










既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
console.log(quickSort(items));
#### 4. 桶排序
**桶排序**是一种对均匀分布的数据进行排序的有用算法,它可以很容易地并行化以提高性能。
桶排序的基本步骤包括:
1. 创建一个空桶数组。
2. 根据定义的函数将输入数据分散到桶中。
3. 使用另一种算法或递归地使用桶排序对每个桶进行排序。
4. 将每个桶中排序的元素收集到原始数组中

元素被分配到各个 bin 中,然后在每个 bin 中对元素进行排序。
##### 桶排序的历史
桶排序在 20 世纪50年代就已经实现了,有[消息]( )称这种方法在 20 世纪 40 年代就已经出现了。
不管怎样,如今它仍在广泛使用。
##### 桶排序的优点
* 它对于均匀分布的数据是有效的,平均情况的时间复杂度为 *O(n+k)*,其中 n 为元素的数量, k 为存储桶的数量。
* 它可以很容易地并行化,从而利用现代处理器中的多核。
* 它是稳定的,这意味着它保留了原始数组中相等元素的相对顺序。
* 它可以通过调整桶函数用于非均匀分布的数据。
>
> **说明**: *O(n+k)*时间复杂度 *O(n^2)*、*O(n^{3/2})*、*O(n^{4/3})* 和 *O(nlogn)* 更有效。这是因为它只需要执行线性数量的操作,而不管输入的大小。
>
>
>
例如,考虑一个对数字数组排序的算法。使用 *O(n^2)* 算法对一个包含十个数字的数组进行排序可能需要 1 秒,使用 *O(n^{3/2})* 算法对同一个数组进行排序可能需要 0.5 秒,使用 *O(nlogn)* 算法对同一个数组进行排序可能需要 0.1 秒,但是 *O(n+k)* 使用算法对同一个数组进行排序可能需要 0.05秒。这是因为该算法不需要执行那么多比较。
##### 桶排序的缺点
对于非均匀分布的数据,桶排序的效率低于其他排序算法,最坏情况下的性能为 *O(n^2)*。此外,它需要额外的内存来存储桶,这对于非常大的数据集来说可能是一个问题。
##### 桶排序的用处
就像**快速排序**一样,桶排序可以很容易地并行化并用于外部排序,但是桶排序在处理均匀分布的数据时特别有用。
* **对浮点数进行排序:**在这种情况下,范围被划分为固定数量的存储桶,每个存储桶代表输入数据的一个子范围。然后将数字放入相应的存储桶中,并使用另一种算法(例如插入排序)进行[排序]( )。最后,将排序后的数据连接成一个数组。
* **对字符串进行排序:**字符串根据字符串的第一个字母分组到存储桶中。然后,使用另一种算法对每个存储桶中的字符串进行排序,或使用存储桶排序进行递归排序。对字符串中的每个后续字母重复此过程,直到对整个集合进行排序。
* **直方图生成:**这可用于生成数据直方图,直方图用于表示一组值的频率分布。在这种情况下,将数据范围划分为固定数量的存储桶,并计算每个存储桶中的值个数。生成的直方图可用于可视化数据的分布。
##### 桶排序的实现
1. 将列表分成“桶”。
2. 每个桶使用不同的排序算法进行排序。
3. 然后将桶合并回一个排序列表。
Python 桶排序代码示例
def bucket_sort(items):
buckets = [[] for _ in range(len(items))]
for item in items:
bucket = int(item/len(items))
buckets[bucket].append(item)
for bucket in buckets:
bucket.sort()
return [item for bucket in buckets for item in bucket]
items = [6,20,8,19,56,23,87,41,49,53]
print(bucket_sort(items))
Javascript 桶排序代码示例
function bucketSort(items) {
let buckets = new Array(items.length);
for (let i = 0; i < buckets.length; i++) {
buckets[i] = [];
}
for (let j = 0; j < items.length; j++) {
let bucket = Math.floor(items[j] / items.length);
buckets[bucket].push(items[j]);
}
for (let k = 0; k < buckets.length; k++) {
buckets[k].sort();
}
return [].concat(…buckets);
}
let items = [6, 20, 8, 19, 56, 23, 87, 41, 49, 53];
