







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
pd.DataFrame(data)
| | a | b | c |
| --- | --- | --- | --- |
| 0 | 1.0 | 1 | NaN |
| 1 | NaN | 3 | 4.0 |
**4、通过Numpy二维数组创建**
data = np.random.randint(10, size=(3, 2))
data
array([[1, 6],
[2, 9],
[4, 0]])
pd.DataFrame(data, columns=[“foo”, “bar”], index=[“a”, “b”, “c”])
| | foo | bar |
| --- | --- | --- |
| a | 1 | 6 |
| b | 2 | 9 |
| c | 4 | 0 |
### 11.2 DataFrame性质
**1、属性**
data = pd.DataFrame({“pop”: population, “GDP”: GDP})
data
| | pop | GDP |
| --- | --- | --- |
| BeiJing | 2154 | 30320 |
| ShangHai | 2424 | 32680 |
| ShenZhen | 1303 | 24222 |
| HangZhou | 981 | 13468 |
**(1)df.values 返回numpy数组表示的数据**
data.values
array([[ 2154, 30320],
[ 2424, 32680],
[ 1303, 24222],
[ 981, 13468]], dtype=int64)
**(2)df.index 返回行索引**
data.index
Index([‘BeiJing’, ‘ShangHai’, ‘ShenZhen’, ‘HangZhou’], dtype=‘object’)
**(3)df.columns 返回列索引**
data.columns
Index([‘pop’, ‘GDP’], dtype=‘object’)
**(4)df.shape 形状**
data.shape
(4, 2)
**(5) pd.size 大小**
data.size
8
**(6)pd.dtypes 返回每列数据类型**
data.dtypes
pop int64
GDP int64
dtype: object
**2、索引**
data
| | pop | GDP |
| --- | --- | --- |
| BeiJing | 2154 | 30320 |
| ShangHai | 2424 | 32680 |
| ShenZhen | 1303 | 24222 |
| HangZhou | 981 | 13468 |
**(1)获取列**
* 字典式
data[“pop”]
BeiJing 2154
ShangHai 2424
ShenZhen 1303
HangZhou 981
Name: pop, dtype: int64
data[[“GDP”, “pop”]]
| | GDP | pop |
| --- | --- | --- |
| BeiJing | 30320 | 2154 |
| ShangHai | 32680 | 2424 |
| ShenZhen | 24222 | 1303 |
| HangZhou | 13468 | 981 |
* 对象属性式
data.GDP
BeiJing 30320
ShangHai 32680
ShenZhen 24222
HangZhou 13468
Name: GDP, dtype: int64
**(2)获取行**
* 绝对索引 df.loc
data.loc[“BeiJing”]
pop 2154
GDP 30320
Name: BeiJing, dtype: int64
data.loc[[“BeiJing”, “HangZhou”]]
| | pop | GDP |
| --- | --- | --- |
| BeiJing | 2154 | 30320 |
| HangZhou | 981 | 13468 |
* 相对索引 df.iloc
data
| | pop | GDP |
| --- | --- | --- |
| BeiJing | 2154 | 30320 |
| ShangHai | 2424 | 32680 |
| ShenZhen | 1303 | 24222 |
| HangZhou | 981 | 13468 |
data.iloc[0]
pop 2154
GDP 30320
Name: BeiJing, dtype: int64
data.iloc[[1, 3]]
| | pop | GDP |
| --- | --- | --- |
| ShangHai | 2424 | 32680 |
| HangZhou | 981 | 13468 |
**(3)获取标量**
data
| | pop | GDP |
| --- | --- | --- |
| BeiJing | 2154 | 30320 |
| ShangHai | 2424 | 32680 |
| ShenZhen | 1303 | 24222 |
| HangZhou | 981 | 13468 |
data.loc[“BeiJing”, “GDP”]
30320
data.iloc[0, 1]
30320
data.values[0][1]
30320
**(4)Series对象的索引**
type(data.GDP)
pandas.core.series.Series
GDP
BeiJing 30320
ShangHai 32680
ShenZhen 24222
HangZhou 13468
dtype: int64
GDP[“BeiJing”]
30320
**3、切片**
dates = pd.date_range(start=‘2019-01-01’, periods=6)
dates
DatetimeIndex([‘2019-01-01’, ‘2019-01-02’, ‘2019-01-03’, ‘2019-01-04’,
‘2019-01-05’, ‘2019-01-06’],
dtype=‘datetime64[ns]’, freq=‘D’)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=[“A”, “B”, “C”, “D”])
df
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2019-01-01 | -0.935378 | -0.190742 | 0.925984 | -0.818969 |
| 2019-01-02 | -0.234414 | -1.194674 | 1.080779 | -2.294395 |
| 2019-01-03 | -0.141572 | 0.058118 | 1.102248 | 1.207726 |
| 2019-01-04 | 0.305088 | 0.535920 | -0.978434 | 0.177251 |
| 2019-01-05 | 0.313383 | 0.234041 | 0.163155 | -0.296649 |
| 2019-01-06 | 0.250613 | -0.904400 | -0.858240 | -1.573342 |
**(1)行切片**
df[“2019-01-01”: “2019-01-03”]
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2019-01-01 | -0.935378 | -0.190742 | 0.925984 | -0.818969 |
| 2019-01-02 | -0.234414 | -1.194674 | 1.080779 | -2.294395 |
| 2019-01-03 | -0.141572 | 0.058118 | 1.102248 | 1.207726 |
df.loc[“2019-01-01”: “2019-01-03”]
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2019-01-01 | -0.935378 | -0.190742 | 0.925984 | -0.818969 |
| 2019-01-02 | -0.234414 | -1.194674 | 1.080779 | -2.294395 |
| 2019-01-03 | -0.141572 | 0.058118 | 1.102248 | 1.207726 |
df.iloc[0: 3]
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2019-01-01 | -0.935378 | -0.190742 | 0.925984 | -0.818969 |
| 2019-01-02 | -0.234414 | -1.194674 | 1.080779 | -2.294395 |
| 2019-01-03 | -0.141572 | 0.058118 | 1.102248 | 1.207726 |
注意:这里的3是取不到的。
**(2)列切片**
df
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2019-01-01 | -0.935378 | -0.190742 | 0.925984 | -0.818969 |
| 2019-01-02 | -0.234414 | -1.194674 | 1.080779 | -2.294395 |
| 2019-01-03 | -0.141572 | 0.058118 | 1.102248 | 1.207726 |
| 2019-01-04 | 0.305088 | 0.535920 | -0.978434 | 0.177251 |
| 2019-01-05 | 0.313383 | 0.234041 | 0.163155 | -0.296649 |
| 2019-01-06 | 0.250613 | -0.904400 | -0.858240 | -1.573342 |
df.loc[:, “A”: “C”]
| | A | B | C |
| --- | --- | --- | --- |
| 2019-01-01 | -0.935378 | -0.190742 | 0.925984 |
| 2019-01-02 | -0.234414 | -1.194674 | 1.080779 |
| 2019-01-03 | -0.141572 | 0.058118 | 1.102248 |
| 2019-01-04 | 0.305088 | 0.535920 | -0.978434 |
| 2019-01-05 | 0.313383 | 0.234041 | 0.163155 |
| 2019-01-06 | 0.250613 | -0.904400 | -0.858240 |
df.iloc[:, 0: 3]
| | A | B | C |
| --- | --- | --- | --- |
| 2019-01-01 | -0.935378 | -0.190742 | 0.925984 |
| 2019-01-02 | -0.234414 | -1.194674 | 1.080779 |
| 2019-01-03 | -0.141572 | 0.058118 | 1.102248 |
| 2019-01-04 | 0.305088 | 0.535920 | -0.978434 |
| 2019-01-05 | 0.313383 | 0.234041 | 0.163155 |
| 2019-01-06 | 0.250613 | -0.904400 | -0.858240 |
**(3)多种多样的取值**
df
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2019-01-01 | -0.935378 | -0.190742 | 0.925984 | -0.818969 |
| 2019-01-02 | -0.234414 | -1.194674 | 1.080779 | -2.294395 |
| 2019-01-03 | -0.141572 | 0.058118 | 1.102248 | 1.207726 |
| 2019-01-04 | 0.305088 | 0.535920 | -0.978434 | 0.177251 |
| 2019-01-05 | 0.313383 | 0.234041 | 0.163155 | -0.296649 |
| 2019-01-06 | 0.250613 | -0.904400 | -0.858240 | -1.573342 |
* 行、列同时切片
df.loc[“2019-01-02”: “2019-01-03”, “C”:“D”]
| | C | D |
| --- | --- | --- |
| 2019-01-02 | 1.080779 | -2.294395 |
