







-
语法:jdbc:mysql://ip地址(域名):端口号/数据库名称
-
例子:jdbc:mysql://localhost:3306/db3
-
细节:如果连接的是本机mysql服务器,并且mysql服务默认端口是3306,则url可以简写为:jdbc:mysql:///数据库名称
-
user:用户名
-
password:密码
-
Connection:数据库连接对象
-
功能:
-
获取执行sql 的对象
-
Statement createStatement()
-
PreparedStatement prepareStatement(String sql)
- 管理事务:
-
开启事务:setAutoCommit(boolean autoCommit) :调用该方法设置参数为false,即开启事务
-
提交事务:commit()
-
回滚事务:rollback()
-
Statement:执行sql的对象
-
执行sql
-
boolean execute(String sql) :可以执行任意的sql 了解
-
int executeUpdate(String sql) :执行DML(insert、update、delete)语句、DDL(create,alter、drop)语句
- 返回值:影响的行数,可以通过这个影响的行数判断DML语句是否执行成功 返回值>0的则执行成功,反之,则失败。
-
ResultSet executeQuery(String sql) :执行DQL(select)语句
-
练习:
-
account表 添加一条记录
-
account表 修改记录
-
account表 删除一条记录
代码:
Statement stmt = null;
Connection conn = null;
try {
//1. 注册驱动
Class.forName(“com.mysql.jdbc.Driver”);
//2. 定义sql
String sql = “insert into account values(null,‘王五’,3000)”;
//3.获取Connection对象
conn = DriverManager.getConnection(“jdbc:mysql:///db3”, “root”, “root”);
//4.获取执行sql的对象 Statement
stmt = conn.createStatement();
//5.执行sql
int count = stmt.executeUpdate(sql);//影响的行数
//6.处理结果
System.out.println(count);
if(count > 0){
System.out.println(“添加成功!”);
}else{
System.out.println(“添加失败!”);
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}finally {
//stmt.close();
//7. 释放资源
//避免空指针异常
if(stmt != null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(conn != null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
- ResultSet:结果集对象,封装查询结果
-
boolean next(): 游标向下移动一行,判断当前行是否是最后一行末尾(是否有数据),如果是,则返回false,如果不是则返回true
-
getXxx(参数):获取数据
-
Xxx:代表数据类型 如: int getInt() , String getString()
-
参数:
-
int:代表列的编号,从1开始 如: getString(1)
-
String:代表列名称。 如: getDouble(“balance”)
-
注意:
-
使用步骤:
-
游标向下移动一行
-
判断是否有数据
-
获取数据
//循环判断游标是否是最后一行末尾。
while(rs.next()){
//获取数据
//6.2 获取数据
int id = rs.getInt(1);
String name = rs.getString(“name”);
double balance = rs.getDouble(3);
System.out.println(id + “—” + name + “—” + balance);
}
-
练习:
-
定义一个方法,查询emp表的数据将其封装为对象,然后装载集合,返回。
-
定义Emp类
-
定义方法 public List findAll(){}
-
实现方法 select * from emp;
-
PreparedStatement:执行sql的对象
-
SQL注入问题:在拼接sql时,有一些sql的特殊关键字参与字符串的拼接。会造成安全性问题
-
输入用户随便,输入密码:a’ or ‘a’ = 'a
-
sql:select * from user where username = ‘fhdsjkf’ and password = ‘a’ or ‘a’ = ‘a’
-
解决sql注入问题:使用PreparedStatement对象来解决
-
预编译的SQL:参数使用?作为占位符
-
步骤:
-
导入驱动jar包 mysql-connector-java-5.1.37-bin.jar
-
注册驱动
-
获取数据库连接对象 Connection
-
定义sql
- 注意:sql的参数使用?作为占位符。 如:select * from user where username = ? and password = ?;
-
获取执行sql语句的对象 PreparedStatement Connection.prepareStatement(String sql)
-
给?赋值:
-
方法: setXxx(参数1,参数2)
-
参数1:?的位置编号 从1 开始
-
参数2:?的值
-
执行sql,接受返回结果,不需要传递sql语句
-
处理结果
-
释放资源
-
注意:后期都会使用PreparedStatement来完成增删改查的所有操作
-
可以防止SQL注入
-
效率更高
抽取JDBC工具类 : JDBCUtils
-
目的:简化书写
-
分析:
-
注册驱动也抽取
-
抽取一个方法获取连接对象
-
需求:不想传递参数(麻烦),还得保证工具类的通用性。
-
解决:配置文件
jdbc.properties
url=
user=
password=
- 抽取一个方法释放资源
- 代码实现:
public class JDBCUtils {
private static String url;
private static String user;
private static String password;
private static String driver;
/**
- 文件的读取,只需要读取一次即可拿到这些值。使用静态代码块
*/
static{
//读取资源文件,获取值。
try {
//1. 创建Properties集合类。
Properties pro = new Properties();
//获取src路径下的文件的方式—>ClassLoader 类加载器
ClassLoader classLoader = JDBCUtils.class.getClassLoader();
URL res = classLoader.getResource(“jdbc.properties”);
String path = res.getPath();
System.out.println(path);///D:/IdeaProjects/itcast/out/production/day04_jdbc/jdbc.properties
//2. 加载文件
// pro.load(new FileReader(“D:\IdeaProjects\itcast\day04_jdbc\src\jdbc.properties”));
pro.load(new FileReader(path));
//3. 获取数据,赋值
url = pro.getProperty(“url”);
user = pro.getProperty(“user”);
password = pro.getProperty(“password”);
driver = pro.getProperty(“driver”);
//4. 注册驱动
Class.forName(driver);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
/**
-
获取连接
-
@return 连接对象
*/
public static Connection getConnection() throws SQLException {
return DriverManager.getConnection(url, user, password);
}
/**
-
释放资源
-
@param stmt
-
@param conn
*/
public static void close(Statement stmt,Connection conn){
if( stmt != null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if( conn != null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
-
释放资源
-
@param stmt
-
@param conn
*/
public static void close(ResultSet rs,Statement stmt, Connection conn){
if( rs != null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if( stmt != null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if( conn != null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
-
练习:
-
需求:
-
通过键盘录入用户名和密码
-
判断用户是否登录成功
-
select * from user where username = “” and password = “”;
-
如果这个sql有查询结果,则成功,反之,则失败
-
步骤:
- 创建数据库表 user
CREATE TABLE USER(
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(32),
PASSWORD VARCHAR(32)
);
INSERT INTO USER VALUES(NULL,‘zhangsan’,‘123’);
INSERT INTO USER VALUES(NULL,‘lisi’,‘234’);
