







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
java.lang.String value) {
if (value == null) {
throw new NullPointerException();
}
name_ = value;
onChanged();
return this;
}
最后,我们来看下Builder的build方法,这里调用了buildPartial方法
@java.lang.Override
public cn.tera.protobuf.model.BasicUsage.Person build() {
cn.tera.protobuf.model.BasicUsage.Person result = buildPartial();
if (!result.isInitialized()) {
throw newUninitializedMessageException(result);
}
return result;
}
查看buildPartial方法,可以看到这里调用了Person获取builder参数的构造函数,和前文对应
构造完成后,将Builder中的各种字段赋值给Person中的相应字段,即完成了构造
@java.lang.Override
public cn.tera.protobuf.model.BasicUsage.Person buildPartial() {
cn.tera.protobuf.model.BasicUsage.Person result = new cn.tera.protobuf.model.BasicUsage.Person(this);
result.name_ = name_;
result.id_ = id_;
result.email_ = email_;
onBuilt();
return result;
}
总结一下:
1.protocol buffer需要定义.proto描述文件,然后通过google提供的编译器生成特定的模型文件,之后就可以作为正常的java对象使用了
2.不可以直接创建对象,需要通过Builder进行
3.只有Builder才可以进行set
4.可以通过对象的toByteArray()和parseFrom()方法进行编码和解码
5.模型文件很大(至少在java这里是如此),其中所有的代码都是定制的,这其实是它很大的缺点之一
接着我们将继续深入探究protobuf的编码原理。
主要分为两个部分
第一部分是之前留下的几个伏笔展示protobuf的使用特性
第二部分是分析protobuf的编码原理,解释特性背后的原因
第一部分,Protobuf使用特性
1.不同类型对象的转换
我们先定义如下一个.proto文件
syntax = “proto3”;
option java_package = “cn.tera.protobuf.model”;
option java_outer_classname = “DifferentModels”;
message Person {
string name = 1;
int32 id = 2;
string email = 3;
}
message Article {
string title = 1;
int32 wordsCount = 2;
string author = 3;
}
其中我们定义了2个模型,一个Person,一个Article,虽然他们的字段名字不相同,但是类型和编号都是一致的
接着我们生成.java文件,最终文件结构如下图
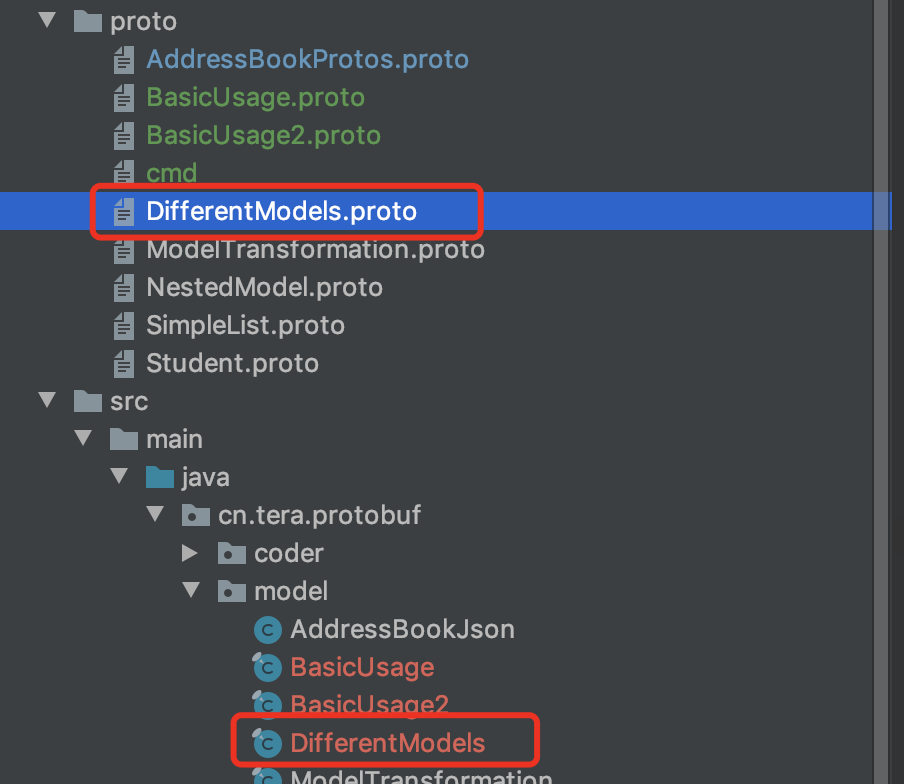
此时我们尝试做如下的一个转换
/**
- 测试不同模型间的转换
- @throws Exception
*/
@Test
public void parseDifferentModelsTest() throws Exception {
//创建一个Person对象
DifferentModels.Person person = DifferentModels.Person.newBuilder()
.setName(“person name”)
.setId(1)
.setEmail(“tera@google.com”)
.build();
//对person编码
byte[] personBytes = person.toByteArray();
//将编码后的数据直接merge成Article对象
DifferentModels.Article article = DifferentModels.Article.parseFrom(personBytes);
System.out.println(“article’s title:” + article.getTitle());
System.out.println(“article’s wordsCount:” + article.getWordsCount());
System.out.println(“article’s author:” + article.getAuthor());
}
输出结果如下
article’s title:person name
article’s wordsCount:1
article’s author:tera@google.com
可以看到,虽然jsonBytes是由person对象编码得到的,但是可以用于article对象的解码,不但不会报错,所有的数据内容都是完整保留的