| 2019-01-03 | 1.102248 | 1.207726 |
df.iloc[1: 3, 2:]
| | C | D |
| --- | --- | --- |
| 2019-01-02 | 1.080779 | -2.294395 |
| 2019-01-03 | 1.102248 | 1.207726 |
* 行切片,列分散取值
df.loc[“2019-01-04”: “2019-01-06”, [“A”, “C”]]
| | A | C |
| --- | --- | --- |
| 2019-01-04 | 0.305088 | -0.978434 |
| 2019-01-05 | 0.313383 | 0.163155 |
| 2019-01-06 | 0.250613 | -0.858240 |
df.iloc[3:, [0, 2]]
| | A | C |
| --- | --- | --- |
| 2019-01-04 | 0.305088 | -0.978434 |
| 2019-01-05 | 0.313383 | 0.163155 |
| 2019-01-06 | 0.250613 | -0.858240 |
* 行分散取值,列切片
df.loc[[“2019-01-02”, “2019-01-06”], “C”: “D”]
上面这种方式是行不通的。
df.iloc[[1, 5], 0: 3]
| | A | B | C |
| --- | --- | --- | --- |
| 2019-01-02 | -0.234414 | -1.194674 | 1.080779 |
| 2019-01-06 | 0.250613 | -0.904400 | -0.858240 |
* 行、列均分散取值
df.loc[[“2019-01-04”, “2019-01-06”], [“A”, “D”]]
同样,上面这种方式是行不通的。
df.iloc[[1, 5], [0, 3]]
| | A | D |
| --- | --- | --- |
| 2019-01-02 | -0.234414 | -2.294395 |
| 2019-01-06 | 0.250613 | -1.573342 |
**4、布尔索引**
相当于numpy当中的掩码操作。
df
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2019-01-01 | -0.935378 | -0.190742 | 0.925984 | -0.818969 |
| 2019-01-02 | -0.234414 | -1.194674 | 1.080779 | -2.294395 |
| 2019-01-03 | -0.141572 | 0.058118 | 1.102248 | 1.207726 |
| 2019-01-04 | 0.305088 | 0.535920 | -0.978434 | 0.177251 |
| 2019-01-05 | 0.313383 | 0.234041 | 0.163155 | -0.296649 |
| 2019-01-06 | 0.250613 | -0.904400 | -0.858240 | -1.573342 |
df > 0
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2019-01-01 | False | False | True | False |
| 2019-01-02 | False | False | True | False |
| 2019-01-03 | False | True | True | True |
| 2019-01-04 | True | True | False | True |
| 2019-01-05 | True | True | True | False |
| 2019-01-06 | True | False | False | False |
df[df > 0]
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2019-01-01 | NaN | NaN | 0.925984 | NaN |
| 2019-01-02 | NaN | NaN | 1.080779 | NaN |
| 2019-01-03 | NaN | 0.058118 | 1.102248 | 1.207726 |
| 2019-01-04 | 0.305088 | 0.535920 | NaN | 0.177251 |
| 2019-01-05 | 0.313383 | 0.234041 | 0.163155 | NaN |
| 2019-01-06 | 0.250613 | NaN | NaN | NaN |
可以观察到,为true的部分都被取到了,而false没有。
df.A > 0
2019-01-01 False
2019-01-02 False
2019-01-03 False
2019-01-04 True
2019-01-05 True
2019-01-06 True
Freq: D, Name: A, dtype: bool
df[df.A > 0]
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2019-01-04 | 0.305088 | 0.535920 | -0.978434 | 0.177251 |
| 2019-01-05 | 0.313383 | 0.234041 | 0.163155 | -0.296649 |
| 2019-01-06 | 0.250613 | -0.904400 | -0.858240 | -1.573342 |
* isin()方法
df2 = df.copy()
df2[‘E’] = [‘one’, ‘one’, ‘two’, ‘three’, ‘four’, ‘three’]
df2
| | A | B | C | D | E |
| --- | --- | --- | --- | --- | --- |
| 2019-01-01 | -0.935378 | -0.190742 | 0.925984 | -0.818969 | one |
| 2019-01-02 | -0.234414 | -1.194674 | 1.080779 | -2.294395 | one |
| 2019-01-03 | -0.141572 | 0.058118 | 1.102248 | 1.207726 | two |
| 2019-01-04 | 0.305088 | 0.535920 | -0.978434 | 0.177251 | three |
| 2019-01-05 | 0.313383 | 0.234041 | 0.163155 | -0.296649 | four |
| 2019-01-06 | 0.250613 | -0.904400 | -0.858240 | -1.573342 | three |
ind = df2[“E”].isin([“two”, “four”])
ind
2019-01-01 False
2019-01-02 False
2019-01-03 True
2019-01-04 False
2019-01-05 True
2019-01-06 False
Freq: D, Name: E, dtype: bool
df2[ind]
| | A | B | C | D | E |
| --- | --- | --- | --- | --- | --- |
| 2019-01-03 | -0.141572 | 0.058118 | 1.102248 | 1.207726 | two |
| 2019-01-05 | 0.313383 | 0.234041 | 0.163155 | -0.296649 | four |
**(5)赋值**
df
* DataFrame 增加新列
s1 = pd.Series([1, 2, 3, 4, 5, 6], index=pd.date_range(‘20190101’, periods=6))
s1
2019-01-01 1
2019-01-02 2
2019-01-03 3
2019-01-04 4
2019-01-05 5
2019-01-06 6
Freq: D, dtype: int64
df[“E”] = s1
df
| | A | B | C | D | E |
| --- | --- | --- | --- | --- | --- |
| 2019-01-01 | -0.935378 | -0.190742 | 0.925984 | -0.818969 | 1 |
| 2019-01-02 | -0.234414 | -1.194674 | 1.080779 | -2.294395 | 2 |
| 2019-01-03 | -0.141572 | 0.058118 | 1.102248 | 1.207726 | 3 |
| 2019-01-04 | 0.305088 | 0.535920 | -0.978434 | 0.177251 | 4 |
| 2019-01-05 | 0.313383 | 0.234041 | 0.163155 | -0.296649 | 5 |
| 2019-01-06 | 0.250613 | -0.904400 | -0.858240 | -1.573342 | 6 |
* 修改赋值
df.loc[“2019-01-01”, “A”] = 0
df
| | A | B | C | D | E |
| --- | --- | --- | --- | --- | --- |
| 2019-01-01 | 0.000000 | -0.190742 | 0.925984 | -0.818969 | 1 |
| 2019-01-02 | -0.234414 | -1.194674 | 1.080779 | -2.294395 | 2 |
| 2019-01-03 | -0.141572 | 0.058118 | 1.102248 | 1.207726 | 3 |
| 2019-01-04 | 0.305088 | 0.535920 | -0.978434 | 0.177251 | 4 |
| 2019-01-05 | 0.313383 | 0.234041 | 0.163155 | -0.296649 | 5 |
| 2019-01-06 | 0.250613 | -0.904400 | -0.858240 | -1.573342 | 6 |
df.iloc[0, 1] = 0
df
| | A | B | C | D | E |
| --- | --- | --- | --- | --- | --- |
| 2019-01-01 | 0.000000 | 0.000000 | 0.925984 | -0.818969 | 1 |
| 2019-01-02 | -0.234414 | -1.194674 | 1.080779 | -2.294395 | 2 |
| 2019-01-03 | -0.141572 | 0.058118 | 1.102248 | 1.207726 | 3 |
| 2019-01-04 | 0.305088 | 0.535920 | -0.978434 | 0.177251 | 4 |
| 2019-01-05 | 0.313383 | 0.234041 | 0.163155 | -0.296649 | 5 |
| 2019-01-06 | 0.250613 | -0.904400 | -0.858240 | -1.573342 | 6 |
df[“D”] = np.array([5]*len(df)) # 可简化成df[“D”] = 5
df
| | A | B | C | D | E |
| --- | --- | --- | --- | --- | --- |
| 2019-01-01 | 0.000000 | 0.000000 | 0.925984 | 5 | 1 |
| 2019-01-02 | -0.234414 | -1.194674 | 1.080779 | 5 | 2 |
| 2019-01-03 | -0.141572 | 0.058118 | 1.102248 | 5 | 3 |
| 2019-01-04 | 0.305088 | 0.535920 | -0.978434 | 5 | 4 |
| 2019-01-05 | 0.313383 | 0.234041 | 0.163155 | 5 | 5 |
| 2019-01-06 | 0.250613 | -0.904400 | -0.858240 | 5 | 6 |
* 修改index和columns
df.index = [i for i in range(len(df))]
df
| | A | B | C | D | E |
| --- | --- | --- | --- | --- | --- |
| 0 | 0.000000 | 0.000000 | 0.925984 | 5 | 1 |
| 1 | -0.234414 | -1.194674 | 1.080779 | 5 | 2 |
