










既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
}
type XormDB struct{
db *xorm.Session
}
func (xorm *XormDB) Insert(ctx context.Context,instance …interface{}){
xorm.db.Context(ctx).Insert(instance)
}
现在我们要实现从 xorm 到 gorm 的切换将变得非常简单,只需要新增一个实现了 DBer 的 GormDB 实例,同时在初始化时调用 AddDB 设置新的数据库实例就好了,其他地方的代码完全不用变动。
type GormDB struct{
db *xorm.Session
}
func (gorm *GormDB) Insert(ctx context.Context,instance …interface{}){
gorm.db.Context(ctx).Create(instance)
}
有了接口,代码变得更具通用性和可扩展性了。而且,我们也不用修改 InsertTrade 等核心业务的方法,这就减少了出错的可能性。更重要的是,我们实现了模块间的解耦,修改 DB 模块不会影响到其他模块,每个模块都可以独立地开发、更换和调试。
## 依赖注入
程序中的模块通常会依赖其他模块返回的结果,测试中遇到的困难:
* 第三方模块的环境不太容易和线上完全一致,依赖的模块可能又依赖了其他的模块。
* 除了依赖服务太多这个问题外,依赖配置也很繁琐。例如,要测试一个场景,需要往数据库中插入数据、删除数据,这增加了复杂性。
* 场景很难完全覆盖。打个比方,如果当前服务在进行逻辑处理时,非常依赖外部服务返回的数据,那我想测试外部服务返回特定的数据时,当前服务会有什么不同的行为就非常困难。
* 有一些第三方模块涉及到复杂逻辑,或者会 sleep 很长时间,这时进行完整测试需要花费很长的时间。
### 示例1 InsertTrade不需要启动数据库
它的内部有一个插入订单的操作,测试时不必真的启动一个数据库,也不必真的将订单插入到数据库中。
下面这段代码中,EmptyDB 实现了 DBer 接口,但是实际函数中并不执行任何操作。
type Trade struct {
db DBer
}
func (t *Trade) AddDB(db DBer) {
t.db = db
}
func (t*Trade) InsertTrade() error{
…
t.db.Create(t)
}
// 测试代码
type EmptyDB struct {
}
func (e *EmptyDB) Insert(ctx context.Context, instance …interface{}) {
return
}
func TestHandleTrade(t *testing.T) {
t := Trade{}
t.add(EmptyDB{})
err := t.handleTrade()
assert.NotNil(t,err)
}
### 示例2 redigo时间函数
[redigo](https://bbs.csdn.net/topics/618658159) 库的一个重要功能是维持 Redis 的连接池。但是连接一段时间后,需要强制断开,这段时间被称为最大连接时间。假设我们设置的最大连接时间是 300 秒。redigo 在取出连接池的连接后,会先判断当前时间减去连接创建时间是否超过 300 秒。如果超过,则立即销毁连接(这段代码省略掉了不必要的细节,[原始代码](https://bbs.csdn.net/topics/618658159):
var nowFunc = time.Now
func (p *Pool) GetContext(ctx context.Context) (Conn, error) {
// 从连接池获取连接
for p.idle.front != nil {
pc := p.idle.front
p.idle.popFront()
// 当前时间减去连接创建时间未超过300秒,立即返回。
if (nowFunc().Sub(pc.created) < p.MaxConnLifetime) {
return &activeConn{p: p, pc: pc}, nil
}
}
}
这里比较有意思的是,获取当前时间的方式通过了一个 nowFunc 变量。
nowFunc 是一个函数变量,其本质上也是 time.Now 函数。
为什么不直接使用我们比较熟悉的 time.Now(),而是额外增加了一层呢?