console.log(bucketSort(items));
#### 5. Shell 排序
Shell 排序使用**插入排序**算法,但不是一次对整个列表排序,而是将列表分成更小的子列表。然后使用插入排序算法对这些子列表进行排序,从而减少排序列表所需的交换次数。
它的工作原理是首先定义一个称为增量序列的整数序列。增量序列用于确定将独立排序的子列表的大小。最常用的增量序列是“Knuth序列”,其定义如下(其中 h 为具有初始值的区间,n是列表的长度):
h = 1
while h < n:
h = 3*h + 1
一旦定义了自增序列,Shell 排序算法就会对元素的子列表进行排序。子列表使用**插入排序**算法排序,以增量序列作为步长。该算法对子列表进行排序,从最大的增量开始,然后迭代到最小的增量。
该算法在增量大小为 1 时停止,此时它相当于常规的插入排序算法。

##### Shell 排序的历史
Shell排序是由 Donald Shell 于 1959 年发明的,是**插入排序**的一种变体,旨在通过将原始列表分解成更小的子列表并对这些子列表独立排序来提高其性能。
##### Shell 排序的优点
* 它是插入排序的泛化,因此易于理解和实现。
* 它的时间复杂度比很多输入数据序列*O(n^2)* 都要好。
* 它是一种就地排序算法,这意味着它不需要额外的内存。
##### Shell 排序的缺点
很难预测 Shell 排序的时间复杂度,因为它取决于增量序列的选择。
##### Shell 排序的用处
Shell 排序是一种通用算法,用于在各种应用程序中对数据进行排序,特别是在对大型数据集(利用**快速排序**和**桶排序**)进行排序时。
* **对主要排序的数据进行排序:**Shell 排序减少了对数据进行排序所需的比较和交换次数。这使得它比其他排序算法(如**快速排序**或**归并排序**)在特定情况下更快。
* **对具有少量反转的数组进行排序:**反转是衡量数组未排序程度的指标,定义为顺序错误的元素对数。在对具有少量反转的数组进行排序时,Shell 排序比其他一些算法(如**冒泡排序**或**插入排序**)更有效。
* **就地排序:**Shell 排序不需要额外的内存来对输入进行排序,使其成为就地排序的竞争者。这使得它在内存有限或不需要额外内存使用的情况下很有用。
* **在分布式环境中进行排序:**通过将输入数据划分为较小的子列表并独立排序,可以在单独的处理器或节点上对每个子列表进行排序,从而减少对数据进行排序所需的时间。
##### Shell 排序的实现
###### Python Shell 排序代码示例
def shell_sort(items):
sublistcount = len(items)//2
while sublistcount > 0:
for start in range(sublistcount):
gap_insertion_sort(items, start, sublistcount)
sublistcount = sublistcount // 2
return items
def gap_insertion_sort(items, start, gap):
for i in range(start+gap, len(items), gap):
currentvalue = items[i]
position = i
while position >= gap and items[position-gap] > currentvalue:
items[position] = items[position-gap]
position = position-gap
items[position] = currentvalue
items = [6,20,8,19,56,23,87,41,49,53]
print(shell_sort(items))
###### Javascript Shell 排序代码示例
function shellSort(items) {
let sublistcount = Math.floor(items.length / 2);
while (sublistcount > 0) {
for (let start = 0; start < sublistcount; start++) {
gapInsertionSort(items, start, sublistcount);
}
sublistcount = Math.floor(sublistcount / 2);
}
return items;
}
function gapInsertionSort(items, start, gap) {
for (let i = start + gap; i < items.length; i += gap) {
let currentValue = items[i];