| 2 | -0.141572 | 0.058118 | 1.102248 | 5 | 3 |
| 3 | 0.305088 | 0.535920 | -0.978434 | 5 | 4 |
| 4 | 0.313383 | 0.234041 | 0.163155 | 5 | 5 |
| 5 | 0.250613 | -0.904400 | -0.858240 | 5 | 6 |
df.columns = [i for i in range(df.shape[1])]
df
| | 0 | 1 | 2 | 3 | 4 |
| --- | --- | --- | --- | --- | --- |
| 0 | 0.000000 | 0.000000 | 0.925984 | 5 | 1 |
| 1 | -0.234414 | -1.194674 | 1.080779 | 5 | 2 |
| 2 | -0.141572 | 0.058118 | 1.102248 | 5 | 3 |
| 3 | 0.305088 | 0.535920 | -0.978434 | 5 | 4 |
| 4 | 0.313383 | 0.234041 | 0.163155 | 5 | 5 |
| 5 | 0.250613 | -0.904400 | -0.858240 | 5 | 6 |
### 11.3 数值运算及统计分析
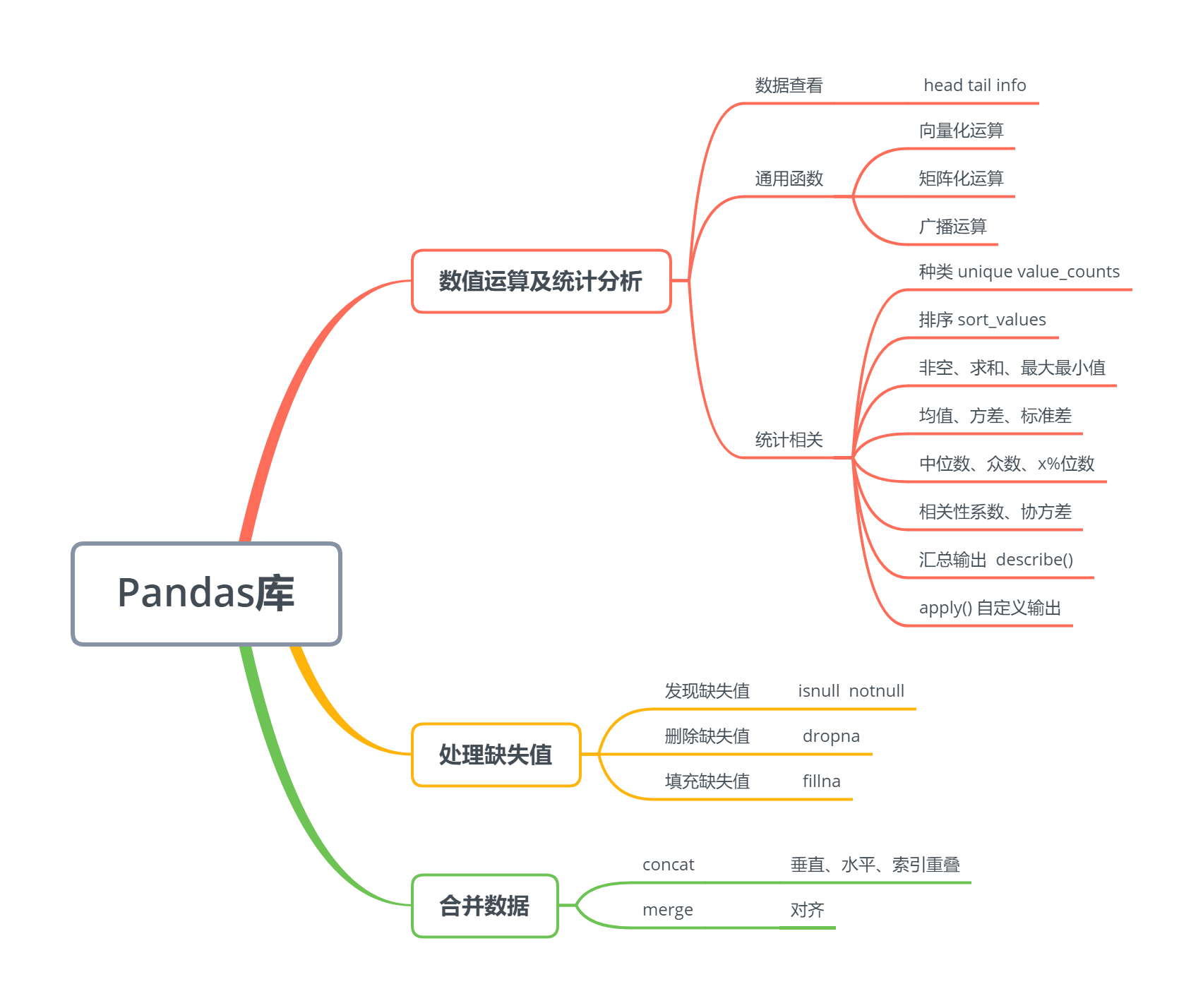
**1、数据的查看**
import pandas as pd
import numpy as np
dates = pd.date_range(start=‘2019-01-01’, periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=[“A”, “B”, “C”, “D”])
df
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2019-01-01 | -0.854043 | 0.412345 | -2.296051 | -0.048964 |
| 2019-01-02 | 1.371364 | -0.121454 | -0.299653 | 1.095375 |
| 2019-01-03 | -0.714591 | -1.103224 | 0.979250 | 0.319455 |
| 2019-01-04 | -1.397557 | 0.426008 | 0.233861 | -1.651887 |
| 2019-01-05 | 0.434026 | 0.459830 | -0.095444 | 1.220302 |
| 2019-01-06 | -0.133876 | 0.074500 | -1.028147 | 0.605402 |
**(1)查看前面的行**
df.head() # 默认5行,也可以进行设置
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2019-01-01 | -0.854043 | 0.412345 | -2.296051 | -0.048964 |
| 2019-01-02 | 1.371364 | -0.121454 | -0.299653 | 1.095375 |
| 2019-01-03 | -0.714591 | -1.103224 | 0.979250 | 0.319455 |
| 2019-01-04 | -1.397557 | 0.426008 | 0.233861 | -1.651887 |
| 2019-01-05 | 0.434026 | 0.459830 | -0.095444 | 1.220302 |
df.head(2)
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2019-01-01 | -0.854043 | 0.412345 | -2.296051 | -0.048964 |
| 2019-01-02 | 1.371364 | -0.121454 | -0.299653 | 1.095375 |
**(2)查看后面的行**
df.tail() # 默认5行
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2019-01-02 | 1.371364 | -0.121454 | -0.299653 | 1.095375 |
| 2019-01-03 | -0.714591 | -1.103224 | 0.979250 | 0.319455 |
| 2019-01-04 | -1.397557 | 0.426008 | 0.233861 | -1.651887 |
| 2019-01-05 | 0.434026 | 0.459830 | -0.095444 | 1.220302 |
| 2019-01-06 | -0.133876 | 0.074500 | -1.028147 | 0.605402 |
df.tail(3)
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2019-01-04 | -1.397557 | 0.426008 | 0.233861 | -1.651887 |
| 2019-01-05 | 0.434026 | 0.459830 | -0.095444 | 1.220302 |
| 2019-01-06 | -0.133876 | 0.074500 | -1.028147 | 0.605402 |
**(3)查看总体信息**
df.iloc[0, 3] = np.nan
df
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2019-01-01 | -0.854043 | 0.412345 | -2.296051 | NaN |
| 2019-01-02 | 1.371364 | -0.121454 | -0.299653 | 1.095375 |
| 2019-01-03 | -0.714591 | -1.103224 | 0.979250 | 0.319455 |
| 2019-01-04 | -1.397557 | 0.426008 | 0.233861 | -1.651887 |
| 2019-01-05 | 0.434026 | 0.459830 | -0.095444 | 1.220302 |
| 2019-01-06 | -0.133876 | 0.074500 | -1.028147 | 0.605402 |
df.info()
<class ‘pandas.core.frame.DataFrame’>
DatetimeIndex: 6 entries, 2019-01-01 to 2019-01-06
Freq: D
Data columns (total 4 columns):
A 6 non-null float64
B 6 non-null float64
C 6 non-null float64
D 5 non-null float64
dtypes: float64(4)
memory usage: 240.0 bytes
**2、Numpy通用函数同样适用于Pandas**
**(1)向量化运算**
x = pd.DataFrame(np.arange(4).reshape(1, 4))
x
| | 0 | 1 | 2 | 3 |
| --- | --- | --- | --- | --- |
| 0 | 0 | 1 | 2 | 3 |
x+5
| | 0 | 1 | 2 | 3 |
| --- | --- | --- | --- | --- |
| 0 | 5 | 6 | 7 | 8 |
np.exp(x)
| | 0 | 1 | 2 | 3 |
| --- | --- | --- | --- | --- |
| 0 | 1.0 | 2.718282 | 7.389056 | 20.085537 |
y = pd.DataFrame(np.arange(4,8).reshape(1, 4))
y
| | 0 | 1 | 2 | 3 |
| --- | --- | --- | --- | --- |
| 0 | 4 | 5 | 6 | 7 |
x*y
| | 0 | 1 | 2 | 3 |
| --- | --- | --- | --- | --- |
| 0 | 0 | 5 | 12 | 21 |
**(2)矩阵化运算**
np.random.seed(42)
x = pd.DataFrame(np.random.randint(10, size=(30, 30)))
x
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 6 | 3 | 7 | 4 | 6 | 9 | 2 | 6 | 7 | 4 | ... | 4 | 0 | 9 | 5 | 8 | 0 | 9 | 2 | 6 | 3 |
| 1 | 8 | 2 | 4 | 2 | 6 | 4 | 8 | 6 | 1 | 3 | ... | 2 | 0 | 3 | 1 | 7 | 3 | 1 | 5 | 5 | 9 |
| 2 | 3 | 5 | 1 | 9 | 1 | 9 | 3 | 7 | 6 | 8 | ... | 6 | 8 | 7 | 0 | 7 | 7 | 2 | 0 | 7 | 2 |
| 3 | 2 | 0 | 4 | 9 | 6 | 9 | 8 | 6 | 8 | 7 | ... | 0 | 2 | 4 | 2 | 0 | 4 | 9 | 6 | 6 | 8 |
| 4 | 9 | 9 | 2 | 6 | 0 | 3 | 3 | 4 | 6 | 6 | ... | 9 | 6 | 8 | 6 | 0 | 0 | 8 | 8 | 3 | 8 |
| 5 | 2 | 6 | 5 | 7 | 8 | 4 | 0 | 2 | 9 | 7 | ... | 2 | 0 | 4 | 0 | 7 | 0 | 0 | 1 | 1 | 5 |
| 6 | 6 | 4 | 0 | 0 | 2 | 1 | 4 | 9 | 5 | 6 | ... | 5 | 0 | 8 | 5 | 2 | 3 | 3 | 2 | 9 | 2 |
| 7 | 2 | 3 | 6 | 3 | 8 | 0 | 7 | 6 | 1 | 7 | ... | 3 | 0 | 1 | 0 | 4 | 4 | 6 | 8 | 8 | 2 |
| 8 | 2 | 2 | 3 | 7 | 5 | 7 | 0 | 7 | 3 | 0 | ... | 1 | 1 | 5 | 2 | 8 | 3 | 0 | 3 | 0 | 4 |
| 9 | 3 | 7 | 7 | 6 | 2 | 0 | 0 | 2 | 5 | 6 | ... | 4 | 2 | 3 | 2 | 0 | 0 | 4 | 5 | 2 | 8 |
| 10 | 4 | 7 | 0 | 4 | 2 | 0 | 3 | 4 | 6 | 0 | ... | 5 | 6 | 1 | 9 | 1 | 9 | 0 | 7 | 0 | 8 |
| 11 | 5 | 6 | 9 | 6 | 9 | 2 | 1 | 8 | 7 | 9 | ... | 6 | 5 | 2 | 8 | 9 | 5 | 9 | 9 | 5 | 0 |
| 12 | 3 | 9 | 5 | 5 | 4 | 0 | 7 | 4 | 4 | 6 | ... | 0 | 7 | 2 | 9 | 6 | 9 | 4 | 9 | 4 | 6 |
| 13 | 8 | 4 | 0 | 9 | 9 | 0 | 1 | 5 | 8 | 7 | ... | 5 | 8 | 4 | 0 | 3 | 4 | 9 | 9 | 4 | 6 |
| 14 | 3 | 0 | 4 | 6 | 9 | 9 | 5 | 4 | 3 | 1 | ... | 6 | 1 | 0 | 3 | 7 | 1 | 2 | 0 | 0 | 2 |
| 15 | 4 | 2 | 0 | 0 | 7 | 9 | 1 | 2 | 1 | 2 | ... | 6 | 3 | 9 | 4 | 1 | 7 | 3 | 8 | 4 | 8 |
| 16 | 3 | 9 | 4 | 8 | 7 | 2 | 0 | 2 | 3 | 1 | ... | 8 | 0 | 0 | 3 | 8 | 5 | 2 | 0 | 3 | 8 |
| 17 | 2 | 8 | 6 | 3 | 2 | 9 | 4 | 4 | 2 | 8 | ... | 6 | 9 | 4 | 2 | 6 | 1 | 8 | 9 | 9 | 0 |
| 18 | 5 | 6 | 7 | 9 | 8 | 1 | 9 | 1 | 4 | 4 | ... | 3 | 5 | 2 | 5 | 6 | 9 | 9 | 2 | 6 | 2 |
| 19 | 1 | 9 | 3 | 7 | 8 | 6 | 0 | 2 | 8 | 0 | ... | 4 | 3 | 2 | 2 | 3 | 8 | 1 | 8 | 0 | 0 |
| 20 | 4 | 5 | 5 | 2 | 6 | 8 | 9 | 7 | 5 | 7 | ... | 3 | 5 | 0 | 8 | 0 | 4 | 3 | 2 | 5 | 1 |