* 为了方便测试。你试想一下,如果我们想测试函数在 300s 之后能否断开,那么我们的单元测试必须要等 300s 这么久吗?显然是不可能的,这样做效率太低了。
* Redigo 的做法是,通过修改 now 函数变量对应的值,我们可以任意修改当前时间,从而影响 GetContext 函数的行为。当时间未超过最大连接时间时,我们预期连接会被复用,达不到测试超时的效果,所以我们可以设置 now = now.Add(p.MaxConnLifetime + 1) ,巧妙地让当前时间超过最大连接时间,看连接是不是真的和预期一样被销毁。
// pool_test.go
func TestPoolMaxLifetime(t *testing.T) {
d := poolDialer{t: t}
p := &redis.Pool{
MaxIdle: 2,
MaxConnLifetime: 300 * time.Second,
Dial: d.dial,
}
defer p.Close()
// 设置now为当前时间
now := time.Now()
redis.SetNowFunc(func() time.Time { return now })
defer redis.SetNowFunc(time.Now)
c := p.Get()
_, err := c.Do(“PING”)
require.NoError(t, err)
c.Close()
d.check(“1”, p, 1, 1, 0)
// 设置now为最大连接时间+1
now = now.Add(p.MaxConnLifetime + 1)
c = p.Get()
_, err = c.Do(“PING”)
require.NoError(t, err)
c.Close()
d.check(“2”, p, 2, 1, 0)
}
## 接口底层
接口的底层结构如下,它分为 tab 和 data 两个字段。
type iface struct {
tab *itab // 存储了接口的类型、接口中的动态数据类型、动态数据类型的函数指针等
data unsafe.Pointer // 存储了接口中动态类型的数据指针
}
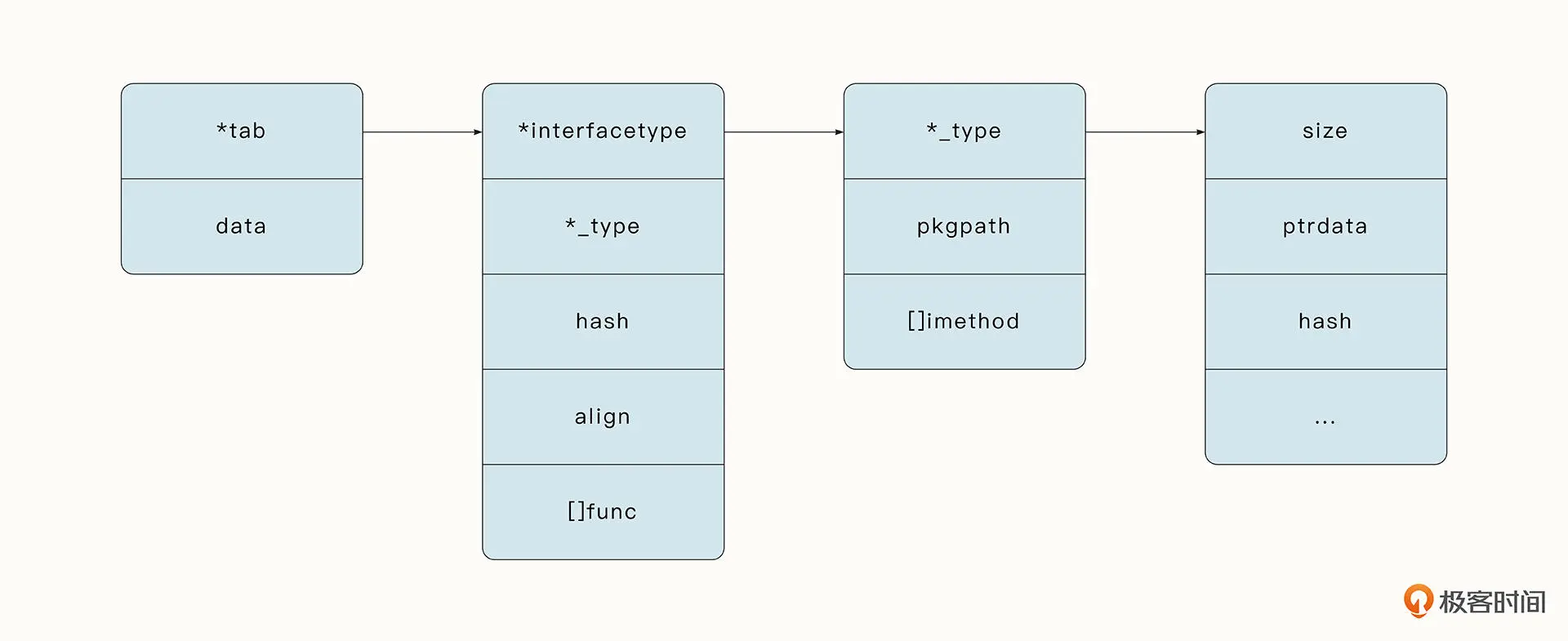
接口能够容纳不同的类型的秘诀
* 存储当前接口的类型
* 存储动态数据类型
* 存储动态数据类型对应的数据
* 动态数据类型实现接口方法的指针。
这种为不同数据类型的实体提供统一接口的能力被称为多态。实际上,接口只是一个容器,当我们调用接口时,最终会找到接口中容纳的动态数据类型和它所对应方法的指针,并完成调用。
## 接口成本
由于动态数据类型对应的数据大小难以预料,接口中使用指针来存储数据。
同时,为了方便数据被寻址,平时分配在栈中的值一旦赋值给接口后,Go 运行时会在堆区为接口开辟内存,这种现象被称为内存逃逸,它是接口需要承担的成本之一。
**内存逃逸意味着堆内存分配时的时间消耗**。
接口的另一个成本是**调用时查找接口中容纳的动态数据类型和它对应的方法的指针带来的开销。**
这种开销的成本有多大呢?