这种兼容性的前提是模型中所定义的字段类型和序号都是一一对应相同的
在平时的编码中,我们经常会遇到从数据库中读取数据模型,然后将其转换成业务模型,而很多时候,这2种模型的内容其实是完全一致的,此时我们也许就可以使用protobuf的这种特性,就可以省去很多低效的赋值代码
2.protobuf序号的重要性
我们看到在定义.proto文件时,字段后面会跟着一个"= X",这里并不是指这个字段的值,而是表示这个字段的“序号”,和正确地编码与解码息息相关,在我看来是protocol buffer的灵魂
我们定义如下的.proto文件,这里注意,Model1和Model2的name和id的序号有不同
syntax = “proto3”;
option java_package = “cn.tera.protobuf.model”;
option java_outer_classname = “TagImportance”;
message Model1 {
string name = 1;
int32 id = 2;
string email = 3;
}
message Model2 {
string name = 2;
int32 id = 1;
string email = 3;
}
定义如下的测试方法
/**
- 序号的重要性测试
- @throws Exception
*/
@Test
public void tagImportanceTest() throws Exception {
TagImportance.Model1 model1 = TagImportance.Model1.newBuilder()
.setEmail(“model1@google.com”)
.setId(1)
.setName(“model1”)
.build();
TagImportance.Model2 model2 = TagImportance.Model2.parseFrom(model1.toByteArray());
System.out.println(“model2 email:” + model2.getEmail());
System.out.println(“model2 id:” + model2.getId());
System.out.println(“model2 name:” + model2.getName());
System.out.println(“-------model2 数据---------”);
System.out.println(model2);
}
输出结果如下
model2 email:model1@google.com
model2 id:0
model2 name:
-------model2 数据---------
email: “model1@google.com”
1: “model1”
2: 1
可以看到,虽然Model1和Model2定义的字段类型和名字都是相同的,然而name和id的序号颠倒了一下,导致最终model2在解析byte数组时,无法正确将数据解析到对应的字段上,所以输出的id为0,而name字段为null
不过即使字段无法一一对应,但在输出model2.toString()时,我们依然可以看到数据是被解析到了,只不过无法对应到具体字段,只能用1,2来表示其字段名
3.protobuf序号对编码结果大小的影响
protobuf的序号不仅影响编码、解码的正确性,一定程度上还会影响编码结果的字节数
我们在上面的.proto文件中增加一个Model3,其中Model3中定义的字段没有变化,但是序号更改为16,17,18
syntax = “proto3”;
option java_package = “cn.tera.protobuf.model”;
option java_outer_classname = “TagImportance”;
message Model1 {
string name = 1;
int32 id = 2;
string email = 3;
}
message Model2 {
string name = 2;
int32 id = 1;
string email = 3;
}
message Model3 {
string name = 16;
int32 id = 17;
string email = 18;
}
测试方法
/**
- 序号对编码大小的影响
- @throws Exception
*/
@Test
public void tagSizeInfluenceTest() throws Exception {
TagImportance.Model1 model1 = TagImportance.Model1.newBuilder()
.setEmail(“model1@google.com”)
.setId(1)
.setName(“model1”)
.build();
System.out.println(“model1 编码大小:” + model1.toByteArray().length);
TagImportance.Model3 model3 = TagImportance.Model3.newBuilder()
.setEmail(“model1@google.com”)
.setId(1)
.setName(“model1”)
.build();
System.out.println(“model3 编码大小:” + model3.toByteArray().length);
}
输出结果如下
model1 编码大小:29