- 代码实现:
public class JDBCDemo9 {
public static void main(String[] args) {
//1.键盘录入,接受用户名和密码
Scanner sc = new Scanner(System.in);
System.out.println(“请输入用户名:”);
String username = sc.nextLine();
System.out.println(“请输入密码:”);
String password = sc.nextLine();
//2.调用方法
boolean flag = new JDBCDemo9().login(username, password);
//3.判断结果,输出不同语句
if(flag){
//登录成功
System.out.println(“登录成功!”);
}else{
System.out.println(“用户名或密码错误!”);
}
}
/**
- 登录方法
*/
public boolean login(String username ,String password){
if(username == null || password == null){
return false;
}
//连接数据库判断是否登录成功
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
//1.获取连接
try {
conn = JDBCUtils.getConnection();
//2.定义sql
String sql = “select * from user where username = '”+username+“’ and password = '”+password+"’ ";
//3.获取执行sql的对象
stmt = conn.createStatement();
//4.执行查询
rs = stmt.executeQuery(sql);
//5.判断
/* if(rs.next()){//如果有下一行,则返回true
return true;
}else{
return false;
}*/
return rs.next();//如果有下一行,则返回true
} catch (SQLException e) {
e.printStackTrace();
}finally {
JDBCUtils.close(rs,stmt,conn);
}
return false;
}
}
JDBC控制事务:
-
事务:一个包含多个步骤的业务操作。如果这个业务操作被事务管理,则这多个步骤要么同时成功,要么同时失败。
-
操作:
-
开启事务
-
提交事务
-
回滚事务
-
使用Connection对象来管理事务
-
开启事务:setAutoCommit(boolean autoCommit) :调用该方法设置参数为false,即开启事务
-
在执行sql之前开启事务
-
提交事务:commit()
-
当所有sql都执行完提交事务
-
回滚事务:rollback()
-
在catch中回滚事务
- 代码:
public class JDBCDemo10 {
public static void main(String[] args) {
Connection conn = null;
PreparedStatement pstmt1 = null;
PreparedStatement pstmt2 = null;
try {
//1.获取连接
conn = JDBCUtils.getConnection();
//开启事务
conn.setAutoCommit(false);
//2.定义sql
//2.1 张三 - 500
String sql1 = “update account set balance = balance - ? where id = ?”;
//2.2 李四 + 500
String sql2 = “update account set balance = balance + ? where id = ?”;
//3.获取执行sql对象
pstmt1 = conn.prepareStatement(sql1);
pstmt2 = conn.prepareStatement(sql2);
//4. 设置参数
pstmt1.setDouble(1,500);
pstmt1.setInt(2,1);
pstmt2.setDouble(1,500);
pstmt2.setInt(2,2);
//5.执行sql
pstmt1.executeUpdate();
// 手动制造异常
int i = 3/0;
pstmt2.executeUpdate();
//提交事务
conn.commit();
} catch (Exception e) {
//事务回滚
try {
if(conn != null) {
conn.rollback();
}
} catch (SQLException e1) {
e1.printStackTrace();
}
e.printStackTrace();
}finally {
JDBCUtils.close(pstmt1,conn);
JDBCUtils.close(pstmt2,null);
}
}
}
- 概念:其实就是一个容器(集合),存放数据库连接的容器。
当系统初始化好后,容器被创建,容器中会申请一些连接对象,当用户来访问数据库时,从容器中获取连接对象,用户访问完之后,会将连接对象归还给容器。
-
好处:
-
节约资源
-
用户访问高效
-
实现:
-
标准接口:DataSource javax.sql包下的
-
方法:
-
获取连接:getConnection()
-
归还连接:Connection.close()。如果连接对象Connection是从连接池中获取的,那么调用Connection.close()方法,则不会再关闭连接了。而是归还连接
-
一般我们不去实现它,有数据库厂商来实现
-
C3P0:数据库连接池技术
-
Druid:数据库连接池实现技术,由阿里巴巴提供的
-
C3P0:数据库连接池技术
- 步骤:
- 导入jar包 (两个) c3p0-0.9.5.2.jar mchange-commons-java-0.2.12.jar ,
- 不要忘记导入数据库驱动jar包
- 定义配置文件:
-
名称: c3p0.properties 或者 c3p0-config.xml
-
路径:直接将文件放在src目录下即可。
-
创建核心对象 数据库连接池对象 ComboPooledDataSource
-
获取连接: getConnection
- 代码:
//1.创建数据库连接池对象
DataSource ds = new ComboPooledDataSource();
//2. 获取连接对象
Connection conn = ds.getConnection();
-
Druid:数据库连接池实现技术,由阿里巴巴提供的
-
步骤:
-
导入jar包 druid-1.0.9.jar
-
定义配置文件:
-
是properties形式的
-
可以叫任意名称,可以放在任意目录下
-
加载配置文件。Properties
-
获取数据库连接池对象:通过工厂来来获取 DruidDataSourceFactory
-
获取连接:getConnection
- 代码:
//3.加载配置文件
Properties pro = new Properties();
InputStream is = DruidDemo.class.getClassLoader().getResourceAsStream(“druid.properties”);
pro.load(is);
//4.获取连接池对象
DataSource ds = DruidDataSourceFactory.createDataSource(pro);
//5.获取连接
Connection conn = ds.getConnection();
-
定义工具类
-
定义一个类 JDBCUtils
-
提供静态代码块加载配置文件,初始化连接池对象
-
提供方法
-
获取连接方法:通过数据库连接池获取连接
-
释放资源
-
获取连接池的方法
- 代码:
public class JDBCUtils {
//1.定义成员变量 DataSource
private static DataSource ds ;
static{
try {
//1.加载配置文件
Properties pro = new Properties();
pro.load(JDBCUtils.class.getClassLoader().getResourceAsStream(“druid.properties”));
//2.获取DataSource
ds = DruidDataSourceFactory.createDataSource(pro);
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
- 获取连接
*/
public static Connection getConnection() throws SQLException {
return ds.getConnection();
}
/**
- 释放资源
*/
public static void close(Statement stmt,Connection conn){
/* if(stmt != null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(conn != null){
try {
conn.close();//归还连接
} catch (SQLException e) {
e.printStackTrace();
}
}*/
close(null,stmt,conn);
}
public static void close(ResultSet rs , Statement stmt, Connection conn){
if(rs != null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(stmt != null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(conn != null){
try {
conn.close();//归还连接
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
- 获取连接池方法
*/
public static DataSource getDataSource(){
return ds;
}
}
JDBC template
-
Spring框架对JDBC的简单封装。提供了一个JDBCTemplate对象简化JDBC的开发
-
步骤:
-
导入jar包
-
创建JdbcTemplate对象。依赖于数据源DataSource