| 21 | 2 | 4 | 8 | 1 | 9 | 7 | 1 | 4 | 6 | 7 | ... | 0 | 1 | 8 | 2 | 0 | 4 | 6 | 5 | 0 | 4 |
| 22 | 4 | 5 | 2 | 4 | 6 | 4 | 4 | 4 | 9 | 9 | ... | 1 | 7 | 6 | 9 | 9 | 1 | 5 | 5 | 2 | 1 |
| 23 | 0 | 5 | 4 | 8 | 0 | 6 | 4 | 4 | 1 | 2 | ... | 8 | 5 | 0 | 7 | 6 | 9 | 2 | 0 | 4 | 3 |
| 24 | 9 | 7 | 0 | 9 | 0 | 3 | 7 | 4 | 1 | 5 | ... | 3 | 7 | 8 | 2 | 2 | 1 | 9 | 2 | 2 | 4 |
| 25 | 4 | 1 | 9 | 5 | 4 | 5 | 0 | 4 | 8 | 9 | ... | 9 | 3 | 0 | 7 | 0 | 2 | 3 | 7 | 5 | 9 |
| 26 | 6 | 7 | 1 | 9 | 7 | 2 | 6 | 2 | 6 | 1 | ... | 0 | 6 | 5 | 9 | 8 | 0 | 3 | 8 | 3 | 9 |
| 27 | 2 | 8 | 1 | 3 | 5 | 1 | 7 | 7 | 0 | 2 | ... | 8 | 0 | 4 | 5 | 4 | 5 | 5 | 6 | 3 | 7 |
| 28 | 6 | 8 | 6 | 2 | 2 | 7 | 4 | 3 | 7 | 5 | ... | 1 | 7 | 9 | 2 | 4 | 5 | 9 | 5 | 3 | 2 |
| 29 | 3 | 0 | 3 | 0 | 0 | 9 | 5 | 4 | 3 | 2 | ... | 1 | 3 | 0 | 4 | 8 | 0 | 8 | 7 | 5 | 6 |
30 rows × 30 columns
* 转置
z = x.T
z
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 6 | 8 | 3 | 2 | 9 | 2 | 6 | 2 | 2 | 3 | ... | 4 | 2 | 4 | 0 | 9 | 4 | 6 | 2 | 6 | 3 |
| 1 | 3 | 2 | 5 | 0 | 9 | 6 | 4 | 3 | 2 | 7 | ... | 5 | 4 | 5 | 5 | 7 | 1 | 7 | 8 | 8 | 0 |
| 2 | 7 | 4 | 1 | 4 | 2 | 5 | 0 | 6 | 3 | 7 | ... | 5 | 8 | 2 | 4 | 0 | 9 | 1 | 1 | 6 | 3 |
| 3 | 4 | 2 | 9 | 9 | 6 | 7 | 0 | 3 | 7 | 6 | ... | 2 | 1 | 4 | 8 | 9 | 5 | 9 | 3 | 2 | 0 |
| 4 | 6 | 6 | 1 | 6 | 0 | 8 | 2 | 8 | 5 | 2 | ... | 6 | 9 | 6 | 0 | 0 | 4 | 7 | 5 | 2 | 0 |
| 5 | 9 | 4 | 9 | 9 | 3 | 4 | 1 | 0 | 7 | 0 | ... | 8 | 7 | 4 | 6 | 3 | 5 | 2 | 1 | 7 | 9 |
| 6 | 2 | 8 | 3 | 8 | 3 | 0 | 4 | 7 | 0 | 0 | ... | 9 | 1 | 4 | 4 | 7 | 0 | 6 | 7 | 4 | 5 |
| 7 | 6 | 6 | 7 | 6 | 4 | 2 | 9 | 6 | 7 | 2 | ... | 7 | 4 | 4 | 4 | 4 | 4 | 2 | 7 | 3 | 4 |
| 8 | 7 | 1 | 6 | 8 | 6 | 9 | 5 | 1 | 3 | 5 | ... | 5 | 6 | 9 | 1 | 1 | 8 | 6 | 0 | 7 | 3 |
| 9 | 4 | 3 | 8 | 7 | 6 | 7 | 6 | 7 | 0 | 6 | ... | 7 | 7 | 9 | 2 | 5 | 9 | 1 | 2 | 5 | 2 |
| 10 | 3 | 8 | 7 | 1 | 3 | 5 | 3 | 0 | 7 | 5 | ... | 4 | 0 | 2 | 6 | 4 | 1 | 9 | 9 | 1 | 0 |
| 11 | 7 | 1 | 4 | 0 | 6 | 7 | 6 | 8 | 3 | 5 | ... | 7 | 5 | 0 | 5 | 1 | 0 | 5 | 8 | 3 | 5 |
| 12 | 7 | 9 | 1 | 6 | 2 | 8 | 7 | 8 | 5 | 5 | ... | 9 | 0 | 4 | 1 | 2 | 9 | 2 | 4 | 3 | 1 |
| 13 | 2 | 8 | 4 | 6 | 5 | 3 | 0 | 1 | 7 | 2 | ... | 3 | 1 | 8 | 5 | 8 | 8 | 2 | 5 | 5 | 7 |
| 14 | 5 | 9 | 7 | 7 | 1 | 0 | 5 | 6 | 3 | 5 | ... | 9 | 0 | 0 | 1 | 6 | 9 | 8 | 3 | 5 | 9 |
| 15 | 4 | 4 | 9 | 4 | 9 | 0 | 7 | 9 | 2 | 7 | ... | 7 | 4 | 2 | 1 | 6 | 8 | 6 | 9 | 0 | 4 |
| 16 | 1 | 1 | 8 | 2 | 8 | 9 | 4 | 2 | 8 | 1 | ... | 9 | 9 | 3 | 1 | 5 | 8 | 4 | 1 | 7 | 6 |
| 17 | 7 | 3 | 8 | 7 | 4 | 3 | 3 | 6 | 2 | 4 | ... | 1 | 8 | 0 | 2 | 7 | 5 | 9 | 7 | 5 | 9 |
| 18 | 5 | 6 | 0 | 5 | 5 | 6 | 1 | 9 | 8 | 0 | ... | 4 | 5 | 0 | 1 | 3 | 7 | 6 | 5 | 2 | 1 |
| 19 | 1 | 7 | 8 | 2 | 3 | 1 | 5 | 8 | 1 | 0 | ... | 8 | 0 | 7 | 3 | 7 | 0 | 8 | 4 | 8 | 7 |
| 20 | 4 | 2 | 6 | 0 | 9 | 2 | 5 | 3 | 1 | 4 | ... | 3 | 0 | 1 | 8 | 3 | 9 | 0 | 8 | 1 | 1 |
| 21 | 0 | 0 | 8 | 2 | 6 | 0 | 0 | 0 | 1 | 2 | ... | 5 | 1 | 7 | 5 | 7 | 3 | 6 | 0 | 7 | 3 |
| 22 | 9 | 3 | 7 | 4 | 8 | 4 | 8 | 1 | 5 | 3 | ... | 0 | 8 | 6 | 0 | 8 | 0 | 5 | 4 | 9 | 0 |
| 23 | 5 | 1 | 0 | 2 | 6 | 0 | 5 | 0 | 2 | 2 | ... | 8 | 2 | 9 | 7 | 2 | 7 | 9 | 5 | 2 | 4 |
| 24 | 8 | 7 | 7 | 0 | 0 | 7 | 2 | 4 | 8 | 0 | ... | 0 | 0 | 9 | 6 | 2 | 0 | 8 | 4 | 4 | 8 |
| 25 | 0 | 3 | 7 | 4 | 0 | 0 | 3 | 4 | 3 | 0 | ... | 4 | 4 | 1 | 9 | 1 | 2 | 0 | 5 | 5 | 0 |
| 26 | 9 | 1 | 2 | 9 | 8 | 0 | 3 | 6 | 0 | 4 | ... | 3 | 6 | 5 | 2 | 9 | 3 | 3 | 5 | 9 | 8 |
| 27 | 2 | 5 | 0 | 6 | 8 | 1 | 2 | 8 | 3 | 5 | ... | 2 | 5 | 5 | 0 | 2 | 7 | 8 | 6 | 5 | 7 |
| 28 | 6 | 5 | 7 | 6 | 3 | 1 | 9 | 8 | 0 | 2 | ... | 5 | 0 | 2 | 4 | 2 | 5 | 3 | 3 | 3 | 5 |
| 29 | 3 | 9 | 2 | 8 | 8 | 5 | 2 | 2 | 4 | 8 | ... | 1 | 4 | 1 | 3 | 4 | 9 | 9 | 7 | 2 | 6 |
30 rows × 30 columns
np.random.seed(1)
y = pd.DataFrame(np.random.randint(10, size=(30, 30)))
y
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 5 | 8 | 9 | 5 | 0 | 0 | 1 | 7 | 6 | 9 | ... | 1 | 7 | 0 | 6 | 9 | 9 | 7 | 6 | 9 | 1 |
| 1 | 0 | 1 | 8 | 8 | 3 | 9 | 8 | 7 | 3 | 6 | ... | 9 | 2 | 0 | 4 | 9 | 2 | 7 | 7 | 9 | 8 |
| 2 | 6 | 9 | 3 | 7 | 7 | 4 | 5 | 9 | 3 | 6 | ... | 7 | 7 | 1 | 1 | 3 | 0 | 8 | 6 | 4 | 5 |
| 3 | 6 | 2 | 5 | 7 | 8 | 4 | 4 | 7 | 7 | 4 | ... | 0 | 1 | 9 | 8 | 2 | 3 | 1 | 2 | 7 | 2 |
| 4 | 6 | 0 | 9 | 2 | 6 | 6 | 2 | 7 | 7 | 0 | ... | 1 | 5 | 4 | 0 | 7 | 8 | 9 | 5 | 7 | 0 |
| 5 | 9 | 3 | 9 | 1 | 4 | 4 | 6 | 8 | 8 | 9 | ... | 1 | 8 | 7 | 0 | 3 | 4 | 2 | 0 | 3 | 5 |
| 6 | 1 | 2 | 4 | 3 | 0 | 6 | 0 | 7 | 2 | 8 | ... | 4 | 3 | 3 | 6 | 7 | 3 | 5 | 3 | 2 | 4 |
| 7 | 4 | 0 | 3 | 3 | 8 | 3 | 5 | 6 | 7 | 5 | ... | 1 | 7 | 3 | 1 | 6 | 6 | 9 | 6 | 9 | 6 |
| 8 | 0 | 0 | 2 | 9 | 6 | 0 | 6 | 7 | 0 | 3 | ... | 6 | 7 | 9 | 5 | 4 | 9 | 5 | 2 | 5 | 6 |
| 9 | 6 | 8 | 7 | 7 | 7 | 2 | 6 | 0 | 5 | 2 | ... | 7 | 0 | 6 | 2 | 4 | 3 | 6 | 7 | 6 | 3 |
| 10 | 0 | 6 | 4 | 7 | 6 | 2 | 9 | 5 | 9 | 9 | ... | 4 | 9 | 3 | 9 | 1 | 2 | 5 | 4 | 0 | 8 |
| 11 | 2 | 3 | 9 | 9 | 4 | 4 | 8 | 2 | 1 | 6 | ... | 0 | 5 | 9 | 8 | 6 | 6 | 0 | 4 | 7 | 3 |
| 12 | 0 | 1 | 6 | 0 | 6 | 1 | 6 | 4 | 2 | 5 | ... | 8 | 8 | 0 | 7 | 2 | 0 | 7 | 1 | 1 | 9 |
| 13 | 5 | 1 | 5 | 9 | 6 | 4 | 9 | 8 | 7 | 5 | ... | 2 | 4 | 3 | 2 | 0 | 0 | 4 | 2 | 5 | 0 |
| 14 | 0 | 3 | 8 | 5 | 3 | 1 | 4 | 7 | 3 | 2 | ... | 8 | 5 | 5 | 7 | 5 | 9 | 1 | 3 | 9 | 3 |
| 15 | 3 | 3 | 6 | 1 | 3 | 0 | 5 | 0 | 5 | 2 | ... | 7 | 1 | 7 | 7 | 3 | 8 | 3 | 0 | 6 | 3 |
| 16 | 0 | 6 | 5 | 9 | 6 | 4 | 6 | 6 | 2 | 2 | ... | 3 | 6 | 8 | 6 | 5 | 1 | 3 | 2 | 6 | 3 |
| 17 | 6 | 7 | 2 | 8 | 0 | 1 | 8 | 6 | 0 | 0 | ... | 5 | 6 | 2 | 5 | 4 | 3 | 0 | 6 | 2 | 1 |
| 18 | 9 | 4 | 4 | 0 | 9 | 8 | 7 | 7 | 6 | 1 | ... | 7 | 9 | 9 | 7 | 1 | 1 | 4 | 6 | 5 | 6 |
| 19 | 4 | 1 | 1 | 5 | 1 | 2 | 6 | 2 | 3 | 3 | ... | 0 | 0 | 0 | 9 | 8 | 5 | 9 | 3 | 4 | 0 |
