







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
因此需要内存回收,内存回收分为两种方式
1.手动释放占用的内存空间
程序代码中也可以使用runtime.GC()来手动触发GC。这主要用于GC性能测试和统计
2.自动内存回收
(一)内存分配量达到阀值触发GC
每次内存分配时都会检查当前内存分配量是否已达到阀值,如果达到阀值则立即启动GC。
阀值 = 上次GC内存分配量 * 内存增长率
内存增长率由环境变量GOGC控制,默认为100,即每当内存扩大一倍时启动GC。(二)定期触发GC
默认情况下,最长2分钟触发一次GC,这个间隔在src/runtime/proc.go:forcegcperiod变量中被声明:// forcegcperiod is the maximum time in nanoseconds between garbage // collections. If we go this long without a garbage collection, one // is forced to run. // // This is a variable for testing purposes. It normally doesn't change. var forcegcperiod int64 = 2 * 60 * 1e9首先记住三种:
go 1.3 之前采用标记清除法,需要STW(stop the world)需要暂停用户所有操作
go 1.5 采用三色标记法,插入写屏障机制(只在堆内存中生效),最后仍需对栈内存进行STW
go 1.8 采用混合写屏障机制,屏障限制只在堆内存中生效。避免了最后节点对栈进行STW的问题,提升了GC效率第一个阶段:
STW:stop the word,指程序执行过程中,中断暂停程序逻辑,专门去进行垃圾回收。标记清除法
把根数据段上的数据作为root,基于他们进行进一步的追踪,追踪到的数据就进行标记,最后把没有标记的对象当作垃圾进行释放。开启STW,
从根节点出发,标记所有可达对象
停止STW,然后回收所有未标记的对象。第二个阶段
三色标记法
其实实际应用场景是没有三色这个概念,这只是为了人们方便理解这种,抽象出来的一种说法而已,这里的三色对应的就是垃圾回收的三种状态
1、白色:初始状态下所有的对象都是白色,gcmarkBits对应的位为0(该对象会被清理)
2、灰色:对象被进行标记,但是这个对象的子对象(也就是它引用的对象)未被进行标记
3、黑色:对象被标记同时这个对象引用的子对象也被进行标记gcmarkBits对应的位为1(该对象不会被清理)始状态下所有对象都是白色的。
接着开始扫描根对象a、b:
第三阶段
三色标记——混合屏障
因为go支持并行GC, GC的扫描和go代码可以同时运行, 这样带来的问题是GC扫描的过程中go代码有可能改变了对象的依赖树。
例如开始扫描时发现根对象A和B, B拥有C的指针。
GC先扫描A,A放入黑色
B把C的指针交给A
GC再扫描B,B放入黑色
C在白色,会回收;但是A其实引用了C。
为了避免这个问题, go在GC的标记阶段会启用写屏障(Write Barrier).启用了写屏障(Write Barrier)后,在GC第三轮rescan阶段,根据写屏障标记将C放入灰色,防止C丢失。

33、说一下乐观锁和悲观锁在go中如何使用
乐观锁:乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,采取在写时先读出当前版本号,然后加锁操作(比较跟上一次的版本号,如果一样则更新),如果失败则要重复读-比较-写的操作
var Rlock sync.RWMutex func Read(wg *sync.WaitGroup) { defer wg.Done() Rlock.RLock() fmt.Println("开始读取") time.Sleep(time.Second) fmt.Println("读取成功") Rlock.RUnlock() } func main1() { var wg = sync.WaitGroup{} wg.Add(6) for i := 0; i < 5; i++ { go Read1(&wg) } go Write1(&wg) wg.Wait() }**悲观锁:**悲观锁是就是悲观思想,即认为写多,遇到并发写的可能性高,每次去拿数据的时候都认为别人会修改,所以每次在读写数据的时候都会上锁,这样别人想读写这个数据就会block直到拿到锁。
func Write1(wg *sync.WaitGroup) { defer wg.Done() Rlock.Lock() fmt.Println("开始写") time.Sleep(time.Second * 10) fmt.Println("写入成功") Rlock.Unlock() } func main1() { var wg = sync.WaitGroup{} wg.Add(6) for i := 0; i < 5; i++ { go Read1(&wg) } go Write1(&wg) wg.Wait() }自旋锁
自旋锁原理非常简单,如果持有锁的线程能在很短时间内释放锁资源,那么那些等待竞争锁的线程就不需要做内核态和用户态之间的切换进入阻塞挂起状态,它们只需要等一等(自旋),等持有锁的线程释放锁后即可立即获取锁,这样就避免用户线程和内核的切换的消耗。线程自旋是需要消耗 cup 的,说白了就是让 cup 在做无用功,如果一直获取不到锁,那线程也不能一直占用 cup 自旋做无用功,所以需要设定一个自旋等待的最大时间。
如果持有锁的线程执行的时间超过自旋等待的最大时间扔没有释放锁,就会导致其它争用锁的线程在最大等待时间内还是获取不到锁,这时争用线程会停止自旋进入阻塞状态。
34、面试遇到的题总结
1、下面代码,有几次错误
func main() {
var x string = nil
if x == nil {
x = "default"
}
fmt.Println(x)
}
答:两次 var x string = nil和 if x == nil
2、下面代码段输出什么?