这里我们用一个简单的 Benchmark 测试来说明一下。在下面这个例子中,BenchmarkDirect 测试直接调用调用的开销。BenchmarkInterface 测试进行接口调用的开销,但其函数接收者是一个非指针。BenchmarkInterfacePointer 也是测试接口调用的开销,但其函数接收者是一个指针。
package escape
import “testing”
type Sumifier interface{ Add(a, b int32) int32 }
type Sumer struct{ id int32 }
func (math Sumer) Add(a, b int32) int32 { return a + b }
type SumerPointer struct{ id int32 }
func (math *SumerPointer) Add(a, b int32) int32 { return a + b }
func BenchmarkDirect(b *testing.B) {
adder := Sumer{id: 6754}
b.ResetTimer()
for i := 0; i < b.N; i++ {
adder.Add(10, 12)
}
}
func BenchmarkInterface(b *testing.B) {
adder := Sumer{id: 6754}
b.ResetTimer()
for i := 0; i < b.N; i++ {
Sumifier(adder).Add(10, 12)
}
}
func BenchmarkInterfacePointer(b *testing.B) {
adder := &SumerPointer{id: 6754}
b.ResetTimer()
for i := 0; i < b.N; i++ {
Sumifier(adder).Add(10, 12)
}
}
在 Benchmark 测试中,我们静止编译器的优化和内联汇编,避免这两种因素对耗时产生的影响。测试结果如下。可以看到直接函数调用的速度最快,为 1.95 ns/op, 方法接收者为指针的接口调用和函数调用的速度类似,为 2.37 ns/op, 方法接收者为非指针的接口调用却慢了数倍,为 14.6 ns/op。
N: Windows直接运行\*\*`go test -gcflags "-N -l" -bench=.`\*\*好像不行
» go test -gcflags “-N -l” -bench=.
BenchmarkDirect-12 535487740 1.95 ns/op
BenchmarkInterface-12 76026812 14.6 ns/op
BenchmarkInterfacePointer-12 517756519 2.37 ns/op
go test -gcflags “-N -l” -bench=.
goos: linux
goarch: amd64
pkg: github.com/funbinary/go_example/example/crawler/benchmark
cpu: 12th Gen Intel® Core™ i7-12700F
BenchmarkDirect-20 1000000000 0.9737 ns/op
BenchmarkInterface-20 906270834 1.305 ns/op
BenchmarkInterfacePointer-20 1000000000 1.080 ns/op
PASS
ok github.com/funbinary/go_example/example/crawler/benchmark 3.587s