| 20 | 9 | 8 | 6 | 3 | 9 | 9 | 0 | 8 | 1 | 6 | ... | 2 | 9 | 0 | 1 | 3 | 9 | 4 | 8 | 8 | 8 |
| 21 | 2 | 8 | 6 | 4 | 9 | 0 | 5 | 5 | 6 | 1 | ... | 6 | 7 | 5 | 6 | 8 | 7 | 4 | 2 | 4 | 0 |
| 22 | 0 | 3 | 5 | 9 | 0 | 3 | 6 | 5 | 1 | 1 | ... | 6 | 2 | 5 | 3 | 9 | 3 | 9 | 5 | 1 | 9 |
| 23 | 7 | 7 | 0 | 8 | 6 | 1 | 2 | 0 | 4 | 4 | ... | 1 | 9 | 6 | 0 | 2 | 8 | 3 | 7 | 2 | 5 |
| 24 | 6 | 0 | 4 | 2 | 3 | 1 | 0 | 5 | 7 | 0 | ... | 1 | 1 | 2 | 7 | 5 | 2 | 9 | 4 | 7 | 3 |
| 25 | 5 | 0 | 2 | 1 | 4 | 9 | 4 | 6 | 9 | 3 | ... | 5 | 5 | 3 | 5 | 9 | 2 | 7 | 4 | 1 | 6 |
| 26 | 9 | 8 | 1 | 8 | 1 | 6 | 2 | 6 | 1 | 8 | ... | 2 | 5 | 1 | 2 | 5 | 3 | 3 | 6 | 1 | 8 |
| 27 | 1 | 8 | 6 | 4 | 6 | 9 | 5 | 4 | 7 | 2 | ... | 9 | 3 | 1 | 5 | 1 | 1 | 7 | 1 | 2 | 6 |
| 28 | 0 | 7 | 7 | 4 | 3 | 2 | 7 | 8 | 5 | 2 | ... | 0 | 2 | 8 | 3 | 7 | 3 | 9 | 2 | 3 | 8 |
| 29 | 8 | 0 | 2 | 6 | 8 | 3 | 6 | 4 | 9 | 7 | ... | 6 | 7 | 8 | 5 | 7 | 2 | 5 | 3 | 4 | 5 |
30 rows × 30 columns
x.dot(y)
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 616 | 560 | 723 | 739 | 612 | 457 | 681 | 799 | 575 | 590 | ... | 523 | 739 | 613 | 580 | 668 | 602 | 733 | 585 | 657 | 700 |
| 1 | 520 | 438 | 691 | 600 | 612 | 455 | 666 | 764 | 707 | 592 | ... | 555 | 681 | 503 | 679 | 641 | 506 | 779 | 494 | 633 | 590 |
| 2 | 557 | 570 | 786 | 807 | 690 | 469 | 804 | 828 | 704 | 573 | ... | 563 | 675 | 712 | 758 | 793 | 672 | 754 | 550 | 756 | 638 |
| 3 | 605 | 507 | 664 | 701 | 660 | 496 | 698 | 806 | 651 | 575 | ... | 582 | 685 | 668 | 586 | 629 | 534 | 678 | 484 | 591 | 626 |
| 4 | 599 | 681 | 753 | 873 | 721 | 563 | 754 | 770 | 620 | 654 | ... | 633 | 747 | 661 | 677 | 726 | 649 | 716 | 610 | 735 | 706 |
| 5 | 422 | 354 | 602 | 627 | 613 | 396 | 617 | 627 | 489 | 423 | ... | 456 | 572 | 559 | 537 | 499 | 384 | 589 | 436 | 574 | 507 |
| 6 | 359 | 446 | 599 | 599 | 481 | 357 | 577 | 572 | 451 | 464 | ... | 449 | 550 | 495 | 532 | 633 | 554 | 663 | 476 | 565 | 602 |
| 7 | 531 | 520 | 698 | 590 | 607 | 537 | 665 | 696 | 571 | 472 | ... | 576 | 588 | 551 | 665 | 652 | 527 | 742 | 528 | 650 | 599 |
| 8 | 449 | 322 | 547 | 533 | 593 | 399 | 584 | 638 | 587 | 424 | ... | 402 | 596 | 523 | 523 | 447 | 362 | 561 | 386 | 529 | 484 |
| 9 | 373 | 433 | 525 | 601 | 522 | 345 | 551 | 521 | 434 | 447 | ... | 508 | 498 | 438 | 478 | 459 | 418 | 488 | 407 | 503 | 496 |
| 10 | 500 | 427 | 574 | 607 | 667 | 477 | 652 | 656 | 615 | 477 | ... | 622 | 702 | 531 | 610 | 558 | 532 | 598 | 471 | 582 | 561 |
| 11 | 664 | 694 | 772 | 841 | 779 | 574 | 730 | 810 | 711 | 608 | ... | 591 | 760 | 616 | 638 | 721 | 676 | 846 | 678 | 754 | 708 |
| 12 | 545 | 547 | 687 | 701 | 721 | 576 | 689 | 724 | 710 | 532 | ... | 674 | 684 | 648 | 694 | 710 | 564 | 757 | 571 | 671 | 656 |
| 13 | 574 | 586 | 723 | 750 | 691 | 494 | 696 | 787 | 667 | 523 | ... | 618 | 681 | 568 | 682 | 715 | 644 | 756 | 557 | 690 | 604 |
| 14 | 502 | 382 | 645 | 557 | 570 | 403 | 538 | 677 | 500 | 501 | ... | 369 | 650 | 507 | 576 | 546 | 531 | 554 | 437 | 616 | 463 |
| 15 | 510 | 505 | 736 | 651 | 649 | 510 | 719 | 733 | 694 | 557 | ... | 605 | 717 | 574 | 642 | 678 | 576 | 755 | 455 | 598 | 654 |
| 16 | 567 | 376 | 614 | 612 | 643 | 514 | 598 | 724 | 547 | 464 | ... | 456 | 639 | 520 | 560 | 569 | 442 | 596 | 517 | 659 | 532 |
| 17 | 626 | 716 | 828 | 765 | 740 | 603 | 809 | 852 | 692 | 591 | ... | 664 | 716 | 655 | 721 | 742 | 612 | 819 | 593 | 744 | 712 |
| 18 | 600 | 559 | 667 | 664 | 641 | 556 | 624 | 815 | 638 | 564 | ... | 581 | 701 | 559 | 677 | 710 | 554 | 748 | 597 | 614 | 657 |
| 19 | 445 | 431 | 661 | 681 | 641 | 552 | 690 | 719 | 602 | 474 | ... | 515 | 637 | 576 | 620 | 572 | 512 | 599 | 455 | 622 | 538 |
| 20 | 523 | 569 | 784 | 725 | 713 | 501 | 740 | 772 | 638 | 640 | ... | 589 | 775 | 664 | 686 | 726 | 672 | 747 | 548 | 723 | 645 |
| 21 | 487 | 465 | 553 | 639 | 517 | 449 | 592 | 609 | 454 | 398 | ... | 492 | 567 | 534 | 404 | 554 | 417 | 561 | 466 | 498 | 492 |
| 22 | 479 | 449 | 574 | 686 | 583 | 377 | 566 | 614 | 563 | 455 | ... | 453 | 539 | 491 | 501 | 596 | 520 | 722 | 478 | 565 | 501 |
| 23 | 483 | 386 | 476 | 526 | 550 | 426 | 492 | 585 | 536 | 482 | ... | 322 | 541 | 438 | 456 | 487 | 408 | 502 | 426 | 474 | 481 |
| 24 | 523 | 551 | 658 | 767 | 537 | 444 | 663 | 731 | 576 | 577 | ... | 522 | 590 | 525 | 664 | 691 | 548 | 635 | 526 | 641 | 538 |
| 25 | 652 | 656 | 738 | 753 | 853 | 508 | 752 | 815 | 669 | 576 | ... | 694 | 833 | 693 | 606 | 575 | 616 | 704 | 559 | 728 | 672 |
| 26 | 578 | 577 | 744 | 856 | 699 | 497 | 779 | 800 | 733 | 587 | ... | 630 | 754 | 704 | 834 | 760 | 680 | 765 | 592 | 731 | 629 |
| 27 | 554 | 494 | 665 | 689 | 630 | 574 | 695 | 703 | 636 | 599 | ... | 554 | 685 | 532 | 658 | 649 | 554 | 693 | 577 | 634 | 668 |
| 28 | 498 | 552 | 659 | 784 | 552 | 492 | 690 | 775 | 544 | 551 | ... | 567 | 636 | 518 | 599 | 742 | 521 | 733 | 533 | 605 | 604 |
| 29 | 513 | 491 | 563 | 642 | 477 | 367 | 589 | 647 | 516 | 484 | ... | 428 | 574 | 504 | 548 | 553 | 483 | 540 | 407 | 547 | 455 |
30 rows × 30 columns
%timeit x.dot(y)
218 µs ± 18.7 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%timeit np.dot(x, y)
81.1 µs ± 2.85 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
* 执行相同运算,Numpy与Pandas的对比
x1 = np.array(x)
x1
y1 = np.array(y)
y1
%timeit x1.dot(y1)
22.1 µs ± 992 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
%timeit np.dot(x1, y1)
22.6 µs ± 766 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
%timeit np.dot(x.values, y.values)
42.9 µs ± 1.24 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
x2 = list(x1)
y2 = list(y1)
x3 = []
y3 = []
for i in x2:
res = []
for j in i:
res.append(int(j))
x3.append(res)
for i in y2:
res = []
for j in i:
res.append(int(j))
y3.append(res)
def f(x, y):
res = []
for i in range(len(x)):
row = []
for j in range(len(y[0])):
sum_row = 0