model3 编码大小:32
可以看到,在数据量完全相同的情况下,编号偏大的对象编码的结果也会偏大
4.模型字段数据类型兼容性
之前我在getName()方法中提到了灵活性,接下去就展示一下该特性
我们定义如下的.proto文件
syntax = “proto3”;
option java_package = “cn.tera.protobuf.model”;
option java_outer_classname = “ModelTypeCompatible”;
message OldPerson {
string name = 1;
int32 id = 2;
string email = 3;
}
message NewPerson {
Name name = 1;
int32 id = 2;
string email = 3;
}
message Name {
string first = 1;
string last = 2;
int32 usedYears = 3;
}
其中定义了2个Person对象
在OldPerson中,name是一个纯String
在NewPerson中,name字段则被定义为了一个对象
此时我们做如下的操作
/**
- 模型字段不同类型的兼容性
- @throws Exception
*/
@Test
public void typeCompatibleTest() throws Exception {
ModelTypeCompatible.NewPerson newPerson = ModelTypeCompatible.NewPerson.newBuilder()
.setName(ModelTypeCompatible.Name.newBuilder()
.setFirst(“tera”)
.setLast(“cn”)
.setUsedYears(10)
).setId(5)
.setEmail(“tera@google.com”)
.build();
ModelTypeCompatible.OldPerson oldPerson = ModelTypeCompatible.OldPerson.parseFrom(newPerson.toByteArray());
System.out.println(oldPerson.getName());
}
输出结果如下
tera cn
可以看到,虽然NewPerson的name字段是一个对象,但是却可以被成功地转换成OldPerson的String类型的name字段,虽然其中的usedYears字段被舍弃了
这种兼容性的前提是从对象类型向String类型转换,而反向是不可以的
5.protobuf与json之间的转换和对比
json是现在应用最为广泛的数据结构之一,因此当我们决定使用protobuf时,不可避免的问题就是它和json的兼容性
因此接下去我们看下protobuf和json之间是如何转换的
我们先构造一个简单的java类
public class PersonJson {
public String name;
public int id;
public String email;
}
重复利用之前生成的protobuf模型BasicUsage.Person,以及前文就引入的json相关的maven,我们测试如下方法
/**
- json和protobuf的互相转换
*/
@Test
void jsonToProtobuf() throws Exception {
//构造简单的模型
PersonJson model = new PersonJson();
model.email = “personJson@google.com”;
model.id = 1;
model.name = “personJson”;
String json = JSON.toJSONString(model);
System.out.println(“原始json”);
System.out.println(“------------------------”);
System.out.println(json);
System.out.println();
//parser
JsonFormat.Parser parser = JsonFormat.parser();
//需要build才能转换
BasicUsage.Person.Builder personBuilder = BasicUsage.Person.newBuilder();
//将json字符串转换成protobuf模型,并打印
parser.merge(json, personBuilder);
BasicUsage.Person person = personBuilder.build();
//需要注意的是,protobuf的toString方法并不会自动转换成json,而是以更简单的方式呈现,所以一般没法直接用
System.out.println(“protobuf内容”);
System.out.println(“------------------------”);
System.out.println(person.toString());
//修改protobuf模型中的字段,并再转换会json字符串
person = person.toBuilder().setName(“protobuf”).setId(2).build();
String buftoJson = JsonFormat.printer().print(person);