\*\*方法接收者为非指针的接口调用速度之所以很慢是受到了内存拷贝的影响。\*\*由于接口中存储了数据的指针,而函数调用的是非指针,因此数据会从对堆内存拷贝到栈内存,让调用速度变慢。
启发:
* 在使用接口时,**方法接收者使用指针的形式能够带来速度的提升**
* **接口调用带来的性能损失很小**,在实际开发中,不必担心接口带来的效率损失
## 爬取技术
* 模拟浏览器访问
* 代理访问
## 爬取接口抽象
* 创建collect用于采集引擎, 存放与爬取相关代码
* 定义Fetcher接口,内部方法Get,参数为url N: 后续会修改,不用提前费劲设计
type Fetcher interface {
Get(url string) ([]byte, error)
}
* 定义一个结构体 BaseFetch,用最基本的爬取逻辑实现 Fetcher 接口:
func (BaseFetch) Get(url string) ([]byte, error) {
resp, err := http.Get(url)
if err != nil {
fmt.Println(err)
return nil, err
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
fmt.Printf(“Error status code:%d”, resp.StatusCode)
}
bodyReader := bufio.NewReader(resp.Body)
e := DeterminEncoding(bodyReader)
utf8Reader := transform.NewReader(bodyReader, e.NewDecoder())
return ioutil.ReadAll(utf8Reader)
}
* 在 main.go 中定义一个类型为 BaseFetch 的结构体,用接口 Fetcher 接收并调用 Get 方法,这样就完成了使用接口来实现基本爬取的逻辑。
var f collect.Fetcher = collect.BaseFetch{}
body, err := f.Get(url)
## 模拟浏览器访问
* 反爬机制
* User-Agent 字段: 表明当前正在使用的应用程序、设备类型和操作系统的类型与版本。
* R: [大多浏览器使用的User-Agent格式](https://bbs.csdn.net/topics/618658159)
Mozilla/5.0 (操作系统信息) 运行平台(运行平台细节) <扩展信息>
* 我的浏览器
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36
+ Mozilla/5.0 由于历史原因,是现在的主流浏览器都会发送的。
+ Windows NT 10.0; Win64; x64: 操作系统版本号。
+ AppleWebKit/537.36: 使用的 Web 渲染引擎标识符。
+ KHTML: 在 Safari 和 Chrome 上使用的引擎。
+ Chrome/111.0.0.0 Safari/537.36: 浏览器版本号
* 不同浏览器,User-Agent会不同
Lynx: Lynx/2.8.8pre.4 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/2.12.23
Wget: Wget/1.15 (linux-gnu)
Curl: curl/7.35.0
Samsung Galaxy Note 4: Mozilla/5.0 (Linux; Android 6.0.1; SAMSUNG SM-N910F Build/MMB29M) AppleWebKit/537.36 (KHTML, like Gecko) SamsungBrowser/4.0 Chrome/44.0.2403.133 Mobile Safari/537.36