let position = i;
while (position >= gap && items[position - gap] > currentValue) {
items[position] = items[position - gap];
position = position - gap;
}
items[position] = currentValue;
}
}
let items = [6, 20, 8, 19, 56, 23, 87, 41, 49, 53];
console.log(shellSort(items));
#### 6. 归并排序
归并排序的基本思想是将输入列表分成两半,使用归并排序对每一半进行递归排序,然后将已排序的两半合并回一起。合并步骤是通过重复比较每一半的第一个元素并将两个元素中较小的元素添加到排序列表中来执行的。这个过程不断重复,直到所有的元素都合并在一起。
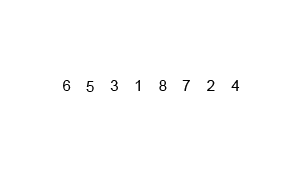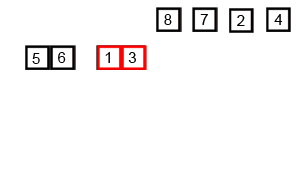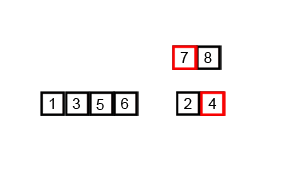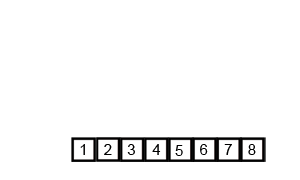
1. 首先,将列表划分为最小的单元(一个元素),
2. 然后将每个元素与相邻列表进行比较,对两个相邻列表进行排序和合并。
3. 最后,对所有元素进行排序和合并。
##### 归并排序的历史
归并排序是由约翰·冯·诺伊曼于 1945 年发明的,作为一种基于比较的排序算法,它通过将输入列表划分为更小的子列表,对这些子列表进行递归排序,然后将它们合并在一起产生最终排序列表。
##### 归并排序的优点
在最坏的情况下,归并排序的时间复杂度为O(nlogn),这使得它比**冒泡排序**、**插入排序**或**选择排序**等其他流行的排序算法更有效。
归并排序也是一种算法,这意味着它保留相等元素的相对顺序。
##### 归并排序的缺点
归并排序在内存使用方面有一些缺点。该算法在除法步骤中需要额外的内存来存储列表的两半,在合并步骤中需要额外的内存来存储最终排序的列表。在对非常大的列表进行排序时,这可能是一个问题。
##### 归并排序的用处
归并排序是一种通用排序算法,可以并行化排序大型数据集和外部排序(如**快速排序**和**桶排序**),它也通常用作更复杂算法(如**冒泡排序**和**插入排序**)的基础。
* **稳定的排序:**合并排序的[稳定排序]( )意味着它保留了相等元素的相对顺序。这使得它在保持相等元素的顺序很重要的情况下很有用,例如在金融应用程序中或出于可视化目的对数据进行排序时。
* **实现二进制搜索:**它用于有效地搜索排序列表中的特定元素,因为它依赖于排序的输入。合并排序可用于有效地对二进制搜索和其他类似算法的输入进行排序。
##### 归并排序的实现
1. 使用递归将列表拆分为更小的排序子列表。
2. 将子列表重新合并在一起,在合并时对项目进行比较和排序。
###### Python 归并排序代码示例
def merge_sort(items):
if len(items) <= 1:
return items
mid = len(items) // 2
left = items[:mid]
right = items[mid:]
left = merge_sort(left)
right = merge_sort(right)
return merge(left, right)
def merge(left, right):
merged = []
left_index = 0
right_index = 0
while left_index < len(left) and right_index < len(right):
if left[left_index] > right[right_index]:
merged.append(right[right_index])
right_index += 1
else:
merged.append(left[left_index])
left_index += 1
merged += left[left_index:]
merged += right[right_index:]
return merged
items = [6,20,8,19,56,23,87,41,49,53]
print(merge_sort(items))
###### Javascript 归并排序代码示例
function mergeSort(items) {
if (items.length <= 1) {
return items;
}
let mid = Math.floor(items.length / 2);
let left = items.slice(0, mid);
let right = items.slice(mid);