- JdbcTemplate template = new JdbcTemplate(ds);
- 调用JdbcTemplate的方法来完成CRUD的操作
-
update():执行DML语句。增、删、改语句
-
queryForMap():查询结果将结果集封装为map集合,将列名作为key,将值作为value 将这条记录封装为一个map集合
-
注意:这个方法查询的结果集长度只能是1
-
queryForList():查询结果将结果集封装为list集合
-
注意:将每一条记录封装为一个Map集合,再将Map集合装载到List集合中
-
query():查询结果,将结果封装为JavaBean对象
-
query的参数:RowMapper
-
一般我们使用BeanPropertyRowMapper实现类。可以完成数据到JavaBean的自动封装
-
new BeanPropertyRowMapper<类型>(类型.class)
-
queryForObject:查询结果,将结果封装为对象
-
一般用于聚合函数的查询
- 练习:
- 需求:
-
修改1号数据的 salary 为 10000
-
添加一条记录
-
删除刚才添加的记录
-
查询id为1的记录,将其封装为Map集合
-
查询所有记录,将其封装为List
-
查询所有记录,将其封装为Emp对象的List集合
-
查询总记录数
- 代码:
import cn.itcast.domain.Emp;
import cn.itcast.utils.JDBCUtils;
import org.junit.Test;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowMapper;
import java.sql.Date;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.List;
import java.util.Map;
public class JdbcTemplateDemo2 {
//Junit单元测试,可以让方法独立执行
//1. 获取JDBCTemplate对象
private JdbcTemplate template = new JdbcTemplate(JDBCUtils.getDataSource());
/**
-
- 修改1号数据的 salary 为 10000
*/
@Test
public void test1(){
//2. 定义sql
String sql = “update emp set salary = 10000 where id = 1001”;
//3. 执行sql
int count = template.update(sql);
System.out.println(count);
}
/**
-
- 添加一条记录
*/
@Test
public void test2(){
String sql = “insert into emp(id,ename,dept_id) values(?,?,?)”;
int count = template.update(sql, 1015, “郭靖”, 10);
System.out.println(count);
}
/**
- 3.删除刚才添加的记录
*/
@Test
public void test3(){
String sql = “delete from emp where id = ?”;
int count = template.update(sql, 1015);
System.out.println(count);
}
/**
-
4.查询id为1001的记录,将其封装为Map集合
-
注意:这个方法查询的结果集长度只能是1
*/
@Test
public void test4(){
String sql = “select * from emp where id = ? or id = ?”;
Map<String, Object> map = template.queryForMap(sql, 1001,1002);
System.out.println(map);
//{id=1001, ename=孙悟空, job_id=4, mgr=1004, joindate=2000-12-17, salary=10000.00, bonus=null, dept_id=20}
}
/**
-
- 查询所有记录,将其封装为List
*/
@Test
public void test5(){
String sql = “select * from emp”;
List<Map<String, Object>> list = template.queryForList(sql);
for (Map<String, Object> stringObjectMap : list) {
System.out.println(stringObjectMap);
}
}
/**
-
- 查询所有记录,将其封装为Emp对象的List集合
*/
@Test
public void test6(){
String sql = “select * from emp”;
List list = template.query(sql, new RowMapper() {
@Override
public Emp mapRow(ResultSet rs, int i) throws SQLException {
Emp emp = new Emp();
int id = rs.getInt(“id”);
String ename = rs.getString(“ename”);
int job_id = rs.getInt(“job_id”);
int mgr = rs.getInt(“mgr”);
Date joindate = rs.getDate(“joindate”);
double salary = rs.getDouble(“salary”);
double bonus = rs.getDouble(“bonus”);
int dept_id = rs.getInt(“dept_id”);
emp.setId(id);
emp.setEname(ename);
emp.setJob_id(job_id);
emp.setMgr(mgr);
emp.setJoindate(joindate);
emp.setSalary(salary);
emp.setBonus(bonus);
emp.setDept_id(dept_id);
return emp;
}
});
for (Emp emp : list) {
System.out.println(emp);
}
}
/**
-
- 查询所有记录,将其封装为Emp对象的List集合
*/
@Test
public void test6_2(){
String sql = “select * from emp”;
List list = template.query(sql, new BeanPropertyRowMapper(Emp.class));
for (Emp emp : list) {
System.out.println(emp);
}
}
/**
-
- 查询总记录数
*/
@Test
public void test7(){
String sql = “select count(id) from emp”;
Long total = template.queryForObject(sql, Long.class);
System.out.println(total);
}
}
- 概念:Extensible Markup Language 可扩展标记语言
-
可扩展:标签都是自定义的。
-
功能
-
存储数据
-
配置文件
-
在网络中传输
- xml与html的区别
-
xml标签都是自定义的,html标签是预定义。
-
xml的语法严格,html语法松散
-
xml是存储数据的,html是展示数据
- w3c:万维网联盟
- 语法:
- 基本语法:
-
xml文档的后缀名 .xml
-
xml第一行必须定义为文档声明
-
xml文档中有且仅有一个根标签
-
属性值必须使用引号(单双都可)引起来
-
标签必须正确关闭
-
xml标签名称区分大小写
- 快速入门:
zhangsan
23
male
lisi
24
female
- 组成部分:
-
文档声明
-
格式:<?xml 属性列表 ?>
-
属性列表:
-
version:版本号,必须的属性
-
encoding:编码方式。告知解析引擎当前文档使用的字符集,默认值:ISO-8859-1
-
standalone:是否独立
-
取值:
-
yes:不依赖其他文件
-
no:依赖其他文件
- 指令(了解):结合css的
- <?xml-stylesheet type="text/css" href="a.css" ?>
- 标签:标签名称自定义的
-
规则:
-
名称可以包含字母、数字以及其他的字符
-
名称不能以数字或者标点符号开始
-
名称不能以字母 xml(或者 XML、Xml 等等)开始
-
名称不能包含空格
- 属性:
id属性值唯一
- 文本:
-
CDATA区:在该区域中的数据会被原样展示
-
格式: <![CDATA[ 数据 ]]>
-
约束:规定xml文档的书写规则
-
作为框架的使用者(程序员):
-
能够在xml中引入约束文档
-
能够简单的读懂约束文档
- 分类:
-
DTD:一种简单的约束技术
-
Schema:一种复杂的约束技术
Dtd
-
DTD:
-
引入dtd文档到xml文档中
-
内部dtd:将约束规则定义在xml文档中
-
外部dtd:将约束的规则定义在外部的dtd文件中
-
本地:
-
网络:
Schema
-
Schema:
-
引入:
1.填写xml文档的根元素
2.引入xsi前缀. xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”
3.引入xsd文件命名空间. xsi:schemaLocation=“http://www.itcast.cn/xml student.xsd”
4.为每一个xsd约束声明一个前缀,作为标识 xmlns=“http://www.itcast.cn/xml”
<students xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”
xmlns=“http://www.itcast.cn/xml”
xsi:schemaLocation=“http://www.itcast.cn/xml student.xsd”>
解析xml
- 解析:操作xml文档,将文档中的数据读取到内存中
- 操作xml文档
-
解析(读取):将文档中的数据读取到内存中
-
写入:将内存中的数据保存到xml文档中。持久化的存储
- 解析xml的方式:
- DOM:将标记语言文档一次性加载进内存,在内存中形成一颗dom树
-
优点:操作方便,可以对文档进行CRUD的所有操作
-
缺点:占内存
- SAX:逐行读取,基于事件驱动的。
-
优点:不占内存。