System.out.println(“protobuf修改过数据后的json”);
System.out.println(“------------------------”);
System.out.println(buftoJson);
}
输出结果如下
原始json
{“email”:“personJson@google.com”,“id”:1,“name”:“personJson”}
protobuf内容
name: “personJson”
id: 1
email: “personJson@google.com”
protobuf修改过数据后的json
{
“name”: “protobuf”,
“id”: 2,
“email”: “personJson@google.com”
}
可以看到json和protobuf是可以做到完全兼容的互相转换
此时我们就可以比较一下,相容的数据内容经过json和protobuf分别编码后的数据字节大小,我们就使用上面的数据内容,做如下的测试
/**
- json和protobuf的编码数据大小
*/
@Test
void codeSizeJsonVsProtobuf() throws Exception {
//构造简单的模型
PersonJson model = new PersonJson();
model.email = “personJson@google.com”;
model.id = 1;
model.name = “personJson”;
String json = JSON.toJSONString(model);
System.out.println(“原始json”);
System.out.println(“------------------------”);
System.out.println(json);
System.out.println(“json编码后的字节数:” + json.getBytes(“utf-8”).length + “\n”);
//parser
JsonFormat.Parser parser = JsonFormat.parser();
//需要build才能转换
BasicUsage.Person.Builder personBuilder = BasicUsage.Person.newBuilder();
//将json字符串转换成protobuf模型,并打印
parser.merge(json, personBuilder);
BasicUsage.Person person = personBuilder.build();
//需要注意的是,protobuf的toString方法并不会自动转换成json,而是以更简单的方式呈现,所以一般没法直接用
System.out.println(“protobuf内容”);
System.out.println(“------------------------”);
System.out.println(person.toString());
System.out.println(“protobuf编码后的字节数:” + person.toByteArray().length);
}
输出内容如下
原始json
{“email”:“personJson@google.com”,“id”:1,“name”:“personJson”}
json编码后的字节数:60
protobuf内容
name: “personJson”
id: 1
email: “personJson@google.com”
protobuf编码后的字节数:37
可以看到,相同的数据内容,protobuf编码的结果是json编码结果的60%左右(当然这个数值是会随着数据内容的不同浮动)
这里先总结一下之前的特性
1.protobuf的解码不需要类型相同,也不需要字段名相同
2.protobuf的解码依赖于序号的正确性
3.protobuf中的序号大小会影响最终编码大小
4.protobuf的对象类型可以向String类型兼容
5.protobuf可以和json完全兼容,且编码大小要比json小
第二部分,Protobuf编码原理
首先,我们需要了解一种最基本的编码方式varints(原文档的单词,没有找到特别准确的翻译,所以就就保留英文),这是一种用1个或多个字节对Integer进行编码的方法
当一个Integer采用这种方式编码后,除了最后一个字节,每一个字节的最高位都是1,而最后一个字节的最高位则是0,从而在解码的时候可以通过判断最高位的值来确定是否已经解码到了最后一个字节。
每一个字节除了最高位的其他7个bit则用来存放数字本身的编码
例如300,编码后得到2个字节,红色表示最高位bit,蓝色表示数字本身编码
1010 1100 0000 0010
其中第一个字节最高位bit为1,表示后面还有字节需要一并进行解码。第二个字节最高位bit为0,则表示已经到达最后一个字节了
解码时
1.去掉2个字节的最高位
010 1100 000 0010
2.反转2个字节的顺序
000 0010 010 1100
3.连接2个字节,构成了300的二进制形式
100101100
接着我们来看一个实际的例子,编码一个Person对象,只给里面的id字段赋值
/**
- varint数字编码
*/
@Test
void varintTest() {
BasicUsage.Person person = BasicUsage.Person.newBuilder()
.setId(91809)
.build();
