






在Stable Diffusion中,模型并不只有一种,不同插件有不同的模型,分别作用于不同的功能。今天就带大家一起来学习一下~
01
大模型
也就是stable diffusion模型,在默认界面中,它位于web页面的左上角,下拉列表对应的模型:
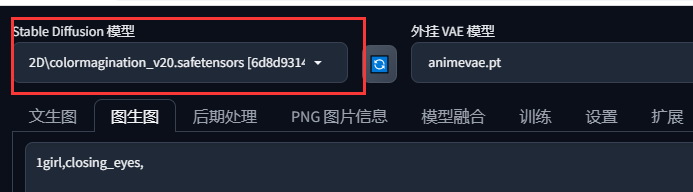
可以理解为绘画风格集合,SD需要大模型来规定它生成的图片风格,大模型是必选模型,你必须选择一个大模型才能开始生成工作。
如何获取?
这部分模型可以通过在各个模型网站下载,如果有代理可以前往civitai.com ,也叫做C站,以及huggingface.co 叫做抱脸。
如果没有代理,可以前往 liblib.ai 下载,但是需要注意的是,这些网站上通常是包括多种类型的模型,并不是所有模型都是用于这里的, 你需要选择 checkpoint类型,文件尺寸大于等于1.8G的,通常是大模型。
大模型的放置位置在整合包根目录下的 \models\Stable-diffusion\ 目录内,可以通过建立下级目录的方式进行分类,方便管理。
下载的新模型放置好之后,可以直接点击网页上下拉列表旁边的刷新按钮,直接加载。当然,也可以通过关闭页面并重启控制台来重新加载。
02
LoRA
在默认界面中,SD1.6以上的版本,lora显示在生成标签的最右侧:
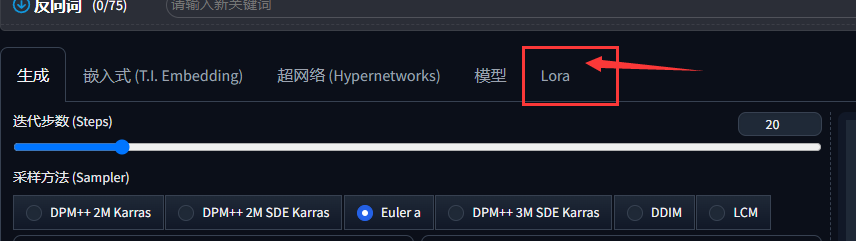
lora是可选模型,即便没有lora,也可以正常生成图像。
lora模型的文件位置在根目录\models\Lora,下载对应的模型放入即可,下载网站跟上面的大模型是相同的几个网站,只是类型要选lora类型。
重复一遍,大模型的类型通常是checkpoint,而lora的类型通常就是lora。这里说的类型不是指下载下来的文件类型,而是网站对于模型的分类,这一点一定要记住。
lora和大模型以及下面说的嵌入式模型,他们的文件后缀都是相同的,光凭借后缀是无法区分的,你必须在下载每个模型的时候确定它属于什么,再放到对应目录,而不是一股脑下载完才开始挪。
lora是在大模型基础上进行进一步修改的算法,一般是比如特定人物lora或者是调整色彩饱和度之类的专门的作用。
lora的调用方式很简单,如果是你自己的lora,你可以通过点击lora卡片的方式,自动调用lora,会在你的提示词区域自动生成一个带有尖括号的特殊词组,例如:
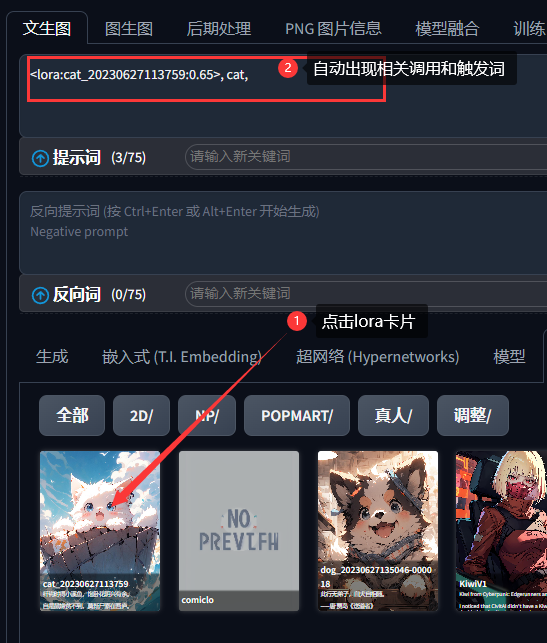
关于lora的进一步使用,以及权重的相关解释,请前往B站或其它平台,另行搜索相关教程视频了解。
03
嵌入式
它通常是作用于反提示词(负面提示词)的,经典的常用模型包括EasyNegative, negative_hand 之类的。它的位置在生成标签旁边:

使用方式跟lora一样,点击卡片就可以使用了,会自动出现在反向提示词内。当然你也可以手动输入或复制对应的触发词(通常是文件名)。
嵌入式模型的文件位置在 根目录\embeddings ,下载对应的嵌入式模型放入即可。
04
controlnet模型
这是插件 controlnet 需要使用模型。它在界面上位于生成标签内,如果你安装了这个插件的话。目前秋叶整合包应该是初始就带了controlnet插件:
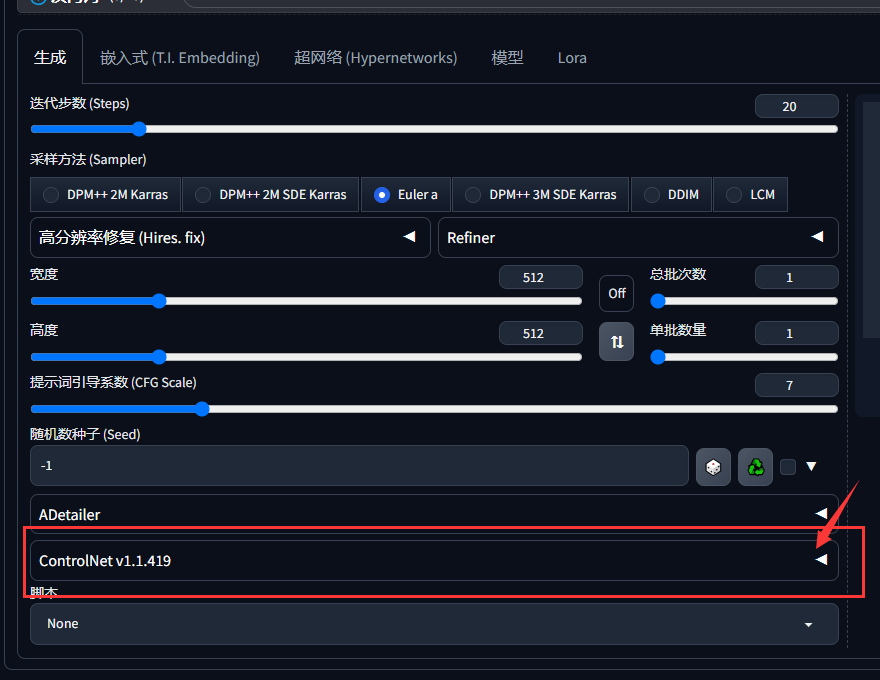
通过点击右方的三角箭头,展开controlnet设置,其中有一行 预处理器 和 模型 的下拉选择,我们这里说到的模型就是特指这里的controlnet模型:

确切地说,它的完整名称应该叫 controlnet专用模型。
在这个界面中,“预处理器”对应的是
根目录\extensions\sd-webui-controlnet\annotator\downloads
这个位置,但这里比较复杂,你需要仔细看相关教程放好对应的文件夹和文件。
“模型”的下拉菜单,对应的是 根目录\models\ControlNet 这个位置,或者是 \extensions\sd-webui-controlnet\models 这个目录,这两个目录都可以生效,系统会自动从这两个目录中寻找你放入的模型进行加载。
总的来说,controlnet一个新的算法它包含两部分,一个是预处理器,一个是模型,两者缺一不可。
对于controlnet模型的基础知识就介绍到这,controlnet因为是一个非常经典的插件
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
















 2210
2210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