-
缺点:只能读取,不能增删改
-
xml常见的解析器:
-
JAXP:sun公司提供的解析器,支持dom和sax两种思想
-
DOM4J:一款非常优秀的解析器
-
Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
-
PULL:Android操作系统内置的解析器,sax方式的。
-
Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
-
快速入门:
-
步骤:
-
导入jar包
-
获取Document对象
-
获取对应的标签Element对象
-
获取数据
- 代码:
//2.1获取student.xml的path
String path = JsoupDemo1.class.getClassLoader().getResource(“student.xml”).getPath();
//2.2解析xml文档,加载文档进内存,获取dom树—>Document
Document document = Jsoup.parse(new File(path), “utf-8”);
//3.获取元素对象 Element
Elements elements = document.getElementsByTag(“name”);
System.out.println(elements.size());
//3.1获取第一个name的Element对象
Element element = elements.get(0);
//3.2获取数据
String name = element.text();
System.out.println(name);
- 对象的使用:
- Jsoup:工具类,可以解析html或xml文档,返回Document
-
parse:解析html或xml文档,返回Document
-
parse(File in, String charsetName):解析xml或html文件的。
-
parse(String html):解析xml或html字符串
-
parse(URL url, int timeoutMillis):通过网络路径获取指定的html或xml的文档对象
- Document:文档对象。代表内存中的dom树
-
获取Element对象
-
getElementById(String id):根据id属性值获取唯一的element对象
-
getElementsByTag(String tagName):根据标签名称获取元素对象集合
-
getElementsByAttribute(String key):根据属性名称获取元素对象集合
-
getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
-
Elements:元素Element对象的集合。可以当做 ArrayList来使用
-
Element:元素对象
-
获取子元素对象
-
getElementById(String id):根据id属性值获取唯一的element对象
-
getElementsByTag(String tagName):根据标签名称获取元素对象集合
-
getElementsByAttribute(String key):根据属性名称获取元素对象集合
-
getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
- 获取属性值
- String attr(String key):根据属性名称获取属性值
- 获取文本内容
-
String text():获取文本内容
-
String html():获取标签体的所有内容(包括字标签的字符串内容)
- Node:节点对象
-
是Document和Element的父类
-
快捷查询方式:
- selector:选择器
-
使用的方法:Elements select(String cssQuery)
-
语法:参考Selector类中定义的语法
- XPath:XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言
-
使用Jsoup的Xpath需要额外导入jar包。
-
查询w3cshool参考手册,使用xpath的语法完成查询
-
代码:
//1.获取student.xml的path
String path = JsoupDemo6.class.getClassLoader().getResource(“student.xml”).getPath();
//2.获取Document对象
Document document = Jsoup.parse(new File(path), “utf-8”);
//3.根据document对象,创建JXDocument对象
JXDocument jxDocument = new JXDocument(document);
//4.结合xpath语法查询
//4.1查询所有student标签
List jxNodes = jxDocument.selN(“//student”);
for (JXNode jxNode : jxNodes) {
System.out.println(jxNode);
}
System.out.println(“--------------------”);
//4.2查询所有student标签下的name标签
List jxNodes2 = jxDocument.selN(“//student/name”);
for (JXNode jxNode : jxNodes2) {
System.out.println(jxNode);
}
System.out.println(“--------------------”);
//4.3查询student标签下带有id属性的name标签
List jxNodes3 = jxDocument.selN(“//student/name[@id]”);
for (JXNode jxNode : jxNodes3) {
System.out.println(jxNode);
}
System.out.println(“--------------------”);
//4.4查询student标签下带有id属性的name标签 并且id属性值为itcast
List jxNodes4 = jxDocument.selN(“//student/name[@id=‘itcast’]”);
for (JXNode jxNode : jxNodes4) {
System.out.println(jxNode);
}
- Tomcat:web服务器软件
-
下载:http://tomcat.apache.org/
-
安装:解压压缩包即可。
- 注意:安装目录建议不要有中文和空格
-
卸载:删除目录就行了
-
启动:
-
bin/startup.bat ,双击运行该文件即可
-
访问:浏览器输入:http://localhost:8080 回车访问自己
http://别人的ip:8080 访问别人
- 可能遇到的问题:
- 黑窗口一闪而过:
-
原因: 没有正确配置JAVA_HOME环境变量
-
解决方案:正确配置JAVA_HOME环境变量
-
启动报错:
-
暴力:找到占用的端口号,并且找到对应的进程,杀死该进程
- netstat -ano
- 温柔:修改自身的端口号
-
conf/server.xml
-
<Connector port=“8888” protocol=“HTTP/1.1”
connectionTimeout=“20000”
redirectPort=“8445” />
-
一般会将tomcat的默认端口号修改为80。80端口号是http协议的默认端口号。
-
好处:在访问时,就不用输入端口号
-
关闭:
-
正常关闭:
-
bin/shutdown.bat
-
ctrl+c
- 强制关闭:
- 点击启动窗口的×
- 配置:
- 部署项目的方式:
- 直接将项目放到webapps目录下即可。
-
/hello:项目的访问路径–>虚拟目录
-
简化部署:将项目打成一个war包,再将war包放置到webapps目录下。
-
war包会自动解压缩
- 配置conf/server.xml文件
在标签体中配置
-
docBase:项目存放的路径
-
path:虚拟目录
- 在conf\Catalina\localhost创建任意名称的xml文件。在文件中编写
-
虚拟目录:xml文件的名称
-
静态项目和动态项目:
-
目录结构
-
java动态项目的目录结构:
– 项目的根目录
– WEB-INF目录:
– web.xml:web项目的核心配置文件
– classes目录:放置字节码文件的目录
– lib目录:放置依赖的jar包
-
概念
-
步骤
-
执行原理
-
生命周期
-
Servlet3.0 注解配置
-
Servlet的体系结构
Servlet – 接口
|
GenericServlet – 抽象类
|
HttpServlet – 抽象类
-
GenericServlet:将Servlet接口中其他的方法做了默认空实现,只将service()方法作为抽象
-
将来定义Servlet类时,可以继承GenericServlet,实现service()方法即可
-
HttpServlet:对http协议的一种封装,简化操作
-
定义类继承HttpServlet
-
复写doGet/doPost方法
-
Servlet相关配置
-
urlpartten:Servlet访问路径
-
一个Servlet可以定义多个访问路径 : @WebServlet({“/d4”,“/dd4”,“/ddd4”})
-
路径定义规则:
-
/xxx:路径匹配
-
/xxx/xxx:多层路径,目录结构
-
*.do:扩展名匹配
Http
-
概念:Hyper Text Transfer Protocol 超文本传输协议
-
传输协议:定义了,客户端和服务器端通信时,发送数据的格式
-
特点:
-
基于TCP/IP的高级协议
-
默认端口号:80
-
基于请求/响应模型的:一次请求对应一次响应
-
无状态的:每次请求之间相互独立,不能交互数据
-
历史版本:
-
1.0:每一次请求响应都会建立新的连接
-
1.1:复用连接
-
请求消息数据格式
- 请求行
请求方式 请求url 请求协议/版本
GET /login.html HTTP/1.1
-
请求方式:
-
HTTP协议有7种请求方式,常用的有2种
-
GET:
-
请求参数在请求行中,在url后。
-
请求的url长度有限制的
-
不太安全
- POST:
-
请求参数在请求体中
-
请求的url长度没有限制的
-
相对安全
-
请求头:客户端浏览器告诉服务器一些信息
请求头名称: 请求头值
- 常见的请求头:
- User-Agent:浏览器告诉服务器,我访问你使用的浏览器版本信息
- 可以在服务器端获取该头的信息,解决浏览器的兼容性问题
- Referer:http://localhost/login.html
-
告诉服务器,我(当前请求)从哪里来?
