






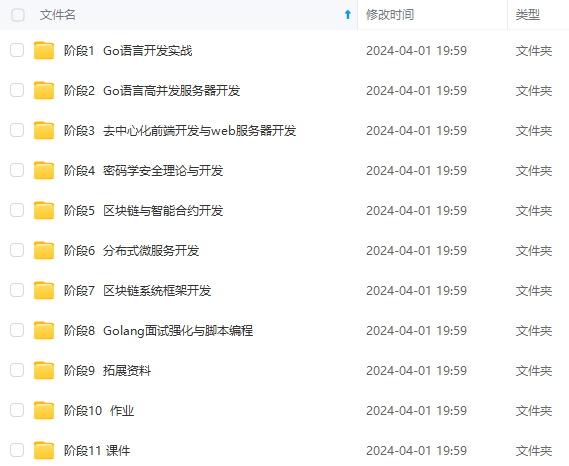
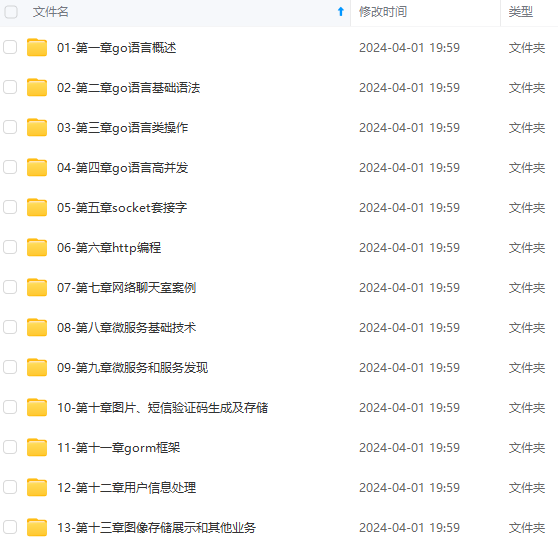
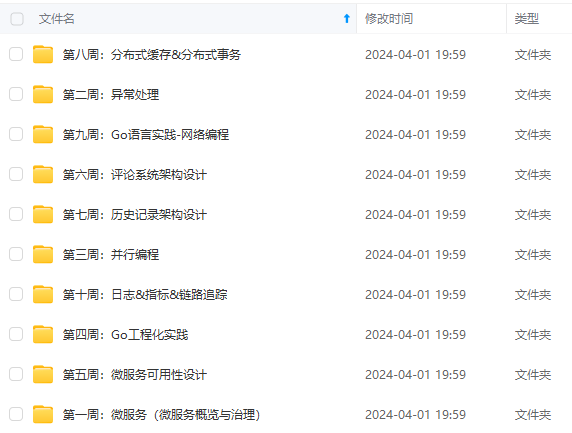
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
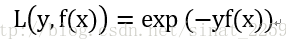
很好理解,预测正确了yf(x)为正值,损失函数值就小,预测错误yf(x)为正值,损失函数值较大,然后我们来看一下第m步的损失函数
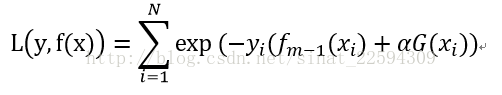
现在就是分别求alpha和G(x)使得损失函数最小值,按照之前的想法,直接算伪残差然后用G(x)拟合,不过这边我们先不着急。指数项中,yi与fm-1的乘积是不依赖于alpha和G(x)的,所以可以提出来不用考虑,对于任意alpha>0,在exp(-yi*fm-1)权值分布下,要exp(-yi*alpha*G(x))取最小值,也就是要G(x)对加权y预测的正确率最高。接下来,求alpha很愉快,直接求导位0,懒癌发作,公式推导过程就不打了,最后的结果如下:
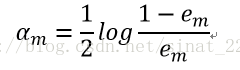
得到了参数之后就能愉快的迭代,使得训练数据上的正确率蹭蹭蹭地往上涨。
再回过头来看看AdaBoost的标准做法和我们推导的是否一致
1 第一步假设平均分布,权值都为1/N,训练数据得到分类器。
2 求第一步的分类器预测数据的错误率,计算G(x)的系数alpha。
3 更新权值分布,不过加了归一化因子,使权值满足概率分布。
4 基于新的权值分布建立新的分类器,累加在之前的模型中。
5 重复上述步骤,得到最终的分类器。
可以看出,除了在更新权值分布处加了一个归一化因子之外,其他的都和我们推导的一样,所以,所以什么呀……你不仅会用还会推导啦?O(∩_∩)O哈哈~
第三个,XGBoost。
其实说白了也很简单,之前用的梯度下降的方法我们都只考虑了一阶信息,根据泰勒展开,
我们可以把二阶信息也用上,假如目标函数如下
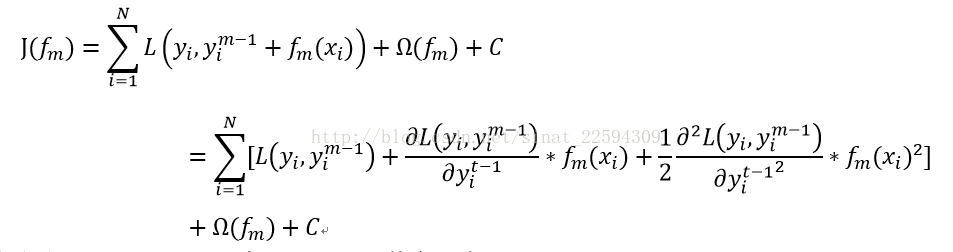
啊啊啊,这公式打得我真要吐血了。其中Ω为正则项,正如上面讲的,可表示如下
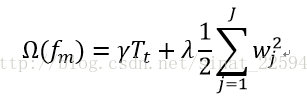
然后对于决策树而言,最重要的就是一共有多少个节点以及每个节点的权值,所以决策树可以表示为
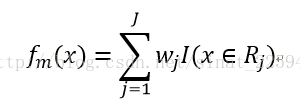
这样就有了下一步的推导,鉴于它实在是太长了,我就直接截图了
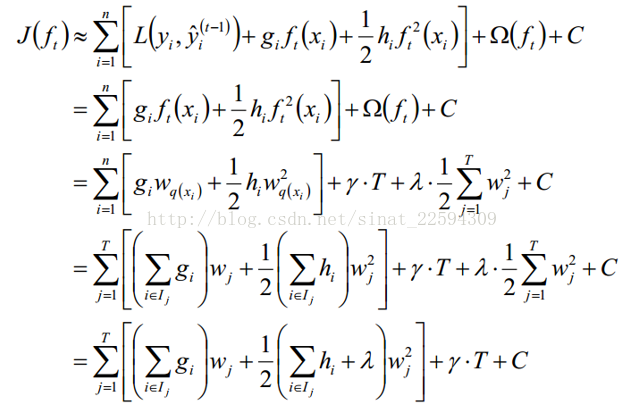
第二步是因为不管fm如何取值第一项的值都不变,所以优化过程中可以不用考虑,第三步是因为对于每个样本而言其预测值就是对应输入空间对应的权值,第四步则是把样本按照划分区域重新组合,然后定义
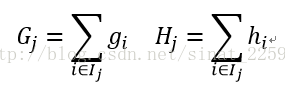
带入对w求偏导使其为0,这样就求得了
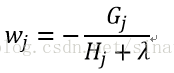
再回代,就可以把J(fm)中的w给消去了,得到了
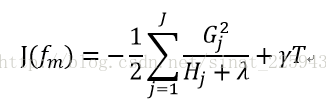
这样我们就把新一步函数的损失函数变成了只与上一步相关的一个新的损失函数,这样我们就可以遍历数据中所有的分割点,寻找新的损失函数下降最多的分割点,然后重复上述操作。
相比于梯度下降提升,XGBoost在划分新的树的时候还是用了二阶信息,因此能够更快地收敛,而且XGBoost包是用C/C++写的,所以速度更快,而且在寻找最佳分割点的时候,可以引入并行计算,因此速度进一步提高,广受各大竞赛参赛者的喜爱啊。
说到现在的理论推导,有耐心看到这里的少年我只能说你接近成功了,Boost算法要被你拿下了,接下来我们就来一把实战试试。
