







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
在现如今的NLP竞赛中,信息抽取(IE)任务已占据半壁江山。来,让我们看看今年的一些IE竞赛都有啥:

看到如此众多的IE竞赛,心动的JayJay抽空参加了CHIP2020(中国健康信息处理大会)中的3个评测,最终获得了2个冠军、1个季军,具体如下表所示:
| 评测任务名称 | 所获名次 | 评测网址 |
|---|---|---|
| 中文医学实体关系抽取 | 第一 | http://cips-chip.org.cn/2020/eval2 |
| 临床医学术语标准化 | 第一 | http://cips-chip.org.cn/2020/eval3 |
| 中文医学嵌套实体抽取 | 第三(a榜第一) | http://cips-chip.org.cn/2020/eval1 |
本次CHIP2020也吸引了众多国内外一流团队的参加,比如阿里达摩院、腾讯天衍实验室、平安科技、云知声、北大、清华、中科院、纽约大学等,竞争也是异常激烈~此外,也许你会问:为什么选择参加上述三个评测?医疗NLPer一定会知道,「实体抽取+关系抽取+术语归一」正好是医疗数据解析的三个必不可少的重要环节。
本篇文章,JayJay并不想只是围绕竞赛本身谈策略,而是想和大家一起交流:无论在竞赛还是落地中,信息抽取任务的稳定提升策略有哪些?总的来看就是两点:
- 构建一个强大的baseline,这取决于标注框架的选择;
- 套路化的辅助策略,稳定迭代并提升;
为更好地展示关键内容,本文以QA形式探讨了以下问题: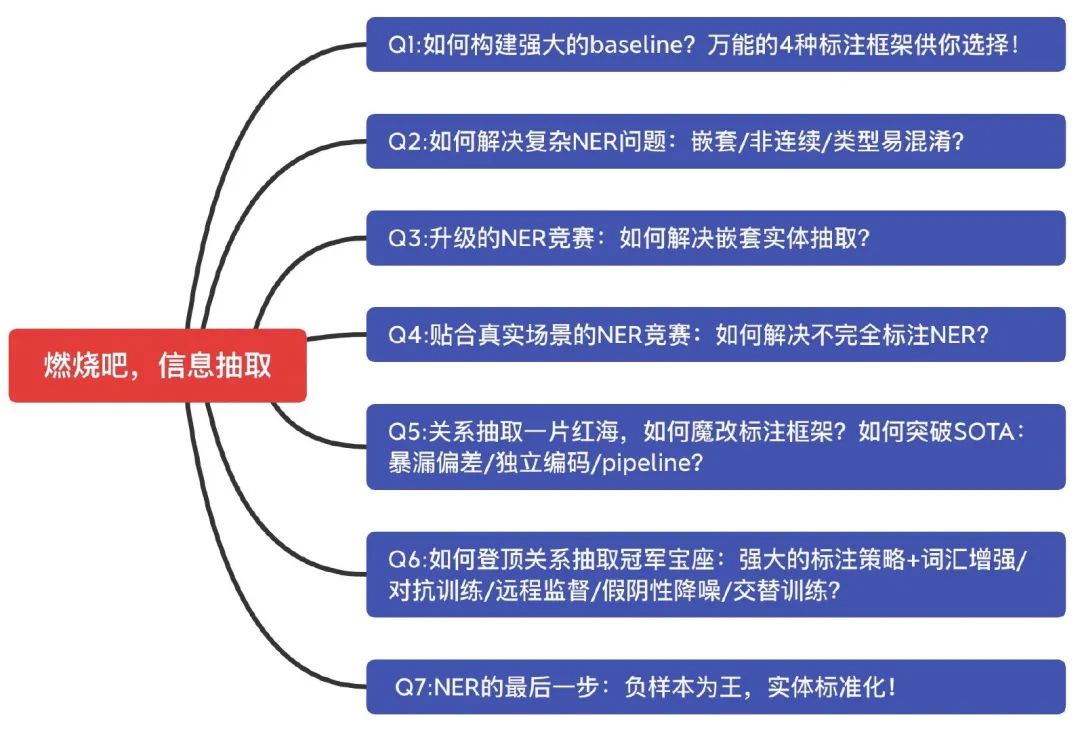
相关代码后续会在(https://github.com/loujie0822/DeepIE)开源,尽情关注~
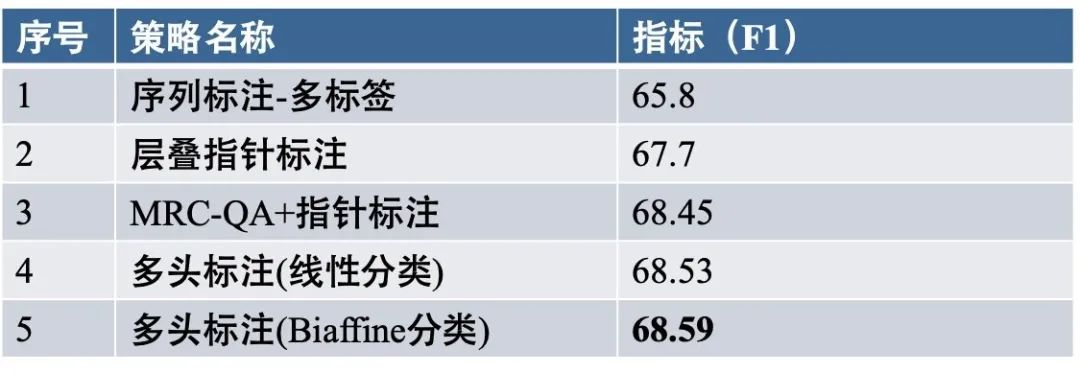
Q1:如何构建强大的baseline?万能的4种标注框架供你选择!