-
作用:
-
防盗链:
-
统计工作:
-
请求空行
空行,就是用于分割POST请求的请求头,和请求体的。
- 请求体(正文):
-
封装POST请求消息的请求参数的
-
字符串格式:
POST /login.html HTTP/1.1
Host: localhost
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Referer: http://localhost/login.html
Connection: keep-alive
Upgrade-Insecure-Requests: 1
username=zhangsan
Request
-
request对象和response对象的原理
-
request和response对象是由服务器创建的。我们来使用它们
-
request对象是来获取请求消息,response对象是来设置响应消息
-
request对象继承体系结构:
ServletRequest – 接口
| 继承
HttpServletRequest – 接口
| 实现
org.apache.catalina.connector.RequestFacade 类(tomcat)
-
request功能:
-
获取请求消息数据
-
获取请求行数据
-
GET /day14/demo1?name=zhangsan HTTP/1.1
-
方法:
- 获取请求方式 :GET
- String getMethod()
- (*)获取虚拟目录:/day14
- String getContextPath()
- 获取Servlet路径: /demo1
- String getServletPath()
- 获取get方式请求参数:name=zhangsan
- String getQueryString()
- (*)获取请求URI:/day14/demo1
-
String getRequestURI(): /day14/demo1
-
StringBuffer getRequestURL() :http://localhost/day14/demo1
-
URL:统一资源定位符 : http://localhost/day14/demo1 中华人民共和国
-
URI:统一资源标识符 : /day14/demo1 共和国
- 获取协议及版本:HTTP/1.1
- String getProtocol()
- 获取客户机的IP地址:
- String getRemoteAddr()
- 获取请求头数据
-
方法:
-
(*)String getHeader(String name):通过请求头的名称获取请求头的值
-
Enumeration getHeaderNames():获取所有的请求头名称
- 获取请求体数据:
-
请求体:只有POST请求方式,才有请求体,在请求体中封装了POST请求的请求参数
-
步骤:
- 获取流对象
-
BufferedReader getReader():获取字符输入流,只能操作字符数据
-
ServletInputStream getInputStream():获取字节输入流,可以操作所有类型数据
-
在文件上传知识点后讲解
-
再从流对象中拿数据
-
其他功能:
-
获取请求参数通用方式:不论get还是post请求方式都可以使用下列方法来获取请求参数
-
String getParameter(String name):根据参数名称获取参数值 username=zs&password=123
-
String[] getParameterValues(String name):根据参数名称获取参数值的数组 hobby=xx&hobby=game
-
Enumeration getParameterNames():获取所有请求的参数名称
-
Map<String,String[]> getParameterMap():获取所有参数的map集合
-
中文乱码问题:
-
get方式:tomcat 8 已经将get方式乱码问题解决了
-
post方式:会乱码
-
解决:在获取参数前,设置request的编码request.setCharacterEncoding(“utf-8”);
-
请求转发:一种在服务器内部的资源跳转方式
-
步骤:
-
通过request对象获取请求转发器对象:RequestDispatcher getRequestDispatcher(String path)
-
使用RequestDispatcher对象来进行转发:forward(ServletRequest request, ServletResponse response)
-
特点:
-
浏览器地址栏路径不发生变化
-
只能转发到当前服务器内部资源中。
-
转发是一次请求
-
共享数据:
-
域对象:一个有作用范围的对象,可以在范围内共享数据
-
request域:代表一次请求的范围,一般用于请求转发的多个资源中共享数据
-
方法:
-
void setAttribute(String name,Object obj):存储数据
-
Object getAttitude(String name):通过键获取值
-
void removeAttribute(String name):通过键移除键值对
-
获取ServletContext:
- ServletContext getServletContext()
Response
- 数据格式:
-
响应行
-
组成:协议/版本 响应状态码 状态码描述
-
响应状态码:服务器告诉客户端浏览器本次请求和响应的一个状态。
-
状态码都是3位数字
-
分类:
-
1xx:服务器就收客户端消息,但没有接受完成,等待一段时间后,发送1xx多状态码
-
2xx:成功。代表:200
-
3xx:重定向。代表:302(重定向),304(访问缓存)
-
4xx:客户端错误。
-
代表:
-
404(请求路径没有对应的资源)
-
405:请求方式没有对应的doXxx方法
-
5xx:服务器端错误。代表:500(服务器内部出现异常)
-
响应头:
-
格式:头名称: 值
-
常见的响应头:
-
Content-Type:服务器告诉客户端本次响应体数据格式以及编码格式
-
Content-disposition:服务器告诉客户端以什么格式打开响应体数据
-
值:
-
in-line:默认值,在当前页面内打开
-
attachment;filename=xxx:以附件形式打开响应体。文件下载
-
响应空行
-
响应体:传输的数据
- 功能:设置响应消息
-
设置响应行
-
格式:HTTP/1.1 200 ok
-
设置状态码:setStatus(int sc)
-
设置响应头:setHeader(String name, String value)
-
设置响应体:
- 使用步骤:
- 获取输出流
-
字符输出流:PrintWriter getWriter()
-
字节输出流:ServletOutputStream getOutputStream()
- 使用输出流,将数据输出到客户端浏览器
- 案例:
- 完成重定向
-
重定向:资源跳转的方式
-
代码实现:
//1. 设置状态码为302
response.setStatus(302);
//2.设置响应头location
response.setHeader(“location”,“/day15/responseDemo2”);
//简单的重定向方法
response.sendRedirect(“/day15/responseDemo2”);
- 重定向的特点:redirect
-
地址栏发生变化
-
重定向可以访问其他站点(服务器)的资源
-
重定向是两次请求。不能使用request对象来共享数据
- 转发的特点:forward
-
转发地址栏路径不变
-
转发只能访问当前服务器下的资源
-
转发是一次请求,可以使用request对象来共享数据
-
forward 和 redirect 区别
-
路径写法:
-
路径分类
-
相对路径:通过相对路径不可以确定唯一资源
-
如:./index.html
-
不以/开头,以.开头路径
-
规则:找到当前资源和目标资源之间的相对位置关系
-
./:当前目录
-
…/:后退一级目录
- 绝对路径:通过绝对路径可以确定唯一资源
-
如:http://localhost/day15/responseDemo2 /day15/responseDemo2
-
以/开头的路径
-
规则:判断定义的路径是给谁用的?判断请求将来从哪儿发出
-
给客户端浏览器使用:需要加虚拟目录(项目的访问路径)
-
建议虚拟目录动态获取:request.getContextPath()
-
, 重定向…
-
给服务器使用:不需要加虚拟目录
-
转发路径
- 服务器输出字符数据到浏览器
- 步骤:
-
获取字符输出流
-
输出数据
-
注意:
-
乱码问题:
-
PrintWriter pw = response.getWriter();获取的流的默认编码是ISO-8859-1
-
设置该流的默认编码
-
告诉浏览器响应体使用的编码
//简单的形式,设置编码,是在获取流之前设置
response.setContentType(“text/html;charset=utf-8”);
- 服务器输出字节数据到浏览器
- 步骤:
-
获取字节输出流
-
输出数据
-
验证码
-
本质:图片
-
目的:防止恶意表单注册
ServletContext
-
概念:代表整个web应用,可以和程序的容器(服务器)来通信
-
获取:
-
通过request对象获取
request.getServletContext();
- 通过HttpServlet获取
this.getServletContext();
-
功能:
-
获取MIME类型:
-
MIME类型:在互联网通信过程中定义的一种文件数据类型
-
格式: 大类型/小类型 text/html image/jpeg
-
获取:String getMimeType(String file)
-
域对象:共享数据
-
setAttribute(String name,Object value)