Sklearn中有GDBT和AdaBoost算法,它用的方法和前面的Bagging什么的一模一样,具体的参数设置大家可以参考帮助,这里给出一个简单的例子,没错,又是那个鸢尾花,它又来了,用它的前两个特征进行训练,我们来看看训练集上的正确率,按道理,Boost算法在训练集上的效果应该是十分卓越的,毕竟它有过拟合的趋势啊。
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import AdaBoostClassifier
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn import datasets
iris=datasets.load_iris()
x=iris.data[:,:2]
y=iris.target
model1=DecisionTreeClassifier(max_depth=5)
model2=GradientBoostingClassifier(n_estimators=100)
model3=AdaBoostClassifier(model1,n_estimators=100)
model1.fit(x,y)
model2.fit(x,y)
model3.fit(x,y)
model1_pre=model1.predict(x)
model2_pre=model2.predict(x)
model3_pre=model3.predict(x)
res1=model1_pre==y
res2=model2_pre==y
res3=model3_pre==y
print '决策树训练集正确率%.2f%%'%np.mean(res1*100)
print 'GDBT训练集正确率%.2f%%'%np.mean(res2*100)
print 'AdaBoost训练集正确率%.2f%%'%np.mean(res3*100)
输出为
决策树训练集正确率84.67%
GDBT训练集正确率92.00%
AdaBoost训练集正确率92.67%
在训练集上表现全是很好啊,在测试集上就不好说了,但有一句话说的好,过拟合总比欠拟合好啊……没事儿,还有调参大法,根据自己的需要去试试就好了。
XGBoost在sklearn里没有,所以需要额外安装一下,我是按照这个网址的教程这里,亲测有效,只有一步,就是在安装MinGW-W64的时候这个博客里提供的地址下载下来安装总是失败,大家去官网下一个就行,其他的按照教程一步一步做就行了,没什么其他的幺蛾子。
所以,又是鸢尾花登场了
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn import datasets
iris=datasets.load_iris()
x=iris.data[:,:2]
y=iris.target
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.7, random_state=1)
data_train = xgb.DMatrix(x_train,label=y_train)
data_test=xgb.DMatrix(x_test,label=y_test)
param = {}
param['objective'] = 'multi:softmax'
param['eta'] = 0.1
param['max_depth'] = 6
param['silent'] = 1
param['nthread'] = 4
param['num_class'] = 3
watchlist = [ (data_train,'train'), (data_test, 'test') ]
num_round = 10
bst = xgb.train(param, data_train, num_round, watchlist );
pred = bst.predict( data_test );
print ('predicting, classification error=%f' % (sum( int(pred[i]) != y_test[i] for i in range(len(y_test))) / float(len(y_test)) ))
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