for k in range(len(x[0])):
sum_row += x[i][k]*y[k][j]
row.append(sum_row)
res.append(row)
return res
%timeit f(x3, y3)
4.29 ms ± 207 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
**一般来说,纯粹的计算在Numpy里执行的更快**
Numpy更侧重于计算,Pandas更侧重于数据处理
**(3)广播运算**
np.random.seed(42)
x = pd.DataFrame(np.random.randint(10, size=(3, 3)), columns=list(“ABC”))
x
| | A | B | C |
| --- | --- | --- | --- |
| 0 | 6 | 3 | 7 |
| 1 | 4 | 6 | 9 |
| 2 | 2 | 6 | 7 |
* 按行广播
x.iloc[0]
A 6
B 3
C 7
Name: 0, dtype: int32
x/x.iloc[0]
| | A | B | C |
| --- | --- | --- | --- |
| 0 | 1.000000 | 1.0 | 1.000000 |
| 1 | 0.666667 | 2.0 | 1.285714 |
| 2 | 0.333333 | 2.0 | 1.000000 |
* 按列广播
x.A
0 6
1 4
2 2
Name: A, dtype: int32
x.div(x.A, axis=0) # add sub div mul
| | A | B | C |
| --- | --- | --- | --- |
| 0 | 1.0 | 0.5 | 1.166667 |
| 1 | 1.0 | 1.5 | 2.250000 |
| 2 | 1.0 | 3.0 | 3.500000 |
x.div(x.iloc[0], axis=1)
| | A | B | C |
| --- | --- | --- | --- |
| 0 | 1.000000 | 1.0 | 1.000000 |
| 1 | 0.666667 | 2.0 | 1.285714 |
| 2 | 0.333333 | 2.0 | 1.000000 |
**3、新的用法**
**(1)索引对齐**
A = pd.DataFrame(np.random.randint(0, 20, size=(2, 2)), columns=list(“AB”))
A
| | A | B |
| --- | --- | --- |
| 0 | 3 | 7 |
| 1 | 2 | 1 |
B = pd.DataFrame(np.random.randint(0, 10, size=(3, 3)), columns=list(“ABC”))
B
| | A | B | C |
| --- | --- | --- | --- |
| 0 | 7 | 5 | 1 |
| 1 | 4 | 0 | 9 |
| 2 | 5 | 8 | 0 |
* pandas会自动对齐两个对象的索引,没有的值用np.nan表示
A+B
| | A | B | C |
| --- | --- | --- | --- |
| 0 | 10.0 | 12.0 | NaN |
| 1 | 6.0 | 1.0 | NaN |
| 2 | NaN | NaN | NaN |
* 缺省值也可用fill\_value来填充
A.add(B, fill_value=0)
| | A | B | C |
| --- | --- | --- | --- |
| 0 | 10.0 | 12.0 | 1.0 |
| 1 | 6.0 | 1.0 | 9.0 |
| 2 | 5.0 | 8.0 | 0.0 |
A*B
| | A | B | C |
| --- | --- | --- | --- |
| 0 | 21.0 | 35.0 | NaN |
| 1 | 8.0 | 0.0 | NaN |
| 2 | NaN | NaN | NaN |
**(2)统计相关**
* 数据种类统计
y = np.random.randint(3, size=20)
y
array([2, 2, 2, 1, 2, 1, 1, 2, 1, 2, 2, 0, 2, 0, 2, 2, 0, 0, 2, 1])
np.unique(y)
array([0, 1, 2])
用Counter方法统计数据
from collections import Counter
Counter(y)
Counter({2: 11, 1: 5, 0: 4})
y1 = pd.DataFrame(y, columns=[“A”])
y1
| | A |
| --- | --- |
| 0 | 2 |
| 1 | 2 |
| 2 | 2 |
| 3 | 1 |
| 4 | 2 |
| 5 | 1 |
| 6 | 1 |
| 7 | 2 |
| 8 | 1 |
| 9 | 2 |
| 10 | 2 |
| 11 | 0 |
| 12 | 2 |
| 13 | 0 |
| 14 | 2 |
| 15 | 2 |
| 16 | 0 |
| 17 | 0 |
| 18 | 2 |
| 19 | 1 |
np.unique(y1)
有value counter的方法
y1[“A”].value_counts()
2 11
1 5
0 4
Name: A, dtype: int64
* 产生新的结果,并进行排序
population_dict = {“BeiJing”: 2154,
“ShangHai”: 2424,
“ShenZhen”: 1303,
“HangZhou”: 981 }
population = pd.Series(population_dict)
GDP_dict = {“BeiJing”: 30320,
“ShangHai”: 32680,
“ShenZhen”: 24222,
“HangZhou”: 13468 }
GDP = pd.Series(GDP_dict)
city_info = pd.DataFrame({“population”: population,“GDP”: GDP})
city_info
| | population | GDP |
| --- | --- | --- |
| BeiJing | 2154 | 30320 |
| ShangHai | 2424 | 32680 |
| ShenZhen | 1303 | 24222 |
| HangZhou | 981 | 13468 |
city_info[“per_GDP”] = city_info[“GDP”]/city_info[“population”]
city_info
| | population | GDP | per\_GDP |
| --- | --- | --- | --- |
| BeiJing | 2154 | 30320 | 14.076137 |
| ShangHai | 2424 | 32680 | 13.481848 |
| ShenZhen | 1303 | 24222 | 18.589409 |
| HangZhou | 981 | 13468 | 13.728848 |
递增排序
city_info.sort_values(by=“per_GDP”)
| | population | GDP | per\_GDP |
| --- | --- | --- | --- |
| ShangHai | 2424 | 32680 | 13.481848 |
| HangZhou | 981 | 13468 | 13.728848 |
| BeiJing | 2154 | 30320 | 14.076137 |
| ShenZhen | 1303 | 24222 | 18.589409 |
递减排序
city_info.sort_values(by=“per_GDP”, ascending=False)
| | population | GDP | per\_GDP |
| --- | --- | --- | --- |
| ShenZhen | 1303 | 24222 | 18.589409 |
| BeiJing | 2154 | 30320 | 14.076137 |
| HangZhou | 981 | 13468 | 13.728848 |
| ShangHai | 2424 | 32680 | 13.481848 |
**按轴进行排序**
data = pd.DataFrame(np.random.randint(20, size=(3, 4)), index=[2, 1, 0], columns=list(“CBAD”))
data
| | C | B | A | D |
| --- | --- | --- | --- | --- |
| 2 | 3 | 13 | 17 | 8 |
| 1 | 1 | 19 | 14 | 6 |
| 0 | 11 | 7 | 14 | 2 |
行排序
data.sort_index()
| | C | B | A | D |
| --- | --- | --- | --- | --- |
| 0 | 11 | 7 | 14 | 2 |
| 1 | 1 | 19 | 14 | 6 |
| 2 | 3 | 13 | 17 | 8 |
列排序
data.sort_index(axis=1)
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 2 | 17 | 13 | 3 | 8 |
| 1 | 14 | 19 | 1 | 6 |
| 0 | 14 | 7 | 11 | 2 |
data.sort_index(axis=1, ascending=False)
| | D | C | B | A |
| --- | --- | --- | --- | --- |
| 2 | 8 | 3 | 13 | 17 |
| 1 | 6 | 1 | 19 | 14 |
| 0 | 2 | 11 | 7 | 14 |
* 统计方法
df = pd.DataFrame(np.random.normal(2, 4, size=(6, 4)),columns=list(“ABCD”))
df
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | 1.082198 | 3.557396 | -3.060476 | 6.367969 |
| 1 | 13.113252 | 6.774559 | 2.874553 | 5.527044 |
| 2 | -2.036341 | -4.333177 | 5.094802 | -0.152567 |
| 3 | -3.386712 | -1.522365 | -2.522209 | 2.537716 |
| 4 | 4.328491 | 5.550994 | 5.577329 | 5.019991 |
| 5 | 1.171336 | -0.493910 | -4.032613 | 6.398588 |
非空个数
df.count()
A 6
B 6
C 6
D 6
dtype: int64
求和
df.sum()
A 14.272224
B 9.533497
C 3.931385
D 25.698741
dtype: float64
df.sum(axis=1)
0 7.947086
1 28.289408
2 -1.427283
3 -4.893571
4 20.476806
5 3.043402
dtype: float64
最大值 最小值
df.min()
A -3.386712
B -4.333177
C -4.032613
D -0.152567
dtype: float64
df.max(axis=1)
0 6.367969
1 13.113252
2 5.094802
3 2.537716
4 5.577329
5 6.398588
dtype: float64
df
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | 1.082198 | 3.557396 | -3.060476 | 6.367969 |
| 1 | 13.113252 | 6.774559 | 2.874553 | 5.527044 |
| 2 | -2.036341 | -4.333177 | 5.094802 | -0.152567 |
| 3 | -3.386712 | -1.522365 | -2.522209 | 2.537716 |
| 4 | 4.328491 | 5.550994 | 5.577329 | 5.019991 |
| 5 | 1.171336 | -0.493910 | -4.032613 | 6.398588 |
df.idxmax()
A 1
B 1
C 4
D 5
dtype: int64
均值
df.mean()
A 2.378704
B 1.588916
C 0.655231
D 4.283124
dtype: float64
方差
df.var()
A 34.980702
B 19.110656
C 18.948144