-
getAttribute(String name)
-
removeAttribute(String name)
- ServletContext对象范围:所有用户所有请求的数据
-
获取文件的真实(服务器)路径
-
方法:String getRealPath(String path)
String b = context.getRealPath(“/b.txt”);//web目录下资源访问
System.out.println(b);
String c = context.getRealPath(“/WEB-INF/c.txt”);//WEB-INF目录下的资源访问
System.out.println©;
String a = context.getRealPath(“/WEB-INF/classes/a.txt”);//src目录下的资源访问
System.out.println(a);
- 会话:一次会话中包含多次请求和响应。
- 一次会话:浏览器第一次给服务器资源发送请求,会话建立,直到有一方断开为止
-
功能:在一次会话的范围内的多次请求间,共享数据
-
方式:
-
客户端会话技术:Cookie
-
服务器端会话技术:Session
Cookie
-
概念:客户端会话技术,将数据保存到客户端
-
快速入门:
- 使用步骤:
- 创建Cookie对象,绑定数据
- new Cookie(String name, String value)
- 发送Cookie对象
- response.addCookie(Cookie cookie)
- 获取Cookie,拿到数据
- Cookie[] request.getCookies()
- 实现原理
- 基于响应头set-cookie和请求头cookie实现
-
cookie的细节
-
一次可不可以发送多个cookie?
-
可以
-
可以创建多个Cookie对象,使用response调用多次addCookie方法发送cookie即可。
-
cookie在浏览器中保存多长时间?
-
默认情况下,当浏览器关闭后,Cookie数据被销毁
-
持久化存储:
- setMaxAge(int seconds)
-
正数:将Cookie数据写到硬盘的文件中。持久化存储。并指定cookie存活时间,时间到后,cookie文件自动失效
-
负数:默认值
-
零:删除cookie信息
-
cookie能不能存中文?
-
在tomcat 8 之前 cookie中不能直接存储中文数据。
-
需要将中文数据转码—一般采用URL编码(%E3)
-
在tomcat 8 之后,cookie支持中文数据。特殊字符还是不支持,建议使用URL编码存储,URL解码解析
-
cookie共享问题?
-
假设在一个tomcat服务器中,部署了多个web项目,那么在这些web项目中cookie能不能共享?
-
默认情况下cookie不能共享
-
setPath(String path):设置cookie的获取范围。默认情况下,设置当前的虚拟目录
-
如果要共享,则可以将path设置为"/"
- 不同的tomcat服务器间cookie共享问题?
-
setDomain(String path):如果设置一级域名相同,那么多个服务器之间cookie可以共享
-
setDomain(“.baidu.com”),那么tieba.baidu.com和news.baidu.com中cookie可以共享
-
Cookie的特点和作用
-
cookie存储数据在客户端浏览器
-
浏览器对于单个cookie 的大小有限制(4kb) 以及 对同一个域名下的总cookie数量也有限制(20个)
- 作用:
-
cookie一般用于存出少量的不太敏感的数据
-
在不登录的情况下,完成服务器对客户端的身份识别
-
案例:记住上一次访问时间
-
需求:
-
访问一个Servlet,如果是第一次访问,则提示:您好,欢迎您首次访问。
-
如果不是第一次访问,则提示:欢迎回来,您上次访问时间为:显示时间字符串
-
分析:
-
可以采用Cookie来完成
-
在服务器中的Servlet判断是否有一个名为lastTime的cookie
-
有:不是第一次访问
-
响应数据:欢迎回来,您上次访问时间为:2018年6月10日11:50:20
-
写回Cookie:lastTime=2018年6月10日11:50:01
-
没有:是第一次访问
-
响应数据:您好,欢迎您首次访问
-
写回Cookie:lastTime=2018年6月10日11:50:01
-
代码实现:
package cn.itcast.cookie;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.Cookie;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.text.SimpleDateFormat;
import java.util.Date;
@WebServlet(“/cookieTest”)
public class CookieTest extends HttpServlet {
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//设置响应的消息体的数据格式以及编码
response.setContentType(“text/html;charset=utf-8”);
//1.获取所有Cookie
Cookie[] cookies = request.getCookies();
boolean flag = false;//没有cookie为lastTime
//2.遍历cookie数组
if(cookies != null && cookies.length > 0){
for (Cookie cookie : cookies) {
//3.获取cookie的名称
String name = cookie.getName();
//4.判断名称是否是:lastTime
if(“lastTime”.equals(name)){
//有该Cookie,不是第一次访问
flag = true;//有lastTime的cookie
//设置Cookie的value
//获取当前时间的字符串,重新设置Cookie的值,重新发送cookie
Date date = new Date();
SimpleDateFormat sdf = new SimpleDateFormat(“yyyy年MM月dd日 HH:mm:ss”);
String str_date = sdf.format(date);
System.out.println(“编码前:”+str_date);
//URL编码
str_date = URLEncoder.encode(str_date,“utf-8”);
System.out.println(“编码后:”+str_date);
cookie.setValue(str_date);
//设置cookie的存活时间
cookie.setMaxAge(60 * 60 * 24 * 30);//一个月
response.addCookie(cookie);
//响应数据
//获取Cookie的value,时间
String value = cookie.getValue();
System.out.println(“解码前:”+value);
//URL解码:
value = URLDecoder.decode(value,“utf-8”);
System.out.println(“解码后:”+value);
response.getWriter().write(“
欢迎回来,您上次访问时间为:”+value+“
”);break;
}
}
}
if(cookies == null || cookies.length == 0 || flag == false){
//没有,第一次访问
//设置Cookie的value
//获取当前时间的字符串,重新设置Cookie的值,重新发送cookie
Date date = new Date();
SimpleDateFormat sdf = new SimpleDateFormat(“yyyy年MM月dd日 HH:mm:ss”);
String str_date = sdf.format(date);
System.out.println(“编码前:”+str_date);
//URL编码
str_date = URLEncoder.encode(str_date,“utf-8”);
System.out.println(“编码后:”+str_date);
Cookie cookie = new Cookie(“lastTime”,str_date);
//设置cookie的存活时间
cookie.setMaxAge(60 * 60 * 24 * 30);//一个月
response.addCookie(cookie);
response.getWriter().write(“
您好,欢迎您首次访问
”);}
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
this.doPost(request, response);
}
}
Session
-
概念:服务器端会话技术,在一次会话的多次请求间共享数据,将数据保存在服务器端的对象中。HttpSession
-
快速入门:
-
获取HttpSession对象:
HttpSession session = request.getSession();
- 使用HttpSession对象:
Object getAttribute(String name)
void setAttribute(String name, Object value)
void removeAttribute(String name)
- 原理
- Session的实现是依赖于Cookie的。
-
细节:
-
当客户端关闭后,服务器不关闭,两次获取session是否为同一个?