type Person struct {
age int
}
func main() {
person := &Person{28}
// 1.
defer fmt.Println(person.age)
// 2.
defer func(p *Person) {
fmt.Println(p.age)
}(person)
// 3.
defer func() {
fmt.Println(person.age)
}()
person.age = 29
}
答:29 29 28
3、下面这段代码输出什么?为什么?
type People interface {
Speak(string) string
}
type Student struct{}
func (stu *Student) Speak(think string) (talk string) {
if think == "speak" {
talk = "speak"
} else {
talk = "hi"
}
return
}
func main() {
var peo People = Student{}
think := "speak"
fmt.Println(peo.Speak(think))
}
答:编译错误 Student does not implement People (Speak method has pointer receiver),值类型 Student 没有实现接口的 Speak() 方法,而是指针类型 *Student 实现该方法。
4、下面输出什么?
type Student struct {
Name string
}
func main() {
fmt.Println(&Student{Name: "xxx"} == &Student{Name: "xxx"})
fmt.Println(Student{Name: "xxx"} == Student{Name: "xxx"})
}
答:指针是取地址
false
true
5、下面代码会报错吗?
func main() {
fmt.Println([...]string{"1"} == [...]string{"1"})
fmt.Println([]string{"1"} == []string{"1"})
}
答:数组只能与相同纬度⻓度以及类型的其他数组⽐较,切⽚之间不能直接⽐较。
35、面试中被问到WebSocket与Socket、TCP、HTTP的关系及区别
1.什么是WebSocket及原理
WebSocket是HTML5中新协议、新API。 WebSocket从满足基于Web的日益增长的实时通信需求应运而生,解决了客户端发起多个Http请求到服务器资源浏览器必须要在经过长时间的轮询问题,实现里多路复用,是全双工、双向、单套接字连接,在WebSocket协议下服务器和客户端可以同时发送信息。
原理:
WebSocket 同 HTTP 一样也是应用层的协议,但是它是一种双向通信协议,是建立在 TCP 之上的。
2.理解各种协议和通信层、套接字的含义
IP:网络层协议;(高速公路)
TCP和UDP:传输层协议;(卡车)
HTTP:应用层协议;(货物)。HTTP(超文本传输协议)是建立在TCP协议之上的一种应用。HTTP连接最显著的特点是客户端发送的每次请求都需要服务器回送响应,在请求结束后,会主动释放连接。从建立连接到关闭连接的过程称为“一次连接”。
SOCKET:套接字,TCP/IP网络的API。(港口码头/车站)Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。socket是在应用层和传输层之间的一个抽象层,它把TCP/IP层复杂的操作抽象为几个简单的接口供应用层调用已实现进程在网络中通信。
Websocket:同HTTP一样也是应用层的协议,但是它是一种双向通信协议,是建立在TCP之上的,解决了服务器与客户端全双工通信的问题,包含两部分:一部分是“握手”,一部分是“数据传输”。握手成功后,数据就直接从 TCP 通道传输,与 HTTP 无关了。
*注:什么是单工、半双工、全工通信?