return merge(mergeSort(left), mergeSort(right));
}
function merge(left, right) {
let merged = [];
let leftIndex = 0;
let rightIndex = 0;
while (leftIndex < left.length && rightIndex < right.length) {
if (left[leftIndex] > right[rightIndex]) {
merged.push(right[rightIndex]);
rightIndex++;
} else {
merged.push(left[leftIndex]);
leftIndex++;
}
}
return merged.concat(left.slice(leftIndex)).concat(right.slice(rightIndex));
}
let items = [6, 20, 8, 19, 56, 23, 87, 41, 49, 53];
console.log(mergeSort(items));
#### 7. 选择排序
选择排序反复从列表的未排序部分中选择最小的元素,并将其与未排序部分的第一个元素交换。这个过程一直持续到整个列表排序完毕。
红色是当前最小值,黄色是排序列表,蓝色是当前项目。
##### 选择排序的历史
选择排序是一种简单而直观的排序算法,从计算机科学的早期开始就存在了。类似的算法很可能是在 20 世纪 50 年代由研究人员独立开发的。
它是最早开发的排序算法之一,并且它仍然是用于教育目的和简单排序任务的流行算法。
##### 选择排序的优点
选择排序在某些应用程序中使用,在这些应用程序中,简单性和易于实现比效率更重要。它还可以作为一种教学工具,用于向学生介绍排序算法及其属性,因为它易于理解和实现。
##### 选择排序的缺点
尽管它很简单,但与其他排序算法(如**归并排序**或**快速排序**)相比,选择排序不是很有效。它的最坏情况下的时间复杂度为 *O(n^2)*,对大列表进行排序可能需要很长时间。
选择排序也不是一种稳定的排序算法,这意味着它可能无法保持相等元素的顺序。
##### 选择排序的用处
选择排序类似于**冒泡排序**和**插入排序**,因为它可以用来对小数据集进行排序,而且它的简单性也使它成为教育和学习排序算法的有用工具。其他用途包括:
* **使用有限的内存对数据进行排序:**它只需要恒定量的额外内存来执行排序,因此在内存使用有限的情况下很有用。
* **使用唯一值对数据进行排序:**它不依赖于主要排序的输入,因此对于具有唯一值的数据集来说,它是一个不错的选择,而其他排序算法可能必须执行额外的检查或优化。
##### 选择排序的实现
1. 遍历列表,选择最小的项。
2. 将最小的项与当前位置项交换。
3. 对列表的其余部分重复此过程。
###### Python 选择排序代码示例
def selection_sort(items):
for i in range(len(items)):
min_idx = i
for j in range(i+1, len(items)):
if items[min_idx] > items[j]:
min_idx = j
items[i], items[min_idx] = items[min_idx], items[i]
return items
items = [6,20,8,19,56,23,87,41,49,53]
print(selection_sort(items))
###### Javascript 选择排序代码示例
function selectionSort(items) {
let minIdx;
for (let i = 0; i < items.length; i++) {
minIdx = i;
for (let j = i + 1; j < items.length; j++) {
if (items[j] < items[minIdx]) {
minIdx = j;
}
}
let temp = items[i];
items[i] = items[minIdx];
items[minIdx] = temp;
}
return items;
}
let items = [6, 20, 8, 19, 56, 23, 87, 41, 49, 53];
console.log(selectionSort(items));
#### 8. 基数排序
基数排序的基本思想是通过按被排序的数字或字符中的每个数字分组来对数据进行排序,从右到左或从左到右。对每个数字重复这个过程,得到一个排序列表。
其最坏情况性能为 *O(w\*cdotn)*,其中 n 为 key 数量,为 w 为键长度。