-
默认情况下。不是。
-
如果需要相同,则可以创建Cookie,键为JSESSIONID,设置最大存活时间,让cookie持久化保存。
Cookie c = new Cookie(“JSESSIONID”,session.getId());
c.setMaxAge(60*60);
response.addCookie©;
- 客户端不关闭,服务器关闭后,两次获取的session是同一个吗?
-
不是同一个,但是要确保数据不丢失。tomcat自动完成以下工作
-
session的钝化:
-
在服务器正常关闭之前,将session对象系列化到硬盘上
-
session的活化:
-
在服务器启动后,将session文件转化为内存中的session对象即可。
-
session什么时候被销毁?
-
服务器关闭
-
session对象调用invalidate() 。
-
session默认失效时间 30分钟
选择性配置修改
30
-
session的特点
-
session用于存储一次会话的多次请求的数据,存在服务器端
-
session可以存储任意类型,任意大小的数据
- session与Cookie的区别:
-
session存储数据在服务器端,Cookie在客户端
-
session没有数据大小限制,Cookie有
-
session数据安全,Cookie相对于不安全
- 概念:
-
生活中的过滤器:净水器,空气净化器,土匪、
-
web中的过滤器:当访问服务器的资源时,过滤器可以将请求拦截下来,完成一些特殊的功能。
-
过滤器的作用:
-
一般用于完成通用的操作。如:登录验证、统一编码处理、敏感字符过滤…
-
快速入门:
-
步骤:
-
定义一个类,实现接口Filter
-
复写方法
-
配置拦截路径
-
web.xml
-
注解
-
代码:
@WebFilter(“/*”)//访问所有资源之前,都会执行该过滤器
public class FilterDemo1 implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println(“filterDemo1被执行了…”);
//放行
filterChain.doFilter(servletRequest,servletResponse);
}
@Override
public void destroy() {
}
}
-
过滤器细节:
-
web.xml配置
demo1
cn.itcast.web.filter.FilterDemo1
demo1
/*
-
过滤器执行流程
-
执行过滤器
-
执行放行后的资源
-
回来执行过滤器放行代码下边的代码
-
过滤器生命周期方法
-
init:在服务器启动后,会创建Filter对象,然后调用init方法。只执行一次。用于加载资源
-
doFilter:每一次请求被拦截资源时,会执行。执行多次
-
destroy:在服务器关闭后,Filter对象被销毁。如果服务器是正常关闭,则会执行destroy方法。只执行一次。用于释放资源
-
过滤器配置详解
- 拦截路径配置:
-
具体资源路径: /index.jsp 只有访问index.jsp资源时,过滤器才会被执行
-
拦截目录: /user/* 访问/user下的所有资源时,过滤器都会被执行
-
后缀名拦截: *.jsp 访问所有后缀名为jsp资源时,过滤器都会被执行
-
拦截所有资源:/* 访问所有资源时,过滤器都会被执行
-
拦截方式配置:资源被访问的方式
-
注解配置:
-
设置dispatcherTypes属性
-
REQUEST:默认值。浏览器直接请求资源
-
FORWARD:转发访问资源
-
INCLUDE:包含访问资源
-
ERROR:错误跳转资源
-
ASYNC:异步访问资源
-
web.xml配置
-
设置标签即可
- 过滤器链(配置多个过滤器)
- 执行顺序:如果有两个过滤器:过滤器1和过滤器2
-
过滤器1
-
过滤器2
-
资源执行
-
过滤器2
-
过滤器1
- 过滤器先后顺序问题:
- 注解配置:按照类名的字符串比较规则比较,值小的先执行
- 如: AFilter 和 BFilter,AFilter就先执行了。
- web.xml配置: 谁定义在上边,谁先执行
-
概念:web的三大组件之一。
-
事件监听机制
-
事件 :一件事情
-
事件源 :事件发生的地方
-
监听器 :一个对象
-
注册监听:将事件、事件源、监听器绑定在一起。 当事件源上发生某个事件后,执行监听器代码
-
ServletContextListener:监听ServletContext对象的创建和销毁
-
方法:
-
void contextDestroyed(ServletContextEvent sce) :ServletContext对象被销毁之前会调用该方法
-
void contextInitialized(ServletContextEvent sce) :ServletContext对象创建后会调用该方法
-
步骤:
-
定义一个类,实现ServletContextListener接口
-
复写方法
-
配置
-
web.xml
cn.itcast.web.listener.ContextLoaderListener
- 指定初始化参数
- 注解:
- @WebListener
-
概念: ASynchronous JavaScript And XML 异步的JavaScript 和 XML
-
异步和同步:客户端和服务器端相互通信的基础上
-
客户端必须等待服务器端的响应。在等待的期间客户端不能做其他操作。
-
客户端不需要等待服务器端的响应。在服务器处理请求的过程中,客户端可以进行其他的操作。
Ajax 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。 [1]
通过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
传统的网页(不使用 Ajax)如果需要更新内容,必须重载整个网页页面。
提升用户的体验
-
实现方式:
-
原生的JS实现方式(了解)
//1.创建核心对象
var xmlhttp;
if (window.XMLHttpRequest)
{// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
}
else
{// code for IE6, IE5
