质量的图像的快捷方式就是复用已有的提示语,当我们熟练掌握了这些关键词汇之后,就可以根据自己的需求打造出自己的提示语库。
网上有非常多的关键词库资源,可以在搜索引擎搜索或者在小红书里搜索就能找到。
对于提示语生成器,我推荐使用这个开源提示语生成器:https://www.aipromptgenerator.art/
我在这里列举两条构建良好提示语的原则。
详细且具体
一定要尽可能详细的描述需求。
比如,要生成一个街上的一只猫的图像,如果只是简单写一句:a cat on street,那么得到的图像可能并不会是我们想要的。

所以要写的更加详细,比如
A tabby orange cat with green eyes, six months old, looking very happy, is shaking hands with a six-year-old little boy, and there is sunshine shining on both of them.
使用强有力关键词
有些关键词由于被大众所熟悉,所以相对于那些大家不那么熟悉的关键词来说,会更有效果,比如:
-
• 名人的姓名
-
• 艺术家姓名(比如宫崎骏,我在 Midjourney 生图的时候就特别喜欢使用宫崎骏或者新海诚风格)
-
• 艺术媒介(这里主要是指 Illustration、Photograph 这类软件)
参数应该如何使用
大多数在线生成器都允许调整有限的参数,这些参数可以在生成图像的时候为模型提供更多限制条件和指导,让模型能够生成更好的结果。
以下是部分重要的参数。
-
• 图像尺寸:即生成的图像大小
-
• 采样步数:可以提高图像的清晰度
-
• CFG 比例:一般值为 7,如果希望模型对提示语的遵循程度更高,可以适当增加
-
• 种子值:使用 -1 会生成随机图像,如果想要生成相同的图像,可以指定一个特定的值
一般来说,在测试提示语的时候,一次可以生成 2-4 张图像,这样才能更好地测试出提示语的有效性。
图像修复的常见方法
我们在网上看到的那些 AI 生成图,理论上来说都会经过多轮的提示语调校以及一些后期处理。
面部修复
Stable Diffusion 其实并不擅长生成面部,很多时候生成的面部都会有各种各样的瑕疵。
所以,通常会使用专门用于修复面部的图像 AI 模型,比如 CodeFormer,AUTOMATIC1111 的 GUI 就内置了对它的支持。
使用 Inpainting 来修复小瑕疵
想要在第一次尝试中就得到理想的图像是很难的。
更好的方法是,先生成一张构图不错的图像,然后通过 Inpainting 来修复瑕疵和缺陷。
什么是自定义模型
由 Stability AI 官方发布的模型称为基础模型,比如 Stable Diffusion 1.4、1.5、2.0 和 2.1。
所有的模型都可以在 HuggingFace 上找到:https://huggingface.co/。
自定义模型是基于这些基础模型训练而来的。目前,大多数自定义模型都是从 v1.4 或 v1.5 训练而来,并使用额外的数据来生成特定风格或物体的图像。
我该使用哪个模型?
Stable Diffusion 主要有三个版本:v1、v2、v3 和 Stable Diffusion XL(SDXL)。
-
• v1 模型包括 1.4 和 1.5
-
• v2 模型包括 2.0 和 2.1
-
• v3 模型包括 large, large-turbo 和 medium
-
• SDXL 1.0
你可能会认为应该从较新的 v2 模型开始,但实际上,人们仍在探索如何更好地使用 v2 模型,且 v2 生成的图像不一定比 v1 更好。
SDXL 系列模型已经发布了多个版本:SDXL beta、SDXL 0.9,以及最新的 SDXL 1.0。
对于 Stable Diffusion 初学者来说,推荐使用 v1.5 和 SDXL 1.0 模型。
负面提示语(Negative Prompt)
可以把负面提示语看作是告诉模型 不要做什么,而不是直接命令它 该做什么。这就像为模型设置一个看不见的边界或指南,帮助引导整个创作过程。
如何控制图像构造
图生图
可以要求 Stable Diffusion 在生图的时候大致遵循输入图像的构图,比如可以使用一只鹰的图像作为输入,让模型生成一条龙,输出的图像的构图会遵循输入图像的构图。
ControlNet
ControlNet 同样利用输入图像来指导输出,但它可以提取特定信息,例如人体姿势。比如,可以使用 ControlNet 复制输入图像中的人体姿势。此外,ControlNet 还可以提取其他信息,如轮廓。
区域提示语(Regional prompting)
通过一个叫做 Regional Prompter 的扩展,可以为图像的特定部分指定提示语。这种技术非常适合在图像的特定位置绘制物体。比如,可以在图像的左下角放置一只狼,在右下角放置骷髅。
Depth-to-image
Depth-to-image 是通过输入图像控制构图的另一种方式。它可以检测输入图像的前景和背景,使输出图像保持相同的前景和背景结构。
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!

















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