谈到标注框架,NLPer首先想到的就是序列标注,而如今我们面临早已不是一个简单抽取问题,序列标注已经无法“胜任”了:例如,在医疗抽取任务中,我们常常会遇到嵌套、非连续、类型混淆、信息块重叠、关系重叠等复杂抽取问题。
因此,掌握标注框架(解码方式)是解决信息抽取问题的第一步,也是构建强大baseline的关键一步:试想一下,如果你的标注框架都不能完备解码(gold输入,输出指标也应该达到或接近100%),不能cover绝大部分case情况,又何谈下一步优化提升呢?
JayJay这里归纳了4种“易于上手”的标注框架:
-
序列标注:每个序列位置都被标注为一个标签,比如按照BILOU标注,我们常用MLP或CRF解码。
-
指针标注:对每个span的start和end进行标记,对于多片段抽取问题转化为N个2分类(N为序列长度),如果涉及多类别可以转化为层叠式指针标注(C个指针网络,C为类别总数)。事实上,指针标注已经成为统一实体、关系、事件抽取的一个“大杀器”。
-
多头标注:对每个token pair进行标记,其实就是构建一个
-
的分类矩阵,可以用于实体或关系抽取。其重点就是如何强有力的表征构建分类矩阵。事实上,多头标注成为了众多实体和关系抽取SOTA的首选利器!(PS:多头标注是JayJay自己叫的,单纯是为了纪念多头选择机制的关系抽取论文[1])
-
片段排列:源于Span-level NER[2]的思想,枚举所有可能的span进行分类,同序列长度进行解耦,可以更加灵活地处理复杂抽取和低资源问题。事实上,片段排列的思想已经被Google推崇[3]并统一了信息抽取各个子任务。
掌握上述4种标注框架后,我们就可以根据具体抽取任务、灵活地应用于实体、关系、事件抽取等场景中了(PS:对于一些生成式的标注框架,JayJay感觉不够稳定,就不再单独介绍了)。
Q2:如何解决复杂NER问题:嵌套/非连续/类型易混淆?
在实际业务场景中的NER问题可能与你想的不太一样,比如下图中的复杂NER问题你遇到过吗?