Utility.printByte(person.toByteArray());
}
输出的编码结果如下
16 -95 -51 5
00010000 10100001 11001101 00000101
其中黄色部分即是91809的varints编码,我们来验证一下
红色表示最高位,蓝色表示数字本身编码,在读取该部分字节的时候是一个一个读取的
读取到第一个字节时,发现最高位是1,因此会继续读取第二个字节,第二个字节最高位也是1,因此继续读取第三个字节,而第三个字节最高位为0,从而结束读取,就处理这3个字节
10100001 11001101 00000101
1.去掉3个字节的最高位
0100001 1001101 0000101
2.反转3个字节的顺序
0000101 1001101 0100001
3.连接3个字节,构成了91809的二进制形式
10110011010100001
接着我们看person编码结果的第一个字节
16 -95 -51 5
00010000 10100001 11001101 00000101
这个字节表示的是数据的序号和类型,编码方式也是varient,因此我将其分为3个部分
00010000
红色0为最高位bit,表示是否解析到了本次varient的最后一个字节
中间蓝色的4个bit 0010表示序号,十进制2,即id的序号
最后3个黄色底的0为该字段的类型,000表示int32类型
此时一个最简单的protobuf的编码就解析完成了
到这里我们先总结一下protobuf编码的性质,将特别抽象的的内容转换成一个我们可以直觉理解的东西
先看原始数据,如果用json表示出来就是如下形式
{
“id”: 91890
}
而protobuf编码后的数据格式如下
00010000 10100001 11001101 00000101
其中第一个字节表示序号和字段类型,即序号为2,类型为int的字段
后三个字节表示数据的值,值为91890
这时候就会有这样一个问题,那id这个字段名去哪儿了?
答案就是,id的字段名被protobuf舍弃了!
所以,protobuf最终的编码结果是抛弃了所有的字段名,仅仅保留了字段的序号、类型和数据的值。
因此在第一篇文章的开头,就提到protobuf并非是一种可以完全自解释的编码格式,意思就是如此。
也正因为如此,所以我也认为这个序号正是protobuf编码的灵魂所在
有了这个概念之后,我们就可以解释之前5个示例了
***示例1:***protobuf的解码不需要类型相同,也不需要字段名相同
因为protobuf编码后的结果根本就不包含类的信息,也不包含字段名的信息,因此解码的时候自然也就不依赖于类和字段名
***示例2:***protobuf的解码依赖于序号的正确性
因为编码后的结果的序号和类型是在同一个字节中,是一一对应的关系,如果编码的对应关系和解码的对应关系不同,则自然编码和解码的过程会出问题
***示例3:***protobuf中的序号大小会影响最终编码大小
我们前面看到序号和字段类型的字节结构如下,表示序号的部分是中间的4个bit,0010
00010000
而4个bit所能表示的最大数是1111,也就是15,因此当序号大于15的时候,一个字节就不够表达了,就需要额外一个字节,例如序号为17,类型为int的字段,它的序号字节就会如下
10001000 00000001
其中黄色底的000表示类型Int,去除后,剩下的bit通过标准的varient解码后,得到的结果就是17
因此,如果序号超过15,那么就会多需要一个字节来表示序号。回过头看示例3,model3编码结果正好比model1编码结果多3个字节,正是3个字段的序号导致的
***示例4:***protobuf的对象类型可以向String类型兼容
上面提到了int的类型在字节中的bit表示是000,那么接下去我么可以看下其他类型对应的bit表示
| Type | Meaning | Used For |
|---|---|---|
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | fixed64, sfixed64, double |
| 2 | Length-delimited | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | groups (deprecated) |
| 4 | End group | groups (deprecated) |
| 5 | 32-bit | fixed32, sfixed32, float |
这里可以看到,0就是表示int32,表达方式是varient
而2则可以表示string、embedded messages等,而这里的embedded messages对应的就是子对象
既然类型的表示是相同的,那么在解码的时候自然就是可以从embeedded messages向string兼容
然而由于messages的结构是要比string复杂的,因此反向是无法兼容的
其实这个更广域和普世来说,总是复杂信息可以向简单信息转换,而反向一般是不可行的
**示例5:**protobuf可以和json完全兼容,且编码大小要比json小
兼容性是由java类库实现的,这个不在编码原理的范畴内,这里主要看下编码大小比json小的原因
例如示例中的json
{“email”:“personJson@google.com”,“id”:1,“name”:“personJson”}
json的编码后,为了保证格式的正确和自解释的功能,其中还包含了很多格式字符,包括{ " , }等,还包括了email、id、name字段名本身