数据只能单向传送为单工;
数据能双向传送但不能同时双向传送称为半双工;
数据能够同时双向传送则称为全双工。TCP/UDP区别:
TCP(传输控制协议,Transmission Control Protocol):(类似打电话)
面向连接、传输可靠(保证数据正确性)、有序(保证数据顺序)、传输大量数据(流模式)、速度慢、对系统资源的要求多,程序结构较复杂,
每一条TCP连接只能是点到点的,
TCP首部开销20字节。
UDP(用户数据报协议,User Data Protocol):(类似发短信)
面向非连接 、传输不可靠(可能丢包)、无序、传输少量数据(数据报模式)、速度快,对系统资源的要求少,程序结构较简单 ,
UDP支持一对一,一对多,多对一和多对多的交互通信,
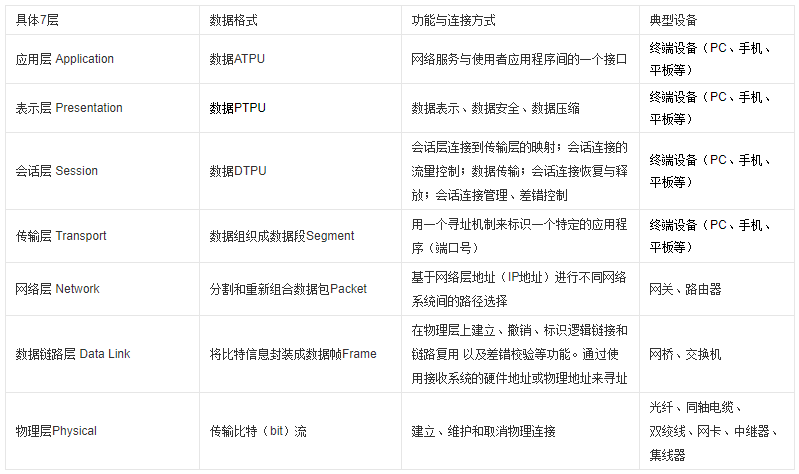
UDP的首部开销小,只有8个字节。简化的TCP/IP四层模型主要分为:应用层、传输层、网络层、数据链路层。
3.WebSocket和Http的关系和异同点
每个WebSocket连接都始于一个HTTP请求。 具体来说,WebSocket协议在第一次握手连接时,通过HTTP协议在传送WebSocket支持的版本号,协议的字版本号,原始地址,主机地址等等一些列字段给服务器端.
Upgrade首部,用来把当前的HTTP请求升级到WebSocket协议,这是HTTP协议本身的内容,是为了扩展支持其他的通讯协议。 如果服务器支持新的协议,则必须返回101.
一个WebSocket连接是在客户端与服务器之间HTTP协议的初始握手阶段将其升级到Web Socket协议来建立的,其底层仍是TCP/IP连接
相同点:
(1)都是建立在TCP之上,通过TCP协议来传输数据。
(2)都是可靠性传输协议。
(3)都是应用层协议。不同点:
(1)WebSocket支持持久连接,HTTP不支持持久连接。(2)WebSocket是双向通信协议,HTTP是单向协议,只能由客户端发起,做不到服务器主动向客户端推送信息。
4.那么为什么说http协议并不是一个持久连接的协议呢?
(1)Http的生命周期通过Request来界定,也就是Request一个Response,那么在Http1.0协议中,这次Http请求就结束了。在Http1.1中进行了改进,是的有一个Keep-alive,也就是说,在一个Http连接中,可以发送多个Request,接收多个Response。但是必须记住,在Http中一个Request只能对应有一个Response,而且这个Response是被动的,不能主动发起。
(2)WebSocket是基于Http协议的,或者说借用了Http协议来完成一部分握手,在握手阶段与Http是相同的。
5.WebSocket可以穿越防火墙吗?