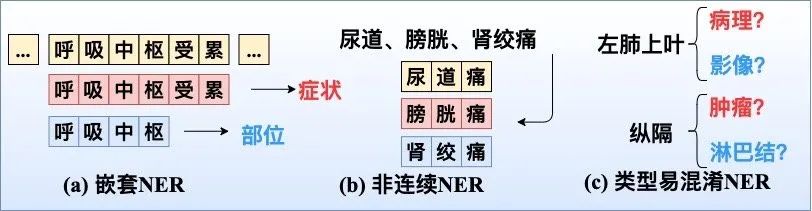
本文这里给出了上述复杂NER问题的简单解决方案:
-
嵌套NER:例如在span「呼吸中枢受累」中,存在两个实体嵌套:「症状:呼吸中枢受累」和「部位:呼吸中枢」。我们在Q3中具体介绍解决方案。
-
非连续NER:例如在span「尿道、膀胱、肾绞痛」中存在三个非连续实体「尿道痛」、「膀胱痛」、「肾绞痛」。这里给出3种解决方案:
- 继续当作序列标注任务:拓展BIO标签;
- 转化为一个属性/关系抽取问题:由于病历文本趋向模板化,所以用规则提取更加便捷。
- 模仿句法解析器的做法,设置shift-reduce parser,具体可参见ACL20的这篇paper[4]。
-
类型易混淆NER:例如对于部位实体「左肺上叶」,其归属于「病理」还是「影像」模块呢?对于「纵隔」部位,是属于「肿瘤」还是「淋巴结」部位呢?这里给出2种解决方案:
- 事件论元抽取:对于医疗领域,不同于通常的论元抽取,因为电子病历一般不存在信息块重叠(事件类型交叉重叠)问题,因此可以先进行事件段落抽取,再将「左肺上叶」部位实体归属到当前的事件段落中。
- 两阶段NER:在同一事件类型中,第一阶段可以确定实体span边界(例如找到部位实体「纵隔」的边界),第二阶段再结合上下文信息进行实体typing(例如对「纵隔」进行性质判断),这样做指标通常会提高哦~
Q3:升级的NER竞赛:如何解决嵌套实体抽取?
既然实际业务中的NER问题是复杂的,NER竞赛也不应该循规蹈矩了~这不,CHIP2020的中文医学实体抽取评测就是一个嵌套实体抽取问题,数据集包含504种常见的儿科疾病、7,085种身体部位、12,907种临床表现等九大类医学实体。
对于嵌套实体抽取这个任务,我们直接套用Q1中的4种万能标注框架就可以解决了:
-
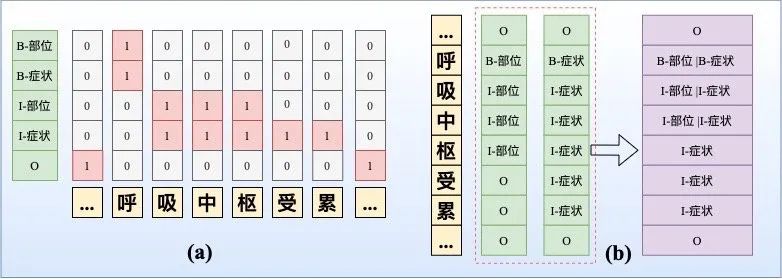
序列标注:
- 多标签分类。如下图(a)所示,将多分类转化为多标签分类,即使用sigmoid设定阈值进行解码;这种方式的学习难度较大,也会容易导致label之间依赖关系的缺失;