xmlhttp=new ActiveXObject(“Microsoft.XMLHTTP”);
}
//2. 建立连接
/*
参数:
- 请求方式:GET、POST
-
get方式,请求参数在URL后边拼接。send方法为空参
-
post方式,请求参数在send方法中定义
-
请求的URL:
-
同步或异步请求:true(异步)或 false(同步)
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
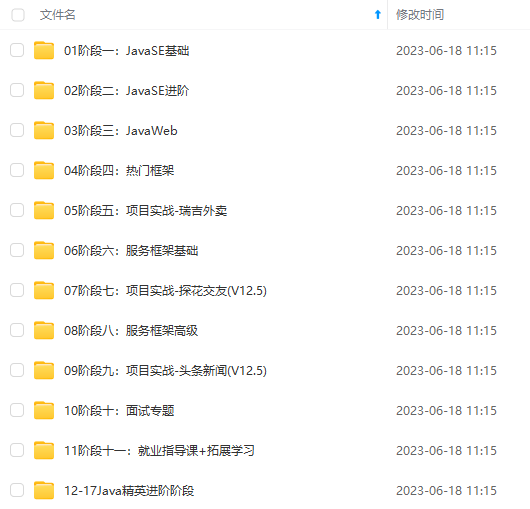
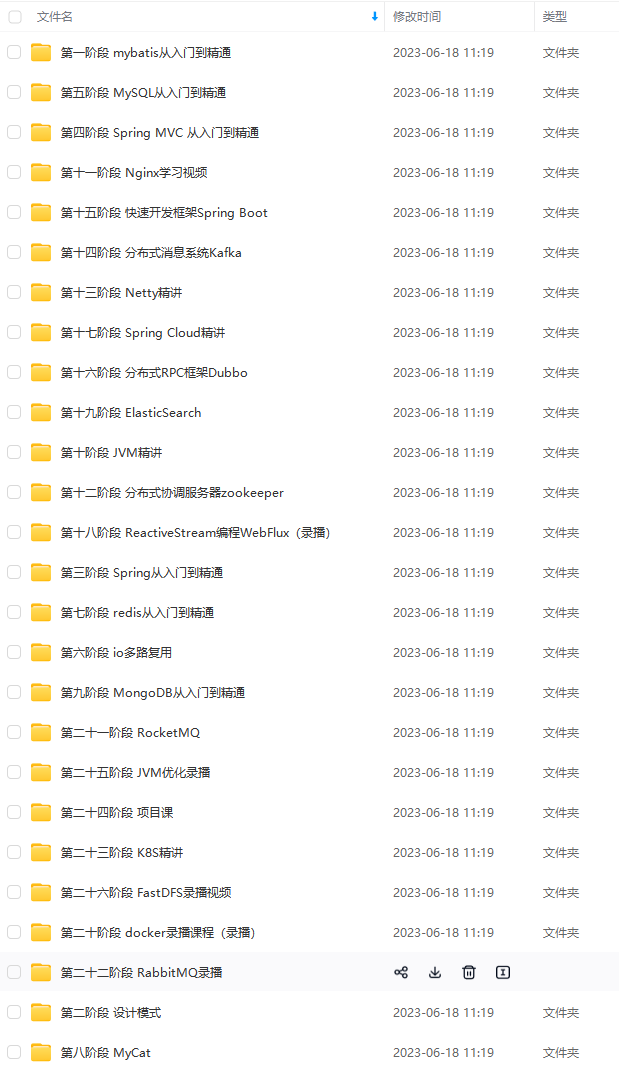
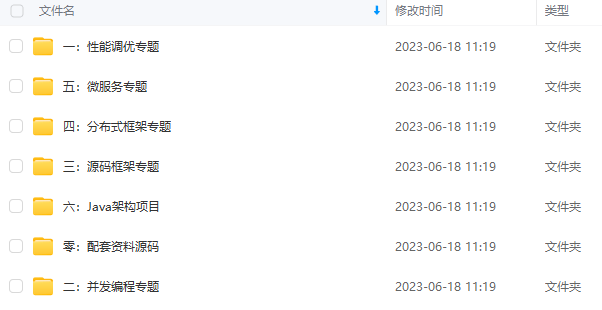
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,不论你是刚入门Android开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
过滤器细节:
- web.xml配置
demo1
cn.itcast.web.filter.FilterDemo1
demo1
/*
-
过滤器执行流程
-
执行过滤器
-
执行放行后的资源
-
回来执行过滤器放行代码下边的代码
-
过滤器生命周期方法
-
init:在服务器启动后,会创建Filter对象,然后调用init方法。只执行一次。用于加载资源
-
doFilter:每一次请求被拦截资源时,会执行。执行多次
-
destroy:在服务器关闭后,Filter对象被销毁。如果服务器是正常关闭,则会执行destroy方法。只执行一次。用于释放资源
-
过滤器配置详解
- 拦截路径配置:
-
具体资源路径: /index.jsp 只有访问index.jsp资源时,过滤器才会被执行
-
拦截目录: /user/* 访问/user下的所有资源时,过滤器都会被执行
-
后缀名拦截: *.jsp 访问所有后缀名为jsp资源时,过滤器都会被执行
-
拦截所有资源:/* 访问所有资源时,过滤器都会被执行
-
拦截方式配置:资源被访问的方式
-
注解配置:
-
设置dispatcherTypes属性
-
REQUEST:默认值。浏览器直接请求资源
-
FORWARD:转发访问资源
-
INCLUDE:包含访问资源
-
ERROR:错误跳转资源
-
ASYNC:异步访问资源
-
web.xml配置
-
设置标签即可
- 过滤器链(配置多个过滤器)
- 执行顺序:如果有两个过滤器:过滤器1和过滤器2
-
过滤器1
-
过滤器2
-
资源执行
-
过滤器2
-
过滤器1
- 过滤器先后顺序问题:
- 注解配置:按照类名的字符串比较规则比较,值小的先执行
- 如: AFilter 和 BFilter,AFilter就先执行了。
- web.xml配置: 谁定义在上边,谁先执行
-
概念:web的三大组件之一。
-
事件监听机制
-
事件 :一件事情
-
事件源 :事件发生的地方
-
监听器 :一个对象
-
注册监听:将事件、事件源、监听器绑定在一起。 当事件源上发生某个事件后,执行监听器代码
-
ServletContextListener:监听ServletContext对象的创建和销毁
-
方法:
-
void contextDestroyed(ServletContextEvent sce) :ServletContext对象被销毁之前会调用该方法
-
void contextInitialized(ServletContextEvent sce) :ServletContext对象创建后会调用该方法
-
步骤:
-
定义一个类,实现ServletContextListener接口
-
复写方法
-
配置
-
web.xml
cn.itcast.web.listener.ContextLoaderListener
- 指定初始化参数
- 注解:
- @WebListener
-
概念: ASynchronous JavaScript And XML 异步的JavaScript 和 XML
-
异步和同步:客户端和服务器端相互通信的基础上
-
客户端必须等待服务器端的响应。在等待的期间客户端不能做其他操作。
-
客户端不需要等待服务器端的响应。在服务器处理请求的过程中,客户端可以进行其他的操作。
Ajax 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。 [1]
通过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
传统的网页(不使用 Ajax)如果需要更新内容,必须重载整个网页页面。
提升用户的体验
-
实现方式:
-
原生的JS实现方式(了解)
//1.创建核心对象
var xmlhttp;
if (window.XMLHttpRequest)
{// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
}
else
{// code for IE6, IE5
xmlhttp=new ActiveXObject(“Microsoft.XMLHTTP”);
}
//2. 建立连接
/*
参数:
- 请求方式:GET、POST
-
get方式,请求参数在URL后边拼接。send方法为空参
-
post方式,请求参数在send方法中定义
-
请求的URL:
-
同步或异步请求:true(异步)或 false(同步)
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
[外链图片转存中…(img-PiQTx2b5-1715353350705)]
[外链图片转存中…(img-WCRvHopg-1715353350706)]
[外链图片转存中…(img-2g4S8oJj-1715353350706)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,不论你是刚入门Android开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!















 638
638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