D 6.726776
dtype: float64
标准差
df.std()
A 5.914449
B 4.371574
C 4.352947
D 2.593603
dtype: float64
中位数
df.median()
A 1.126767
B 1.531743
C 0.176172
D 5.273518
dtype: float64
众数
data = pd.DataFrame(np.random.randint(5, size=(10, 2)), columns=list(“AB”))
data
| | A | B |
| --- | --- | --- |
| 0 | 4 | 2 |
| 1 | 3 | 2 |
| 2 | 2 | 0 |
| 3 | 2 | 4 |
| 4 | 2 | 0 |
| 5 | 4 | 1 |
| 6 | 2 | 0 |
| 7 | 1 | 1 |
| 8 | 3 | 4 |
| 9 | 2 | 0 |
data.mode()
| | A | B |
| --- | --- | --- |
| 0 | 2 | 0 |
75%分位数
df.quantile(0.75)
A 3.539202
B 5.052594
C 4.539740
D 6.157738
Name: 0.75, dtype: float64
* 用describe()可以获取所有属性
df.describe()
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| count | 6.000000 | 6.000000 | 6.000000 | 6.000000 |
| mean | 2.378704 | 1.588916 | 0.655231 | 4.283124 |
| std | 5.914449 | 4.371574 | 4.352947 | 2.593603 |
| min | -3.386712 | -4.333177 | -4.032613 | -0.152567 |
| 25% | -1.256706 | -1.265251 | -2.925910 | 3.158284 |
| 50% | 1.126767 | 1.531743 | 0.176172 | 5.273518 |
| 75% | 3.539202 | 5.052594 | 4.539740 | 6.157738 |
| max | 13.113252 | 6.774559 | 5.577329 | 6.398588 |
data_2 = pd.DataFrame([[“a”, “a”, “c”, “d”],
[“c”, “a”, “c”, “b”],
[“a”, “a”, “d”, “c”]], columns=list(“ABCD”))
data_2
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | a | a | c | d |
| 1 | c | a | c | b |
| 2 | a | a | d | c |
* 字符串类型的describe
data_2.describe()
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| count | 3 | 3 | 3 | 3 |
| unique | 2 | 1 | 2 | 3 |
| top | a | a | c | d |
| freq | 2 | 3 | 2 | 1 |
相关性系数和协方差
df.corr()
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| A | 1.000000 | 0.831063 | 0.331060 | 0.510821 |
| B | 0.831063 | 1.000000 | 0.179244 | 0.719112 |
| C | 0.331060 | 0.179244 | 1.000000 | -0.450365 |
| D | 0.510821 | 0.719112 | -0.450365 | 1.000000 |
df.corrwith(df[“A”])
A 1.000000
B 0.831063
C 0.331060
D 0.510821
dtype: float64
自定义输出
apply(method)的用法:使用method方法默认对每一列进行相应的操作
df
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | 1.082198 | 3.557396 | -3.060476 | 6.367969 |
| 1 | 13.113252 | 6.774559 | 2.874553 | 5.527044 |
| 2 | -2.036341 | -4.333177 | 5.094802 | -0.152567 |
| 3 | -3.386712 | -1.522365 | -2.522209 | 2.537716 |
| 4 | 4.328491 | 5.550994 | 5.577329 | 5.019991 |
| 5 | 1.171336 | -0.493910 | -4.032613 | 6.398588 |
df.apply(np.cumsum)
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | 1.082198 | 3.557396 | -3.060476 | 6.367969 |
| 1 | 14.195450 | 10.331955 | -0.185923 | 11.895013 |
| 2 | 12.159109 | 5.998778 | 4.908878 | 11.742447 |
| 3 | 8.772397 | 4.476413 | 2.386669 | 14.280162 |
| 4 | 13.100888 | 10.027406 | 7.963999 | 19.300153 |
| 5 | 14.272224 | 9.533497 | 3.931385 | 25.698741 |
df.apply(np.cumsum, axis=1)
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | 1.082198 | 4.639594 | 1.579117 | 7.947086 |
| 1 | 13.113252 | 19.887811 | 22.762364 | 28.289408 |
| 2 | -2.036341 | -6.369518 | -1.274717 | -1.427283 |
| 3 | -3.386712 | -4.909077 | -7.431287 | -4.893571 |
| 4 | 4.328491 | 9.879485 | 15.456814 | 20.476806 |
| 5 | 1.171336 | 0.677427 | -3.355186 | 3.043402 |
df.apply(sum)
A 14.272224
B 9.533497
C 3.931385
D 25.698741
dtype: float64
df.sum()
A 14.272224
B 9.533497
C 3.931385
D 25.698741
dtype: float64
df.apply(lambda x: x.max()-x.min())
A 16.499965
B 11.107736
C 9.609942
D 6.551155
dtype: float64
def my_describe(x):
return pd.Series([x.count(), x.mean(), x.max(), x.idxmin(), x.std()],
index=[“Count”, “mean”, “max”, “idxmin”, “std”])
df.apply(my_describe)
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| Count | 6.000000 | 6.000000 | 6.000000 | 6.000000 |
| mean | 2.378704 | 1.588916 | 0.655231 | 4.283124 |
| max | 13.113252 | 6.774559 | 5.577329 | 6.398588 |
| idxmin | 3.000000 | 2.000000 | 5.000000 | 2.000000 |
| std | 5.914449 | 4.371574 | 4.352947 | 2.593603 |
### 11.4 缺失值处理
**1、发现缺失值**
import pandas as pd
import numpy as np
data = pd.DataFrame(np.array([[1, np.nan, 2],
[np.nan, 3, 4],
[5, 6, None]]), columns=[“A”, “B”, “C”])
data
| | A | B | C |
| --- | --- | --- | --- |
| 0 | 1 | NaN | 2 |
| 1 | NaN | 3 | 4 |
| 2 | 5 | 6 | None |
**注意:有None、字符串等,数据类型全部变为object,它比int和float更消耗资源**
np.nan是一个特殊的浮点数,类型是浮点类型,所以表示缺失值时最好使用NaN。
data.dtypes
A object
B object
C object
dtype: object
data.isnull()
| | A | B | C |
| --- | --- | --- | --- |
| 0 | False | True | False |
| 1 | True | False | False |
| 2 | False | False | True |
data.notnull()
| | A | B | C |
| --- | --- | --- | --- |
| 0 | True | False | True |
| 1 | False | True | True |
| 2 | True | True | False |
**2、删除缺失值**
data = pd.DataFrame(np.array([[1, np.nan, 2, 3],
[np.nan, 4, 5, 6],
[7, 8, np.nan, 9],
[10, 11 , 12, 13]]), columns=[“A”, “B”, “C”, “D”])
data
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | 1.0 | NaN | 2.0 | 3.0 |
| 1 | NaN | 4.0 | 5.0 | 6.0 |
| 2 | 7.0 | 8.0 | NaN | 9.0 |
| 3 | 10.0 | 11.0 | 12.0 | 13.0 |
**注意:np.nan是一种特殊的浮点数**
data.dtypes
A float64
B float64
C float64
D float64
dtype: object
**(1)删除整行**
data.dropna()
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 3 | 10.0 | 11.0 | 12.0 | 13.0 |
**(2)删除整列**
data.dropna(axis=“columns”)
| | D |
| --- | --- |
| 0 | 3.0 |
| 1 | 6.0 |
| 2 | 9.0 |
| 3 | 13.0 |
data[“D”] = np.nan
data
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | 1.0 | NaN | 2.0 | NaN |
| 1 | NaN | 4.0 | 5.0 | NaN |
| 2 | 7.0 | 8.0 | NaN | NaN |
| 3 | 10.0 | 11.0 | 12.0 | NaN |
data.dropna(axis=“columns”, how=“all”)
| | A | B | C |
| --- | --- | --- | --- |
| 0 | 1.0 | NaN | 2.0 |
| 1 | NaN | 4.0 | 5.0 |
| 2 | 7.0 | 8.0 | NaN |
| 3 | 10.0 | 11.0 | 12.0 |
all表示都是缺失值时才删除。
data.dropna(axis=“columns”, how=“any”)
| |
| --- |
| 0 |
| --- |
| 1 |
| 2 |
| 3 |
data.loc[3] = np.nan
data
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | 1.0 | NaN | 2.0 | NaN |
| 1 | NaN | 4.0 | 5.0 | NaN |
| 2 | 7.0 | 8.0 | NaN | NaN |