Apple iPhone: Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_1 like Mac OS X) AppleWebKit/603.1.30 (KHTML, like Gecko) Version/10.0 Mobile/14E304 Safari/602.1
Apple iPad: Mozilla/5.0 (iPad; CPU OS 8_4_1 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12H321 Safari/600.1.4
Microsoft Internet Explorer 11 / IE 11: Mozilla/5.0 (compatible, MSIE 11, Windows NT 6.3; Trident/7.0; rv:11.0) like Gecko
* 有时候,我们的爬虫服务需要动态生成 User-Agent 列表,方便在测试、或者在使用代理大量请求单一网站时,动态设置不同的 User-Agent。
### 实现BrowserFetch
* 创建一个 HTTP 客户端 http.Client
* 通过 http.NewRequest 创建一个请求。
* 在请求中调用 req.Header.Set 设置 User-Agent 请求头。
* 调用 client.Do 完成 HTTP 请求。
type BrowserFetch struct {
}
func (b *BrowserFetch) Get(url string) ([]byte, error) {
client := &http.Client{}
req, err := http.NewRequest("GET", url, nil)
if err != nil {
return nil, err
}
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36\t\n")
resp, err := client.Do(req)
if err != nil {
return nil, err
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return nil, errors.Errorf("Error status code:%v", resp.StatusCode)
}
r := bufio.NewReader(resp.Body)
e := DeterminEncoding(r)
utf8r := transform.NewReader(r, e.NewDecoder())
return io.ReadAll(utf8r)
}
## 远程访问浏览器
要借助浏览器的能力实现自动化爬取,目前依靠的技术有以下三种:
* 借助浏览器驱动协议(WebDriver protocol)远程与浏览器交互;
* 借助谷歌开发者工具协议(CDP,Chrome DevTools Protocol)远程与浏览器交互;
* 在浏览器应用程序中注入要执行的 JavaScript,典型的工具有 Cypress, TestCafe。
通常只用于测试,所以下面我们就重点来说说前面两种技术。
### Webdriver Protocol
Webdriver 协议是操作浏览器的一种远程控制协议。借助 Webdriver 协议完成爬虫的框架或库有 Selenium,WebdriverIO,Nightwatch,其中最知名的就是 [Selenium](https://bbs.csdn.net/topics/618658159)。Selenium 为每一种语言(例如 Java、Python、Ruby 等)都准备了一个对应的 clinet 库,它整合了不同浏览器的驱动(这些驱动由浏览器厂商提供,例如谷歌浏览器的驱动和火狐浏览器的驱动)。