##### 基数排序的历史
基数排序最早是由 Herman Hollerith 在 19 世纪末引入的,作为一种有效地对打孔卡片上的数据进行排序的方法,打孔卡片上的每一列代表数据中的一个数字。
后来,在 20 世纪中期,一些研究人员对它进行了改编和推广,通过按二进制表示中的每个比特对数据进行分组来对二进制数据进行排序。但它也用于对字符串数据进行排序,其中每个字符在排序中被视为数字。
近年来,基数排序作为并行和分布式计算环境的排序算法重新引起了人们的兴趣,因为它很容易并行化,并且可以用于以分布式方式对大型数据集进行排序。

**一种 IBM 卡片分类器,对大量打孔卡片执行基数排序**
##### 基数排序的优点
基数排序是一种线性时间排序算法,这意味着它的时间复杂度与输入数据的大小成正比。这使得它成为对大型数据集进行排序的有效算法,尽管对于较小的数据集,它可能不如其他排序算法那么有效。
它的线性时间复杂度和稳定性使它成为对大型数据集排序的有用工具,它的并行性使它对分布式计算环境中的数据排序很有用。
基数排序也是一种稳定的排序算法,这意味着它保留相等元素的相对顺序。
##### 基数排序的用处
基数排序可用于需要对大型数据集进行高效排序的各种应用程序。它对于排序字符串数据和固定长度的键特别有用,也可以用于并行和分布式计算环境。
**并行处理:**基数排序通常更适合于对大型数据集进行排序(优于**归并排序**、**快速排序**和**桶排序**)。像桶排序一样,基数可以有效地对字符串数据进行排序,这使得它适合于自然语言处理应用程序。
**用固定长度的键排序数据:**基数排序在对具有固定长度键的数据进行排序时特别有效,因为它可以通过每次检查每个键的一个数字来执行排序。
##### 基数排序的实现
1. 比较列表中每一项的数字。
2. 按数字分组。
3. 按大小对组进行排序。
4. 递归地对每个组进行排序,直到每个项都在正确的位置。
###### Python 基数排序代码示例
def radix_sort(items):
max_length = False
tmp, placement = -1, 1
while not max_length:
max_length = True
buckets = [list() for _ in range(10)]
for i in items:
tmp = i // placement
buckets[tmp % 10].append(i)
if max_length and tmp > 0:
max_length = False
a = 0
for b in range(10):
buck = buckets[b]
for i in buck:
items[a] = i
a += 1
placement *= 10
return items
items = [6,20,8,19,56,23,87,41,49,53]
print(radix_sort(items))
###### Javascript 基数排序代码示例
function radixSort(items) {
let maxLength = false;
let tmp = -1;
let placement = 1;
while (!maxLength) {
maxLength = true;
let buckets = Array.from({ length: 10 }, () => []);
for (let i = 0; i < items.length; i++) {
tmp = Math.floor(items[i] / placement);
buckets[tmp % 10].push(items[i]);
if (maxLength && tmp > 0) {
maxLength = false;
}
}
let a = 0;
for (let b = 0; b < 10; b++) {
let buck = buckets[b];
for (let j = 0; j < buck.length; j++) {
items[a] = buck[j];
a++;
}
}
placement *= 10;
}
return items;
}
let items = [6, 20, 8, 19, 56, 23, 87, 41, 49, 53];
console.log(radixSort(items));
#### 9. 梳子排序
梳子排序比较相隔一定距离的元素对,如果它们顺序不一致,就交换它们。对之间的距离最初设置为正在排序的列表的大小,然后在每次传递时减少一个因子(称为“收缩因子”),直到达到最小值 1。重复这个过程,直到列表被完全排序。
梳子排序算法类似于**冒泡排序**算法,但比较元素之间的间隙更大。这个较大的间隙允许较大的值更快地移动到列表中的正确位置。