而protobuf编码后,则仅仅保留了序号、类型,以及字段的值,没有任何其他额外的符号,因此就比json节省了很多字节数
最后总结下这一大部分的内容,通过5个示例展示了protobuf在使用上的一些特性,并通过基本的编码原理解释了特性的本质原因
特性有以下5点
1.protobuf的解码不需要类型相同,也不需要字段名相同
2.protobuf的解码依赖于序号的正确性
3.protobuf中的序号大小会影响最终编码大小
4.protobuf的对象类型可以向String类型兼容
5.protobuf可以和json完全兼容,且编码大小要比json小
我们通过一些示例了解了protobuf的使用特性,以及和这些特性相关的基础编码原理。
编码原理只开了个头,所以接着将继续展示protobuf剩余的编码原理
在之前,我们只是定义了一些非常简单的模型,其中只包含了string、int和一个Name对象,所以我们首先先定义一个更复杂的模型
.proto文件如下
syntax = “proto3”;
option java_package = “cn.tera.protobuf.model”;
option java_outer_classname = “ProtobufStudent”;
message Student{
int32 age = 1;
int64 hairCount = 2;
bool isMale = 3;
string name = 4;
double height = 5;
float weight = 6;
Parent father = 7;
Parent mother = 8;
repeated string friends = 9;
repeated Hobby hobbies = 10;
Color hairColor = 11;
bytes scores = 12;
uint32 uage = 13;
sint32 sage = 14;
}
message Parent {
string name = 1;
int32 age = 2;
}
message Hobby {
string name = 1;
int32 cost = 2;
}
enum Color {
BLACK = 0;
RED = 1;
YELLOW = 2;
}
相比之前定义的模型,这里新增了int64,bool,double,float,repeated,enum,uint,sint类型
repeated类型对应的是java中的list
protobuf将这些具体的类型分为了几个大类,如下面这个表格所示
| Type | Meaning | Used For |
|---|---|---|
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | fixed64, sfixed64, double |
| 2 | Length-delimited | string, bytes, embedded messages, packed repeated fields |
| 5 | 32-bit | fixed32, sfixed32, float |
接着我们就通过实例来看下每种数据结构的编码方式
1.Varint
这种类型的数据,在序号字节中的类型部分表示为000,即表格中的Type字段0
首先我们看最简单的4种类型,protobuf类型为int32、int64、bool、enum,模型中对应这种类型的字段是age、hairCount、isMale、hairColor,因此我们分别给这4个字段赋值
age测试代码
/**
- protobuf基础编码,varint类型
*/
@Test
void protobufBaseEncodeTest() {
ProtobufStudent.Student student = ProtobufStudent.Student.newBuilder()
.setAge(15)
Utility.printByte(student.toByteArray());
}
输出结果
8 15
00001000 00001111
这里复习一下之前中关于protobuf的编码基础
第一个字节表示字段的序号和类型
黄色底000,表示该数据类型是varint
蓝色0001,表示序号为1
红色0,表示序号解析到了最后一个字节
第二个字节表示数字的值15
通过varint解码后,即是15
hairCount测试代码
@Test
void protobufBaseEncodeTest() {
ProtobufStudent.Student student = ProtobufStudent.Student.newBuilder()
.setHairCount(239281373231123L)
.build();
Utility.printByte(student.toByteArray());
}
输出结果
16 -109 -16 -126 -54 -128 -76 54
00010000 10010011 11110000 10000010 11001010 10000000 10110100 00110110
第一个字节表示字段的序号和类型
黄色底000,表示该数据类型是varint
蓝色0010,表示序号为2
红色0,表示序号解析到了最后一个字节
后面7个字节,通过varint解码后,即是239281373231123L
isMale测试代码
@Test
void protobufBaseEncodeTest() {