Selenium 通过 W3C 约定的 WebDriver 协议与指定的浏览器驱动进行通信,之后浏览器驱动操作特定浏览器,从而实现开发者操作浏览器的目的。由于 Selenium 整合了不同的浏览器驱动,因此它对于不同的浏览器都具有良好的兼容性。
R: [W3C 约定的 WebDriver 协议](https://bbs.csdn.net/topics/618658159)
R: [Selenium](https://bbs.csdn.net/topics/618658159)
### Chrome DevTools Protocol(谷歌开发者工具协议)
该协议最初是由谷歌开发者工具团队维护的,负责**调试**、**操作浏览器**的协议。目前,现代大多数浏览器都支持谷歌开发者工具协议。我们经常使用到的谷歌浏览器的开发者工具(快捷键 CTRL + SHIFT + I 或者 F12)就是使用这个协议来操作浏览器的。
查看谷歌开发者工具与浏览器交互的协议的方式是:
* 打开谷歌浏览器,在开发者工具 →设置→ 实验中勾选 Protocol Monitor(协议监视器)。
* 我们要重启开发者工具,在右侧点击更多工具,这样就可以看到协议监视器面板了。
* 面板中有开发者工具通过协议与浏览器交互的细节。
与 Selenium 需要与浏览器驱动进行交互不同的是,Chrome DevTools 协议直接通过** Web Socket **协议与浏览器暴露的 API 进行通信,这使得 Chrome DevTools 协议操作浏览器变得更快。
在 Go 中实现了 Chrome DevTools 协议的知名第三方库是[chromedp](https://bbs.csdn.net/topics/618658159)。它的操作简单,也不需要额外的依赖。借助[chromedp](https://bbs.csdn.net/topics/618658159) 提供的能力与浏览器交互,我们就具有了许多灵活的能力,例如截屏、模拟鼠标点击、提交表单、下载 / 上传文件等。[chromedp](https://bbs.csdn.net/topics/618658159) 的一些操作样例你可以参考[example](https://bbs.csdn.net/topics/618658159) 代码库。
### 模拟鼠标点击事件
假设我们访问[Go time 包的说明文档](https://bbs.csdn.net/topics/618658159),例如 After 函数,会发现下图的参考代码是折叠的。
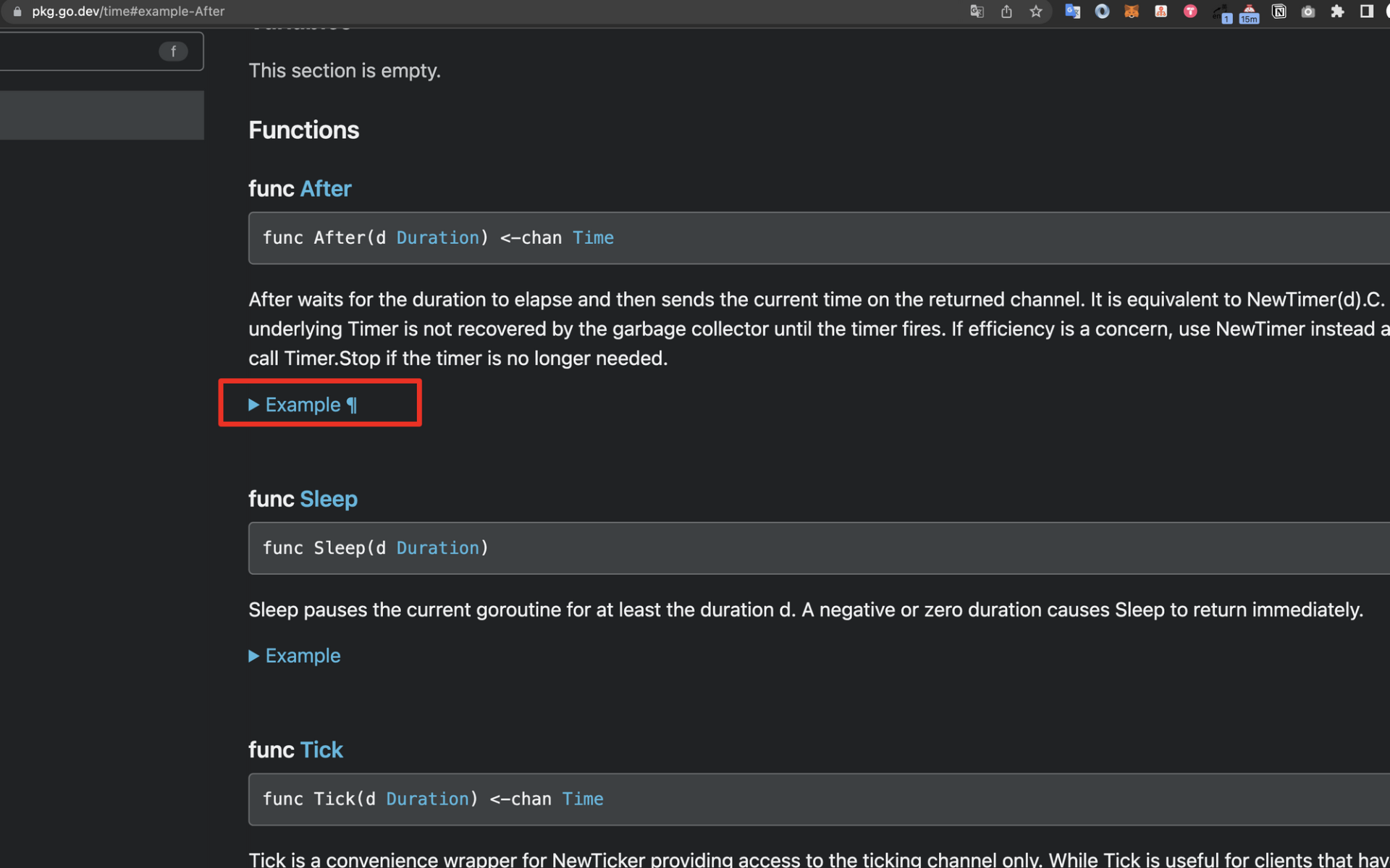
通过鼠标点击,折叠的代码可以展示出 time.After 函数的参考代码。
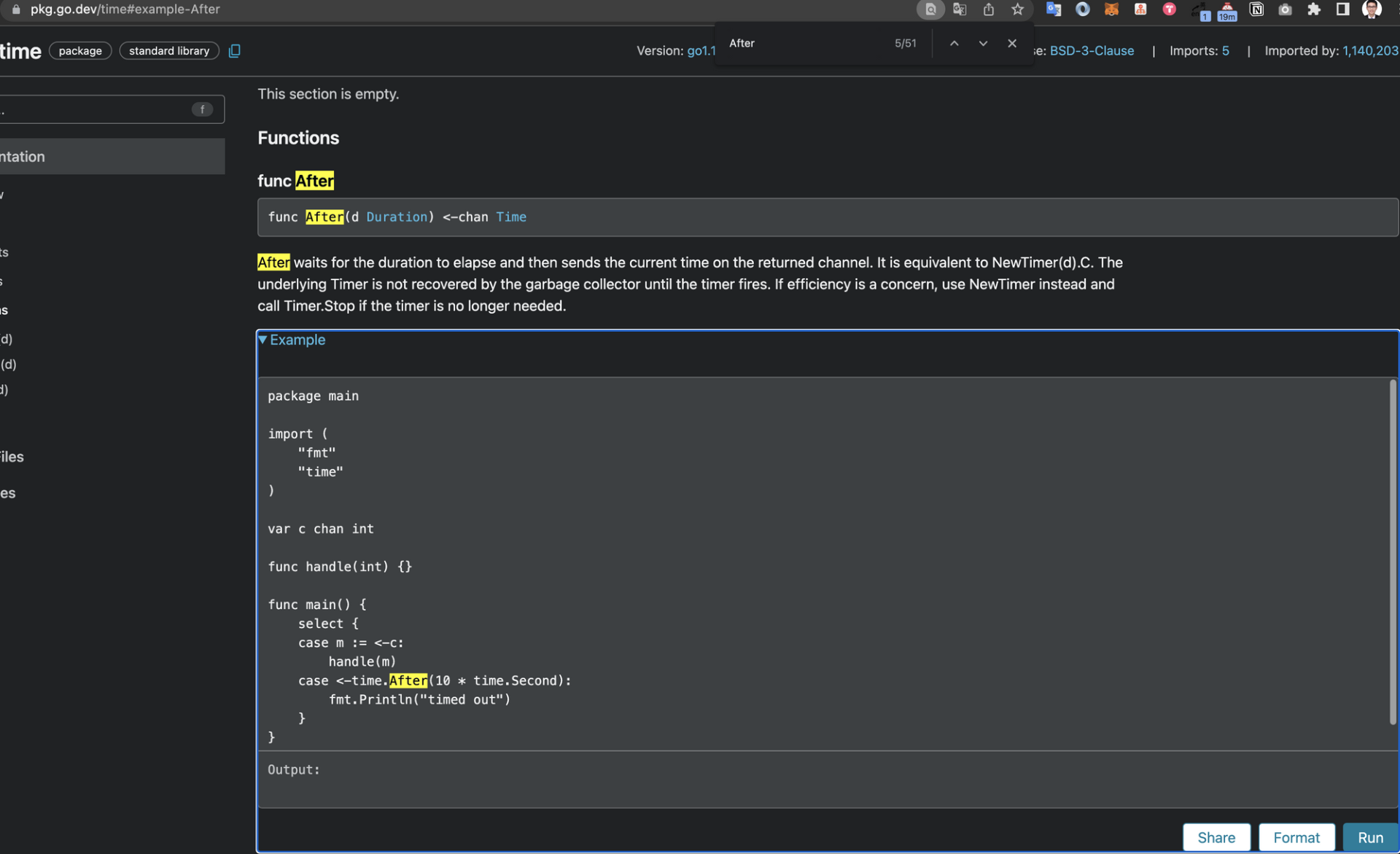
我们经常面临这种情况,即需要完成一些交互才能获取到对应的数据。要模拟上面的完整操作,代码如下所示:
package main
import (
“context”
“log”
“time”
“github.com/chromedp/chromedp”
)
func main() {
// 1、创建谷歌浏览器实例
ctx, cancel := chromedp.NewContext(
context.Background(),
)
defer cancel()
// 2、设置context超时时间