- 合并标签层。如下图(b)所示,依然采用CRF,但设置多个标签层,对于每一个token给出其所有的label,然后将所有标签层合并。这种方式指数级增加了标签,对于多层嵌套,稀疏问题较为棘手;
-
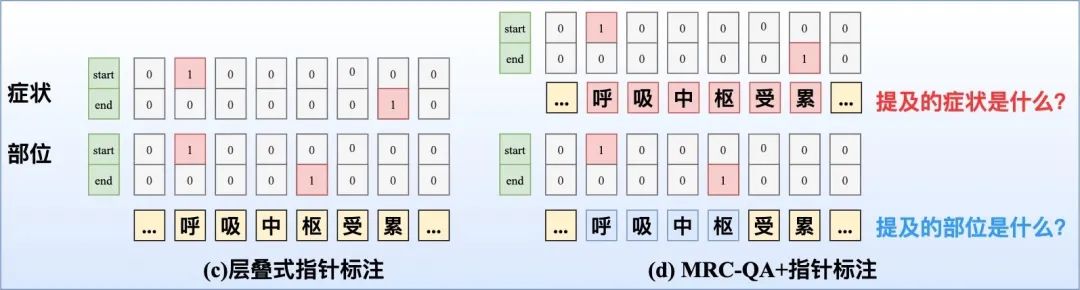
指针标注:
- 层叠式指针标注:即设置C个指针网络,如下图(c)所示。
- MRC-QA+指针标注:构建query问题指代所要抽取的实体类型,同时也引入了先验语义知识,如下图(d)所示。在文献[5]中就对不同实体类型构建query,并采取指针标注,此外也构建了
-
- 矩阵来判断span是否构成一个实体metion。
-
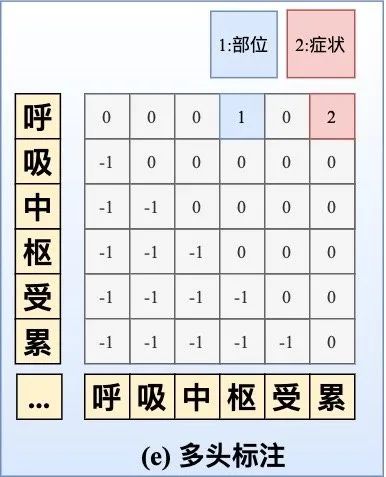
多头标注
- 构建一个
-
- 的Span矩阵,如下图(e)所示,Span{呼}{枢}=1,代表「呼吸中枢」是一个部位实体;Span{呼}{累}=2,代表「呼吸中枢」是一个症状实体;对于多头标注的一个重点就是如何构造Span矩阵、以及解决0-1标签稀疏问题。
- 嵌套实体的2篇SOTA之作:ACL20的《Named Entity Recognition as Dependency Parsing》采取Biaffine机制构造Span矩阵;EMNLP20的HIT[6]则通过Biaffine机制专门捕获边界信息,并采取传统的序列标注任务强化嵌套结构的内部信息交互,同时采取focal loss来解决0-1标签不平衡问题。
- 的Span矩阵,如下图(e)所示,Span{呼}{枢}=1,代表「呼吸中枢」是一个部位实体;Span{呼}{累}=2,代表「呼吸中枢」是一个症状实体;对于多头标注的一个重点就是如何构造Span矩阵、以及解决0-1标签稀疏问题。
-
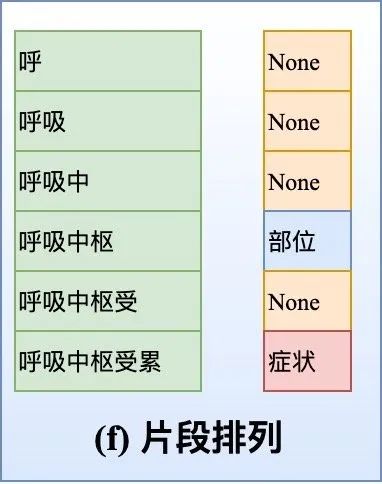
片段排列
- 十分直接,如下图(f)所示。对于含T个token的文本,理论上共有
-
- 种片段排列。如果文本过长,会产生大量的负样本,在实际中需要限制span长度并合理削减负样本。
在CHIP20嵌套实体评测中,我们对比了不同标注策略下的效果(如下图),可以发现:多头标注效果最佳!
Q4:贴合真实场景的NER竞赛:如何解决不完全标注NER?