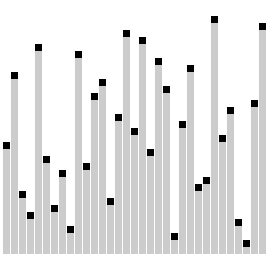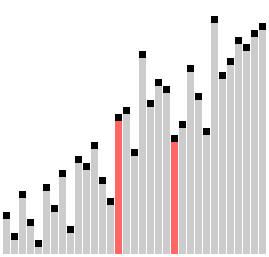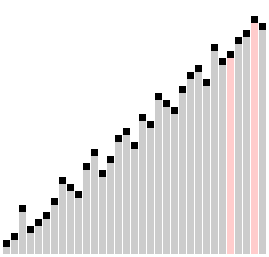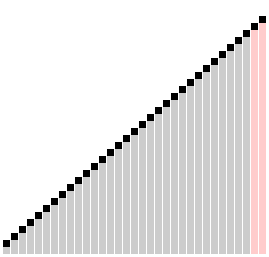
##### 梳子排序的历史
梳状排序算法是一种相对较新的排序算法,于 1980 年由 Włodzimierz Dobosiewicz 和Artur Borowy 首次提出。该算法的灵感来自于使用梳子理顺纠结的头发的想法,它使用类似的过程来理顺未排序的值列表。
##### 梳子排序的优点
梳子排序的最坏情况时间复杂度为 *O(n^2)*,但在实践中它通常比其他排序算法(如冒泡排序)快,因为它使用了收缩因子。收缩因子允许算法快速将大值移动到正确的位置,减少完全排序列表所需的传递次数。
##### 梳子排序的用处
梳子排序是一种相对简单和有效的排序算法,在各种应用程序中:
* **排序具有大范围值的数据**:在比较元素之间使用更大的间距可以让更大的值更快地移动到列表中的正确位置。
* **在实时应用程序中排序数据**:梳子排序是一种稳定的排序算法,它保持了相等元素的相对顺序。这对于需要保留相等元素的顺序的实时应用程序中的数据排序非常有用。
* **在内存受限的环境中排序数据**:梳子排序不需要额外的内存来对数据进行排序。这对于在内存受限的环境中对数据进行排序非常有用,因为在这种环境中没有额外的内存可用。
##### 梳子排序的实现
1. 从列表之间最大长度开始。
2. 比较间隔末端的项,如果顺序不对就交换它们。
3. 减小间隙并重复此过程,直到间隙为 1
4. 最后对剩下的项进行冒泡排序。
###### Python 梳子排序代码示例
def comb_sort(items):
gap = len(items)
shrink = 1.3
sorted = False
while not sorted:
gap //= shrink
if gap <= 1:
sorted = True
else:
for i in range(len(items)-gap):
if items[i] > items[i+gap]:
items[i],items[i+gap] = items[i+gap],items[i]
return bubble_sort(items)
def bubble_sort(items):
for i in range(len(items)):
for j in range(len(items)-1-i):
if items[j] > items[j+1]:
items[j], items[j+1] = items[j+1], items[j]
return items
items = [6,20,8,19,56,23,87,41,49,53]
print(comb_sort(items))
###### Javascript 梳子排序代码示例
function combSort(items) {
let gap = items.length;
let shrink = 1.3;
let sorted = false;
while (!sorted) {
gap = Math.floor(gap / shrink);
if (gap <= 1) {
sorted = true;
} else {
for (let i = 0; i < items.length - gap; i++) {
if (items[i] > items[i + gap]) {
let temp = items[i];
items[i] = items[i + gap];
items[i + gap] = temp;
}
}
}
}
return bubbleSort(items);
}
function bubbleSort(items) {
let swapped;
do {
swapped = false;
for (let i = 0; i < items.length - 1; i++) {
if (items[i] > items[i + 1]) {
let temp = items[i];
items[i] = items[i + 1];
items[i + 1] = temp;
swapped = true;
}
}
} while (swapped);
return items;
}
let items = [6, 20, 8, 19, 56, 23, 87, 41, 49, 53];
console.log(combSort(items));
#### 10. Timsort
Timsort 算法的工作原理是将输入数据分成更小的子数组,然后使用插入排序对这些子数组进行排序。然后使用归并排序将这些排序的子数组组合起来,以产生一个完全排序的数组。
Timsort的最坏情况时间复杂度为 *O(nlogn)*,这使得它对大型数据集的排序效率很高。它也是一种稳定的排序算法,这意味着它保留了相等元素的相对顺序。