ctx, cancel = context.WithTimeout(ctx, 15*time.Second)
defer cancel()
// 3、爬取页面,等待某一个元素出现,接着模拟鼠标点击,最后获取数据
var example string
err := chromedp.Run(ctx,
chromedp.Navigate(https://pkg.go.dev/time),
chromedp.WaitVisible(body > footer),
chromedp.Click(#example-After, chromedp.NodeVisible),
chromedp.Value(#example-After textarea, &example),
)
if err != nil {
log.Fatal(err)
}
log.Printf(“Go’s time.After example:\n%s”, example)
}
* 首先我们导入了 chromedp 库,并调用 chromedp.NewContext 为我们创建了一个浏览器的实例。
实现原理: 查找当前系统指定路径下指定的谷歌应用程序,并默认用无头模式(Headless 模式)启动谷歌浏览器实例。
通过无头模式,我们肉眼不会看到谷歌浏览器窗口的打开过程,但它确实已经在后台运行了。
func findExecPath() string {
var locations []string
switch runtime.GOOS {
case “darwin”:
locations = []string{
// Mac
“/Applications/Chromium.app/Contents/MacOS/Chromium”,
“/Applications/Google Chrome.app/Contents/MacOS/Google Chrome”,
}
case “windows”:
locations = []string{
// Windows
“chrome”,
“chrome.exe”, // in case PATHEXT is misconfigured
C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe,
C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe,
filepath.Join(os.Getenv(“USERPROFILE”), AppData\\Local\\Google\\Chrome\\Application\\chrome.exe),
filepath.Join(os.Getenv(“USERPROFILE”), AppData\\Local\\Chromium\\Application\\chrome.exe),


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
e\Chrome\Application\chrome.exe, filepath.Join(os.Getenv("USERPROFILE"), AppData\Local\Google\Chrome\Application\chrome.exe), filepath.Join(os.Getenv("USERPROFILE"), AppData\Local\Chromium\Application\chrome.exe`),
[外链图片转存中…(img-3xxXuo5p-1715557639391)]
[外链图片转存中…(img-agS1KkAr-1715557639392)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