标注资源少、如何降低标注量一直是真实工业场景中必须面对的问题,不同于分类任务,大规模的实体标注数据集的构建成本更高。BERT的出现本身就是一种降低标注量的方式,此外,文本增强等方式也可降低标注(PS:NER等序列标注任务的数据增强方式可能要独立适配会更好,采用常见的增强方式效果提升不明显~)。
那么,有没有一种仅仅通过积累的实体词典、来匹配标注数据的方式,这样可以不用大规模的进行人工标注了。这种方式,可以统称为「不完全标注NER问题」:这种方式最为突出一点就是漏标情况严重,而NER序列标注的方式对噪声(漏标)十分敏感。(事实上,人工标注中也会存在漏标等情况)
CHIP20的评测六-中药说明书实体识别挑战(http://cips-chip.org.cn/2020/eval6)就是对这一问题的评测。由于这个评测正在答辩环节中,JayJay也进入最后答辩了,具体方案等成绩揭晓后再与大家分享吧~下面,我们来看看学术界都有哪些解决方案:
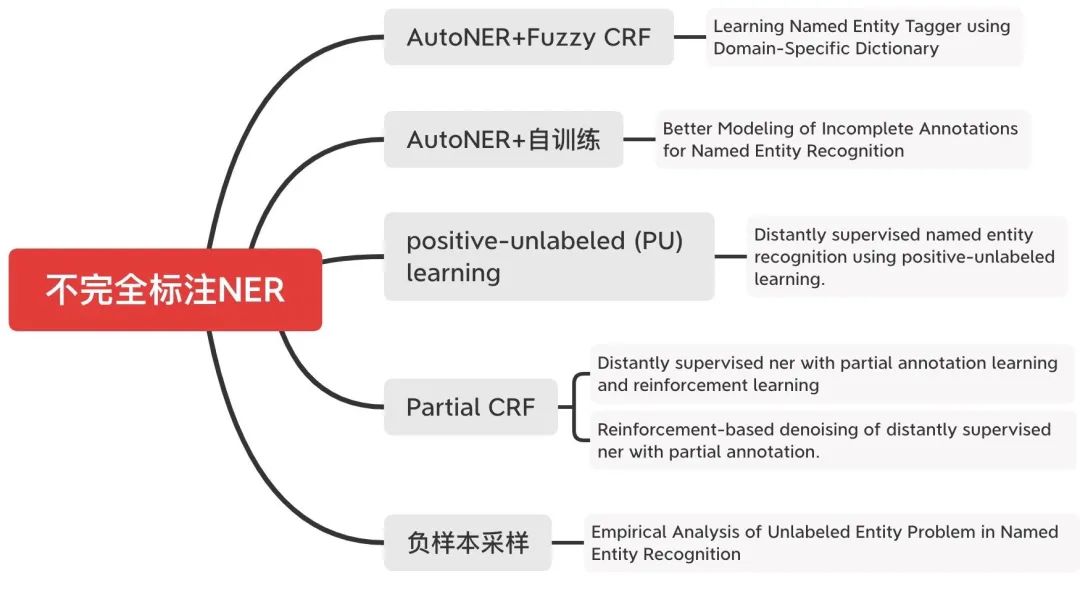
需要特别介绍的是一篇来自ICLR2021投稿的《Empirical Analysis of Unlabeled Entity Problem in Named Entity Recognition》,就是采用我们上述提到的「片段排列」标注方式,摒弃传统的CRF序列标注、与序列长度解耦,转化为一个对span的分类问题,这样更适合对负样本实体的采样;这样模型建模不会像对序列标注中的漏标过于敏感,也更好控制。
Q5:关系抽取一片红海,如何魔改标注框架?如何突破SOTA:暴漏偏差/独立编码/pipeline?
2020年以来,关系抽取SOTA就换了好几个,JayJay常常感叹:关系抽取也太卷了吧~不过仔细阅读后,发现这些SOTA其实绝大多数还是围绕“标注框架”进行魔改,只要我们掌握Q1中提到的4种万能标注,登顶SOTA也不是不可能!