ProtobufStudent.Student student = ProtobufStudent.Student.newBuilder()
.setIsMale(true)
.build();
Utility.printByte(student.toByteArray());
}
输出结果
24 1
00011000 00000001
序号字节结构和之前一样
这里因为赋值的是true,所以值是1,如果赋值是false的话,那么该字段就不会被编码了(因为bool类型默认就是false)
hairColor测试代码
@Test
void protobufBaseEncodeTest() {
ProtobufStudent.Student student = ProtobufStudent.Student.newBuilder()
.setHairColor(ProtobufStudent.Color.RED)
.build();
Utility.printByte(student.toByteArray());
}
输出结果
88 1
01011000 00000001
序号字节结构和之前一样,这里因为赋值的是Color.RED,我们查看枚举值表即为1,如果赋值的是Color.BLACK,则该字段将不会被编码(因为int类型默认值就是0)
上面4个例子是可以通过正数就可以表达的类型,接着我们看对于有符号的正数,protobuf是如何表达的
protobuf类型为int32、uint32、sint32,对应模型中的age、uage、sage**(这里注意,虽然在.proto文件中我们分了3个类型进行定义,但最终映射到java的类型都是int)**
负数age测试代码
/**
- protobuf基础编码,有符号的整数
*/
@Test
void negativeIntTest() {
ProtobufStudent.Student student = ProtobufStudent.Student.newBuilder()
.setAge(-7)
.build();
Utility.printByte(student.toByteArray());
}
输出结果
8 -1 -1 -1 -1 -1 -1 -1 -1 -1 1
00001000 11111001 11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111 00000001
可以看到数据体占用了10个字节,通过varint解码后就可以得到-7
因为一般负数的二进制结果都是采用正数补码的形式存储,所以protobuf使用了一个长度固定为10个字节的空间对负数进行编码,即使是-7也需要10个字节进行存储,其实是十分不合理的,因此我们看下uint和sint的表现
uage测试代码
/**
- protobuf基础编码,有符号的整数
*/
@Test
void negativeIntTest() {
ProtobufStudent.Student student = ProtobufStudent.Student.newBuilder()
.setUage(-7)
.build();
Utility.printByte(student.toByteArray());
}
输出结果
104 -1 -1 -1 -1 15
01101000 11111001 11111111 11111111 11111111 00001111
如果定义为uint32的话,那么固定的数据存储空间则会缩减为5个字节
sage测试代码
/**
- protobuf基础编码,有符号的整数
*/
@Test
void negativeIntTest() {
ProtobufStudent.Student student = ProtobufStudent.Student.newBuilder()
.setSage(-7)
.build();
Utility.printByte(student.toByteArray());
}
输出结果
112 13
01110000 00001101
粗看一下还不错,至少是用一个字节就表示了,但是仔细观察就会发现,我们传入的数字明明是-7,但是编码结果却是13
原因在于如果我们定义的是sint32,那么protobuf会采用一种叫做ZigZag的编码方式,即一种数据的映射,表格如下
| Signed Original | Encoded As |
|---|---|
| 0 | 0 |
| -1 | 1 |
| 1 | 2 |
| -2 | 3 |
| 2 | 4 |
| … | … |
即设需要编码的整数为n:如果n>=0,则映射为2n;如果n<0,则映射为-2n-1
用代码来表示的话:
对于int32类型,映射规则为
(n << 1) ^ (n >> 31)
对于int64类型,映射规则为
(n << 1) ^ (n >> 63)
映射之后,再将映射的值通过varint的方式编码成字节
回过头看-7,对应的映射正是13,因此编码结果中也就是13
当然采取这种ZigZag进行映射后,对于负数编码所需的空间会减少,但对于正数的编码结果则会多出1个bit(看一下映射规则,如果n>=0,则映射为2n)
因此综上测试结果,如果我们能够预知在使用的过程中会遇到负数,那么从编码结果字节数的角度来说,采用sint定义.proto的字段将会是一个更优的选择
这里总结一下Varint的编码方式,首先由一个序号字节标识字段的序号和类型,数据体无论是int、long、bool、enum,因为其最终总能用一个数字表示,因此他们都能统一地通过varint进行编码,所以这种数据类型的分类就叫Varint