| 3 | NaN | NaN | NaN | NaN |
data.dropna(how=“all”)
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | 1.0 | NaN | 2.0 | NaN |
| 1 | NaN | 4.0 | 5.0 | NaN |
| 2 | 7.0 | 8.0 | NaN | NaN |
**3、填充缺失值**
data = pd.DataFrame(np.array([[1, np.nan, 2, 3],
[np.nan, 4, 5, 6],
[7, 8, np.nan, 9],
[10, 11 , 12, 13]]), columns=[“A”, “B”, “C”, “D”])
data
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | 1.0 | NaN | 2.0 | 3.0 |
| 1 | NaN | 4.0 | 5.0 | 6.0 |
| 2 | 7.0 | 8.0 | NaN | 9.0 |
| 3 | 10.0 | 11.0 | 12.0 | 13.0 |
data.fillna(value=5)
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | 1.0 | 5.0 | 2.0 | 3.0 |
| 1 | 5.0 | 4.0 | 5.0 | 6.0 |
| 2 | 7.0 | 8.0 | 5.0 | 9.0 |
| 3 | 10.0 | 11.0 | 12.0 | 13.0 |
* 用均值进行替换
fill = data.mean()
fill
A 6.000000
B 7.666667
C 6.333333
D 7.750000
dtype: float64
data.fillna(value=fill)
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | 1.0 | 7.666667 | 2.000000 | 3.0 |
| 1 | 6.0 | 4.000000 | 5.000000 | 6.0 |
| 2 | 7.0 | 8.000000 | 6.333333 | 9.0 |
| 3 | 10.0 | 11.000000 | 12.000000 | 13.0 |
全部数据的平均值,先进行摊平,再进行填充即可。
fill = data.stack().mean()
fill
7.0
data.fillna(value=fill)
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | 1.0 | 7.0 | 2.0 | 3.0 |
| 1 | 7.0 | 4.0 | 5.0 | 6.0 |
| 2 | 7.0 | 8.0 | 7.0 | 9.0 |
| 3 | 10.0 | 11.0 | 12.0 | 13.0 |
### 11.5 合并数据
* 构造一个生产DataFrame的函数
import pandas as pd
import numpy as np
def make_df(cols, ind):
“一个简单的DataFrame”
data = {c: [str©+str(i) for i in ind] for c in cols}
return pd.DataFrame(data, ind)
make_df(“ABC”, range(3))
| | A | B | C |
| --- | --- | --- | --- |
| 0 | A0 | B0 | C0 |
| 1 | A1 | B1 | C1 |
| 2 | A2 | B2 | C2 |
* 垂直合并
df_1 = make_df(“AB”, [1, 2])
df_2 = make_df(“AB”, [3, 4])
print(df_1)
print(df_2)
A B
1 A1 B1
2 A2 B2
A B
3 A3 B3
4 A4 B4
pd.concat([df_1, df_2])
| | A | B |
| --- | --- | --- |
| 1 | A1 | B1 |
| 2 | A2 | B2 |
| 3 | A3 | B3 |
| 4 | A4 | B4 |
* 水平合并
df_3 = make_df(“AB”, [0, 1])
df_4 = make_df(“CD”, [0, 1])
print(df_3)
print(df_4)
A B
0 A0 B0
1 A1 B1
C D
0 C0 D0
1 C1 D1
pd.concat([df_3, df_4], axis=1)
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | A0 | B0 | C0 | D0 |
| 1 | A1 | B1 | C1 | D1 |
* 索引重叠
行重叠
df_5 = make_df(“AB”, [1, 2])
df_6 = make_df(“AB”, [1, 2])
print(df_5)
print(df_6)
A B
1 A1 B1
2 A2 B2
A B
1 A1 B1
2 A2 B2
pd.concat([df_5, df_6])
| | A | B |
| --- | --- | --- |
| 1 | A1 | B1 |
| 2 | A2 | B2 |
| 1 | A1 | B1 |
| 2 | A2 | B2 |
pd.concat([df_5, df_6],ignore_index=True)
| | A | B |
| --- | --- | --- |
| 0 | A1 | B1 |
| 1 | A2 | B2 |
| 2 | A1 | B1 |
| 3 | A2 | B2 |
列重叠
df_7 = make_df(“ABC”, [1, 2])
df_8 = make_df(“BCD”, [1, 2])
print(df_7)
print(df_8)
A B C
1 A1 B1 C1
2 A2 B2 C2
B C D
1 B1 C1 D1
2 B2 C2 D2
pd.concat([df_7, df_8], axis=1)
| | A | B | C | B | C | D |
| --- | --- | --- | --- | --- | --- | --- |
| 1 | A1 | B1 | C1 | B1 | C1 | D1 |
| 2 | A2 | B2 | C2 | B2 | C2 | D2 |
pd.concat([df_7, df_8],axis=1, ignore_index=True)
| | 0 | 1 | 2 | 3 | 4 | 5 |
| --- | --- | --- | --- | --- | --- | --- |
| 1 | A1 | B1 | C1 | B1 | C1 | D1 |
| 2 | A2 | B2 | C2 | B2 | C2 | D2 |
* 对齐合并merge()
df_9 = make_df(“AB”, [1, 2])
df_10 = make_df(“BC”, [1, 2])
print(df_9)
print(df_10)
A B
1 A1 B1
2 A2 B2
B C
1 B1 C1
2 B2 C2
pd.merge(df_9, df_10)


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618658159)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
2 | 7.0 | 8.000000 | 6.333333 | 9.0 |
| 3 | 10.0 | 11.000000 | 12.000000 | 13.0 |
全部数据的平均值,先进行摊平,再进行填充即可。
fill = data.stack().mean()
fill
7.0
data.fillna(value=fill)
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | 1.0 | 7.0 | 2.0 | 3.0 |
| 1 | 7.0 | 4.0 | 5.0 | 6.0 |
| 2 | 7.0 | 8.0 | 7.0 | 9.0 |
| 3 | 10.0 | 11.0 | 12.0 | 13.0 |
### 11.5 合并数据
* 构造一个生产DataFrame的函数
import pandas as pd
import numpy as np
def make_df(cols, ind):
“一个简单的DataFrame”
data = {c: [str©+str(i) for i in ind] for c in cols}
return pd.DataFrame(data, ind)
make_df(“ABC”, range(3))
| | A | B | C |
| --- | --- | --- | --- |
| 0 | A0 | B0 | C0 |
| 1 | A1 | B1 | C1 |
| 2 | A2 | B2 | C2 |
* 垂直合并
df_1 = make_df(“AB”, [1, 2])
df_2 = make_df(“AB”, [3, 4])
print(df_1)
print(df_2)
A B
1 A1 B1
2 A2 B2
A B
3 A3 B3
4 A4 B4
pd.concat([df_1, df_2])
| | A | B |
| --- | --- | --- |
| 1 | A1 | B1 |
| 2 | A2 | B2 |
| 3 | A3 | B3 |
| 4 | A4 | B4 |
* 水平合并
df_3 = make_df(“AB”, [0, 1])
df_4 = make_df(“CD”, [0, 1])
print(df_3)
print(df_4)
A B
0 A0 B0
1 A1 B1
C D
0 C0 D0
1 C1 D1
pd.concat([df_3, df_4], axis=1)
| | A | B | C | D |
| --- | --- | --- | --- | --- |
| 0 | A0 | B0 | C0 | D0 |
| 1 | A1 | B1 | C1 | D1 |
* 索引重叠
行重叠
df_5 = make_df(“AB”, [1, 2])
df_6 = make_df(“AB”, [1, 2])
print(df_5)
print(df_6)
A B
1 A1 B1
2 A2 B2
A B
1 A1 B1
2 A2 B2
pd.concat([df_5, df_6])
| | A | B |
| --- | --- | --- |
| 1 | A1 | B1 |
| 2 | A2 | B2 |
| 1 | A1 | B1 |
| 2 | A2 | B2 |
pd.concat([df_5, df_6],ignore_index=True)
| | A | B |
| --- | --- | --- |
| 0 | A1 | B1 |
| 1 | A2 | B2 |
| 2 | A1 | B1 |
| 3 | A2 | B2 |
列重叠
df_7 = make_df(“ABC”, [1, 2])
df_8 = make_df(“BCD”, [1, 2])
print(df_7)
print(df_8)
A B C
1 A1 B1 C1
2 A2 B2 C2
B C D
1 B1 C1 D1
2 B2 C2 D2
pd.concat([df_7, df_8], axis=1)
| | A | B | C | B | C | D |
| --- | --- | --- | --- | --- | --- | --- |
| 1 | A1 | B1 | C1 | B1 | C1 | D1 |
| 2 | A2 | B2 | C2 | B2 | C2 | D2 |
pd.concat([df_7, df_8],axis=1, ignore_index=True)
| | 0 | 1 | 2 | 3 | 4 | 5 |
| --- | --- | --- | --- | --- | --- | --- |
| 1 | A1 | B1 | C1 | B1 | C1 | D1 |
| 2 | A2 | B2 | C2 | B2 | C2 | D2 |
* 对齐合并merge()
df_9 = make_df(“AB”, [1, 2])
df_10 = make_df(“BC”, [1, 2])
print(df_9)
print(df_10)
A B
1 A1 B1
2 A2 B2
B C
1 B1 C1
2 B2 C2
pd.merge(df_9, df_10)
[外链图片转存中...(img-fAH6f2Eu-1715656828894)]
[外链图片转存中...(img-3vO0C0QI-1715656828895)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618658159)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