本文所提到的「关系抽取」就是实体关系抽取,不同于「关系分类」。
关系抽取范式主要有两大类:
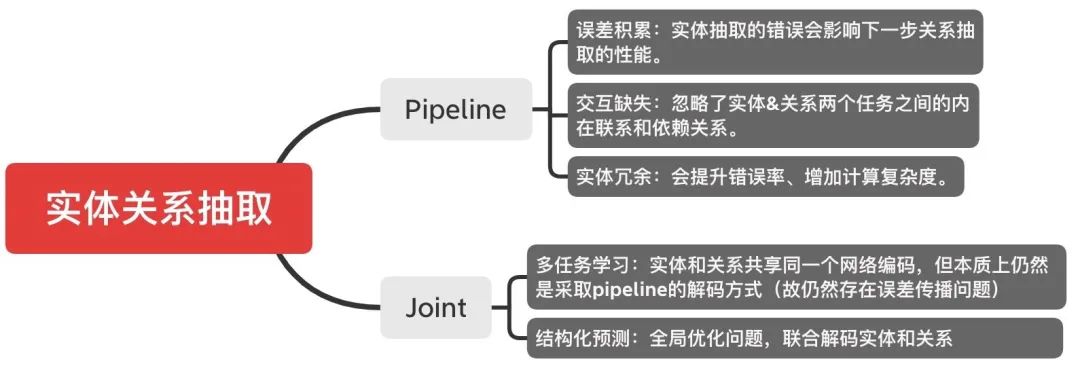
JayJay也有一段时间痴迷于各种联合抽取的joint魔改模型,如果大家有兴趣可以在知乎上直接搜索阅读JayJay的这篇文章《nlp中的实体关系抽取方法总结》。由于篇幅限制,这里简单给出一个总结图:

结合上图,我们可以发现未来突破SOTA的方向可能是:
- 打破Joint好于Pipeline的刻板印象:Pipeline是否一定就好于Joint,我们不能一概而论,特别是看过“女神的新SOTA”上一篇推文《陈丹琦“简单到令人沮丧”的屠榜之作:关系抽取新SOTA!》之后。
- 共享编码可能过于直接了:使用单独的编码器确实可以学习独立的特定任务特征,对于实体和关系确实需要特定的特征编码,在构建joint模型时如果只是简单的强行共享编码,真的可能会适得其反。这表明:针对一项任务提取的特征可能与针对另一项任务提取的特征一致或冲突,从而使学习模型混乱。所以,接下来怎么更好地去设计既可以共享、又可以任务独立的特征吧。
- 解决暴漏偏差,迫在眉睫:最近COLING2020的一篇paper[7]为了缓解这个问题,提出了一种单阶段的联合提取模型TPLinker,其不包含任何相互依赖的抽取步骤,因此避免了在训练时依赖于gold的情况,从而实现了训练和测试的一致性。
Q6:如何登顶关系抽取冠军宝座:强大的标注策略+词汇增强/对抗训练/远程监督/假阴性降噪/交替训练?
废话不说,下面直接来介绍CHIP20中的关系抽取评测。这个评测任务来源于中文医学信息抽取数据集CMeIE(http://cmekg.pcl.ac.cn/),是目前最大的中文医学关系数据集,共包含近7.5万三元组数据,2.8万疾病语句和53种定义好的schema,共44种关系,如下图所示(图片来自于腾讯天衍实验室):

这个关系评测任务是一个SPO抽取问题:

看到这个任务介绍后,如何快速构建强大的baseline呢?可以直接套用Q1给出的4种通用框架:
策略1:基于主语感知的层叠式指针网络(指针标注),抽取过程:先抽取主语subject,再抽取谓语predicate和宾语object,主要参考自ACL20的CasRel[8],JayJay做了以下几点改进(网络架构如下图所示):
- 没有随机选择主语(subject),⽽是遍历所有不同主语的标注样本构建训练集。
- 对subject的感知表征,引入conditional LayerNorm进⾏。
- 对于医疗⽂本中,中英⽂和特殊标点同时出现的特殊情况,改进bert的分词器,以更好提取英⽂专有名词等。

策略2:多头选择机制(多头标注),是基于文献[9]的改进,最重要的就是关系分类器的构造,即是实体pair的一个线性分类器,每个实体pair只选取当前实体span的最后⼀个字符进⾏关系预测,如下图:

关系分类器通过构建
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
99932)]
[外链图片转存中…(img-ExszZk3K-1715628199933)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 518
518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









