







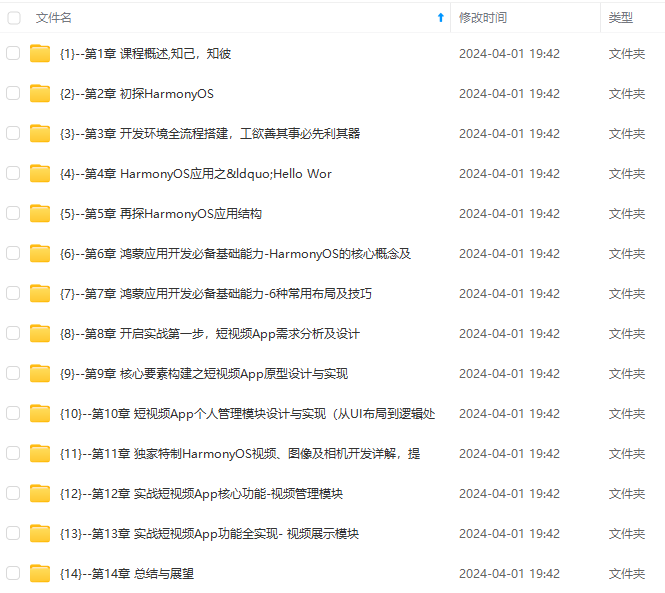

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
| 4 | TreeMap<K,V> | 1、有序Map,可以通过排序比较器来自定义存储数据的排序规则,默认按照key的生序排列2、使用时key需要实现Comparable接口或者通过构造函数传入自定义Comparator |
存储结构
jdk1.8以后HashMap采用数组+链表/红黑树的方式来存储数据

源码分析
主干
// HashMap的主干,也就是上面的绿色部分,是一个Node<K,V>数组,每个Node包含一个K-V键值对
transient Node<K,V>[] table;
节点元素
// Node<K,V>是HashMap的静态内部类,实现了Map接口中的内部Entry接口
static class Node<K,V> implements Map.Entry<K,V> {
// 记录当前Node的key的hash值,可以避免重复计算,空间换时间
final int hash;
// 键
final K key;
// 值
V value;
// 存储指向下一个Entry的引用,是单向链表结构
Node<K,V> next;
// ...
}
其他重要字段
// 默认的初始容量 16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量,1左移30位
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认扩容因子 0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 链表转红黑树的链表长度
static final int TREEIFY_THRESHOLD = 8;
// 红黑树转链表的阈值
static final int UNTREEIFY_THRESHOLD = 6;
// 链表转红黑树的数组长度
static final int MIN_TREEIFY_CAPACITY = 64;
// 实际存储K-V键值对的个数
transient int size;
// 记录HashMap被改动的次数,由于HashMap非线程安全,modCount可用于FailFast机制
transient int modCount;
// 扩容阈值,默认16\*0.75=12,当填充到13个元素时,扩容后将会变为32,
int threshold;
// 负载因子 loadFactor=capacity\*threshold,HashMap扩容需要参考loadFactor的值
final float loadFactor;
构造函数
// 看一个参数比较全的构造函数,构造函数中并未给table分配内存空间,此构造函数HashMap(Map<? extends K, ? extends V> m)会给table分配内存空间
public HashMap(int initialCapacity, float loadFactor) {
// 判断初始化容量是否合法,如果<0则抛出异常
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
// 判断initialCapacity是否大于 1<<30,如果大于则取 1<<30 = 2^30
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 判断负载因子是否合法,如果小于等于0或者isNaN,loadFactor!=loadFactor,则抛出异常
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +loadFactor);
// 赋值loadFactor
this.loadFactor = loadFactor;
// 通过位运算将threshold设值为最接近initialCapacity的一个2的幂次方(这里非常重要)
this.threshold = tableSizeFor(initialCapacity);
}
hash算法实现
HashMap中的hash算法实现分为三步。其中第二步使用hash值高16位参与位运算,是为了保证在数组table的length比较小的时候,可以保证高低bit都参与到hash运算中,保证分配均匀的同时采用位运算,也不会有太多的性能消耗;其中第三步,当n是2的整数的幂次方是,hash&(n-1),相当于对hash值取模,而位运算比取模运算效率更高;具体流程可以通过图示查看。
第一步:通过key.hashCode()获取key的hashcode;
第二步:通过(h = key.hashCode()) ^ (h >>> 16)进行高16位的位运算;
第三步:通过(n - 1) & hash对计算的hash值取模运算,得到节点插入的数组所在位置。
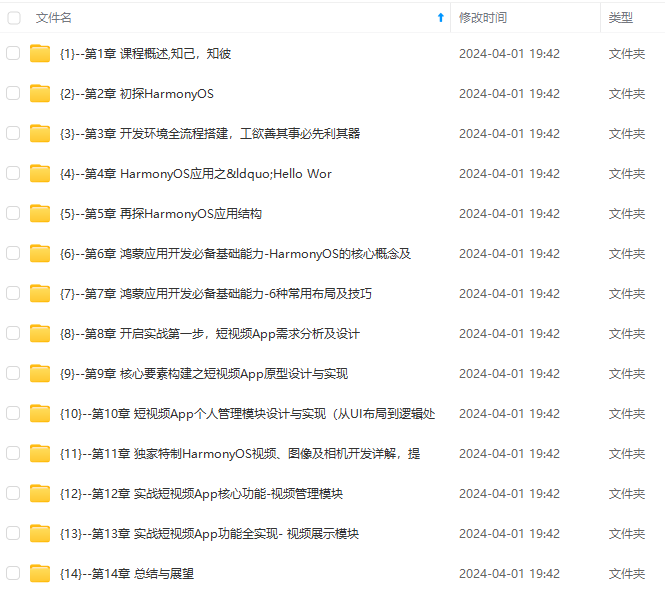

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
s://bbs.csdn.net/topics/618636735)**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