##### Timsort 的历史
Timsort 是由 Tim Peters 在2002年为 Python 编程语言开发的。它是一种混合排序算法,结合使用插入排序和归并排序技术,旨在有效地对各种不同类型的数据进行排序。
由于它在处理不同类型数据方面的效率和通用性,它已经被其他几种编程语言所采用,包括Java和c#。
##### Timsort 的优点
Timsort 的一个关键特性是它能够有效地处理不同类型的数据。它通过检测“runs”来实现这一点,“runs”是已经排序的元素序列。Timsort 然后以一种最小化生成完全排序数组所需的比较和交换次数的方式组合这些运行。
Timsort 的另一个重要特性是它能够处理部分排序的数据。在这种情况下,Timsort 可以检测部分排序的区域,并使用插入排序对其进行快速排序,从而减少对数据进行完全排序所需的时间。
##### Timsort 的用处
作为一种高级算法,Timsort 可以用于在内存受限的系统上对数据进行排序。
**编程语言中的排序:**Timsort 通常被用作这些语言中的默认排序算法,因为它具有处理不同类型数据的效率和能力。
整理数据:Timsort 在对可能部分排序或包含已经排序的子数组的实际数据进行排序时特别高效,因为它能够检测这些运行并使用**插入排序**对它们进行**快速排序**,从而减少对数据进行完全排序所需的时间。
**对不同类型的数据进行排序:**它旨在有效地处理不同类型的数据,包括数字、字符串和自定义对象。它可以检测具有相同类型的数据运行,并使用**归并排序**有效地组合它们,减少所需的比较和交换次数。
##### Timsort 的实现
1. 将一个未排序的列表分解成更小的、排序的子列表。
2. 合并子列表以形成更大的排序列表。
3. 重复这个过程,直到整个列表排序完毕。
###### Python Timsort代码示例
def insertion_sort(arr, left=0, right=None):
if right is None:
right = len(arr) - 1
for i in range(left + 1, right + 1):
key_item = arr[i]
j = i - 1
while j >= left and arr[j] > key_item:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key_item
return arr
def merge(left, right):
if not left:
return right
if not right:
return left
if left[0] < right[0]:
return [left[0]] + merge(left[1:], right)
return [right[0]] + merge(left, right[1:])
def timsort(arr):
min_run = 32
n = len(arr)
for i in range(0, n, min_run):
insertion_sort(arr, i, min((i + min_run - 1), n - 1))
size = min_run
while size < n:
for start in range(0, n, size * 2):
midpoint = start + size - 1


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
ght):
if not left:
return right
if not right:
return left
if left[0] < right[0]:
return [left[0]] + merge(left[1:], right)
return [right[0]] + merge(left, right[1:])
def timsort(arr):
min_run = 32
n = len(arr)
for i in range(0, n, min_run):
insertion_sort(arr, i, min((i + min_run - 1), n - 1))
size = min_run
while size < n:
for start in range(0, n, size * 2):
midpoint = start + size - 1
[外链图片转存中…(img-PmFhubN6-1715593884474)]
[外链图片转存中…(img-InfVYvAz-1715593884474)]
[外链图片转存中…(img-QBTv1aBH-1715593884475)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









