









网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
北京积分落户状况 获取数据(爬虫/文件下载)—> 分析 (维度—指标)
- 从公司维度分析不同公司对落户人数指标的影响 , 即什么公司落户人数最多也更容易落户
- 从年龄维度分析不同年龄段对落户人数指标影响 , 即什么年龄段落户人数最多也更容易落户
- 从百家姓维度分析不同姓对落户人数的指标影响 , 即什么姓的落户人数最多即也更容易落户
- 不同分数段的占比情况
# 导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager
#读取数据(文件) , 并查看数据相应结构和格式
lh_data = pd.read_csv('./bj_luohu.csv',index_col='id',usecols=(0,1,2,3,4))
lh_data.describe()

# 1. 公司维度---人数指标
# 对公司进行分组聚合 , 并查看分数的相关数据 (个数 , 总分数 , 平均分 , 人数占比)
group_company = lh_data.groupby('company',as_index=False)['score'].agg(['count','sum','mean']).sort_values('count',ascending=False)
#更改列名称
group_company.rename(columns={'count':'people_num','sum':'score_sum','mean':'score_mean'},inplace=True)
#定一个函数 , 得到占比
def num_percent(people_num=1,people_sum=1):
return str('%.2f'%(people_num / people_sum * 100))+'%'
#增加一个占比列
group_company['people_percent'] = group_company['people_num'].apply(num_percent,people_sum=lh_data['name'].count())
#查看只有一个人落户的公司 布尔索引
group_company[group_company['people_num'] == 1]
group_company.head(10)

# 2.年龄维度----人数指标
#将出生年月转为年龄
lh_data['age'] = (pd.to_datetime('2019-09') - pd.to_datetime(lh_data['birthday'])) / pd.Timedelta('365 days')
# 分桶
lh_data.describe()
bins_age = pd.cut(lh_data['age'],bins=np.arange(30,70,5))
bins_age_group = lh_data['age'].groupby(bins_age).count()
bins_age_group.index = [str(i.left) + '~' + str(i.right) for i in bins_age_group.index]
bins_age_group.plot(kind='bar',alpha=1,rot=60,grid=0.2)

# 3. 姓维度----人数指标
# 增加姓列
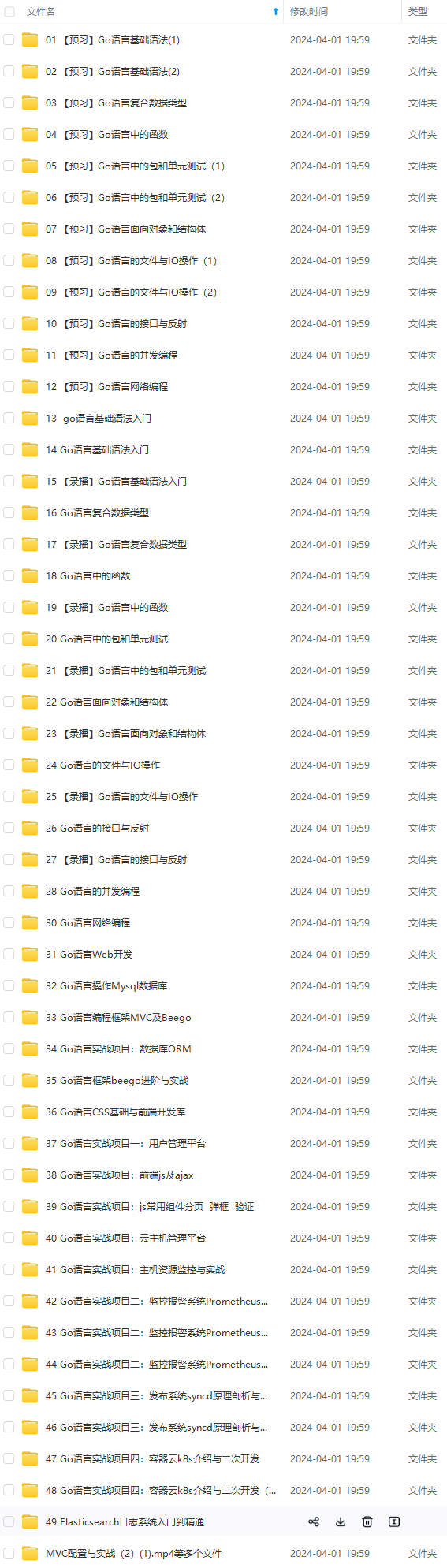
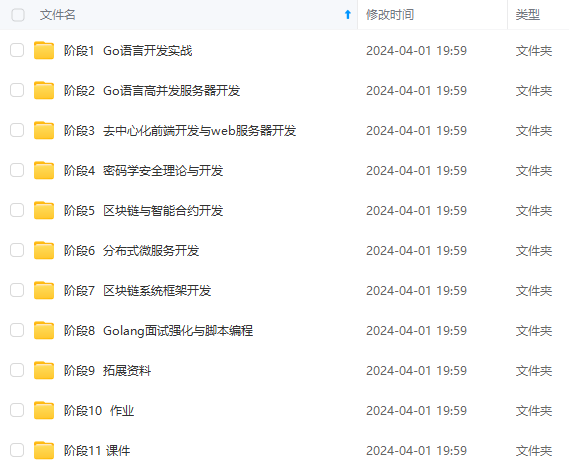
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618658159)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