对于正数来说,直接通过varint编码即可
而对于负数来说,int会采用固定的10个字节对补码进行varint编码,uint会采用固定的5个字节对补码进行varint编码,而sint则是采用ZigZag的映射将负数映射成一个正数后再进行varint编码
顺带一提,在进行varint解码的时候,我们会发现它是需要将字节顺序反转之后才能解析出我们需要的数字(这里详解见protobuf的使用特性及编码原理),而这种反转存放的形式正是小端存储,即little-endian,这部分有兴趣的同学可以自己再去了解一下
2.64-bit和32-bit
这里我将64bit和32bit放到一起,因为他们之间的编码区别仅在于最终字节数量的不同,而编码原理是一样的
这两种类型的数据,在序号字节中的类型部分表示为001和101,即表格中的Type字段0和5
模型中对应这种类型的字段是height、weight因此我们分别给这2个字段赋值
height测试代码
/**
- protobuf基础编码,double和float类型
*/
@Test
void protobufBaseEncodeTestDoubleAndFloat() {
ProtobufStudent.Student student = ProtobufStudent.Student.newBuilder()
.setHeight(99.6)
.build();
Utility.printByte(student.toByteArray());
}
输出结果
41 102 102 102 102 102 -26 88 64
00101001 01100110 01100110 01100110 01100110 01100110 11100110 01011000 01000000
第一个字节表示字段的序号和类型
黄色底001,即十进制的1,表示该数据类型64-bit
蓝色0101,表示序号为5
红色0,表示序号解析到了最后一个字节
后续的8个字节正是99.6的二进制表达形式,protobuf采用的标准是IEEE754。不过因为该标准的内容比较复杂,可以单独成文,所以就不放在这里展开了,本文还是专注于protobuf本身。
这里提供两个网址
维基百科:https://zh.wikipedia.org/wiki/IEEE_754
线上转换:http://www.binaryconvert.com/result_double.html
我们进入线上转换站点,输入99.6,得到结果

和varint类型数据的存储方式一样,这里采用的也是小端存储(little-endian),因此将图中的字节反转之后,即可得到我们前面代码输出的内容
weight测试代码
/**
- protobuf基础编码,double和float类型
*/
@Test
void protobufBaseEncodeTestDoubleAndFloat() {
ProtobufStudent.Student student = ProtobufStudent.Student.newBuilder()
.setWeight(99.6F)
.build();
Utility.printByte(student.toByteArray());
}
输出结果
53 51 51 -57 66
00110101 00110011 00110011 11000111 01000010


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
进制的1,表示该数据类型64-bit
蓝色0101,表示序号为5
红色0,表示序号解析到了最后一个字节
后续的8个字节正是99.6的二进制表达形式,protobuf采用的标准是IEEE754。不过因为该标准的内容比较复杂,可以单独成文,所以就不放在这里展开了,本文还是专注于protobuf本身。
这里提供两个网址
维基百科:https://zh.wikipedia.org/wiki/IEEE_754
线上转换:http://www.binaryconvert.com/result_double.html
我们进入线上转换站点,输入99.6,得到结果
[外链图片转存中…(img-q9fA6RCl-1715837535959)]
和varint类型数据的存储方式一样,这里采用的也是小端存储(little-endian),因此将图中的字节反转之后,即可得到我们前面代码输出的内容
weight测试代码
/**
- protobuf基础编码,double和float类型
*/
@Test
void protobufBaseEncodeTestDoubleAndFloat() {
ProtobufStudent.Student student = ProtobufStudent.Student.newBuilder()
.setWeight(99.6F)
.build();
Utility.printByte(student.toByteArray());
}
输出结果
53 51 51 -57 66
00110101 00110011 00110011 11000111 01000010
[外链图片转存中…(img-pImfbxJe-1715837535959)]
[外链图片转存中…(img-3NObFLkD-1715837535959)]
[外链图片转存中…(img-v1LNBMvR-1715837535960)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