WebSocket使用标准的80及443端口,这两个都是防火墙友好协议,Web Sockets使用HTTP Upgrade机制升级到Web Socket协议。HTML5 Web Sockets有着兼容HTTP的握手机制,因此HTTP服务器可以与WebSocket服务器共享默认的HTTP与HTTPS端(80和443)。
6.WebSocket和Socket
Socket 其实并不是一个协议,而是为了方便使用 TCP 或 UDP 而抽象出来的一层,是位于应用层和传输控制层之间的一组接口。 Socket本身并不是一个协议,它工作在OSI模型会话层,是一个套接字,TCP/IP网络的API,是为了方便大家直接使用。
更底层协议而存在的一个抽象层。Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
而WebSocket则是一个典型的应用层协议。7.WebSocket HTTP和TCP/IP
WebSocket和HTTP一样,都是建立在TCP之上,通过TCP来传输数据。
8.Socket和TCP/IP
Socket是对TCP/IP协议的封装,像创建Socket连接时,可以指定使用的传输层协议,Socket可以支持不同的传输层协议(TCP或UDP),当使用TCP协议进行连接时,该Socket连接就是一个TCP连接。


36、redis数据类型分别使用的场景
String——字符串
字符串类型是Redis最基础的数据结构,字符串类型可以是JSON、XML甚至是二进制的图片等数据,但是最大值不能超过512MB。场景:缓存、计数(文章的阅读量,视频的播放量)、共享session、限速(同一个IP同一段时间只能访问不能超过N次)
● Hash——字典
Redis中,哈希类型是指一个键值对的存储结构。哈希类型的内部编码有两种:
ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)同时所有值都小于hash-max-ziplist-value配置(默认64字节)时使用。ziplist使用更加紧凑的结构实现多个元素的连续存储,所以比hashtable更加节省内存。hashtable(哈希表):当ziplist不能满足要求时,会使用hashtable
使用场景:数据库有用户表结构,以id为key,其他字段为value存储。使用哈希存储会比字符串更加方便直观
● List——列表
列表类型用来存储多个有序的字符串,一个列表最多可以存储2^32-1个元素,列表的两端都可以插入和弹出元素。(redis使用双端链表实现的List)使用场景:消息队列(有序)、栈(先进后出)、文章列表(使用命令lrange key 0 9分页获取文章列表)
● Set——集合集合类型也可以保存多个字符串元素,与列表不同的是,集合中不允许有重复元素并且集合中的元素是无序的。一个集合最多可以存储2^32-1个元素。
使用场景:用户标签、抽奖功能(分别抽一等奖、二等奖)
● Sorted Set——有序集合有序集合和集合一样,不能有重复元素。但是可以排序,它给每个元素设置一个score作为排序的依据。最多可以存储2^32-1个元素。
使用场景:排行榜、延迟消息队列(下单系统,下单后需要在15分钟内进行支付,如果15分钟未支付则自动取消订单。将下单后的十五分钟后时间作为score,订单作为value存入redis,消费者轮询去消费,如果消费的大于等于这笔记录的score,则将这笔记录移除队列,取消订单)
37、Redis的持久化是什么
RDB持久化:该机制可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)。
AOF持久化:记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数
据集。AOF文件中的命令全部以Redis协议的格式来保存,新命令会被追加到文件的末尾。Redis还可以
在后台对AOF文件进行重写(rewrite),使得AOF文件的体积不会超出保存数据集状态所需的实际大
小。
AOF和RDB的同时应用:当Redis重启时,它会优先使用AOF文件来还原数据集,因为AOF文件保存的数
据集通常比RDB文件所保存的数据集更完整。
38、redis中持久化RDB和AOF优缺点
RDB的优缺点?
优点:RDB是一个非常紧凑(compact)的文件,它保存了Redis在某个时间点上的数据集。这种
文件非常适合用于进行备份:比如说,你可以在最近的24小时内,每小时备份一次RDB文件,并
且在每个月的每一天,也备份一个RDB文件。这样的话,即使遇上问题,也可以随时将数据集还原
到不同的版本。RDB非常适用于灾难恢复(disaster recovery):它只有一个文件,并且内容都非
常紧凑,可以(在加密后)将它传送到别的数据中心,或者亚马逊S3中。RDB可以最大化Redis的
性能:父进程在保存RDB文件时唯一要做的就是fork出一个子进程,然后这个子进程就会处理接下
来的所有保存工作,父进程无须执行任何磁盘I/O操作。RDB在恢复大数据集时的速度比AOF的恢
复速度要快。
缺点:如果你需要尽量避免在服务器故障时丢失数据,那么RDB不适合你。虽然Redis允许你设置
不同的保存点(save point)来控制保存RDB文件的频率,但是,因为RDB文件需要保存整个数据
集的状态,所以它并不是一个轻松的操作。因此你可能会至少5分钟才保存一次RDB文件。在这种
情况下,一旦发生故障停机,你就可能会丢失好几分钟的数据。每次保存RDB的时候,Redis都要
fork()出一个子进程,并由子进程来进行实际的持久化工作。在数据集比较庞大时,fork()可能会非
常耗时,造成服务器在某某毫秒内停止处理客户端;如果数据集非常巨大,并且CPU时间非常紧张
的话,那么这种停止时间甚至可能会长达整整一秒。
AOF的优缺点?
● 优点:
使用AOF持久化会让Redis变得非常耐久(much more durable):你可以设置不同的fsync策略,比如
无fsync,每秒钟一次fsync,或者每次执行写入命令时fsync。AOF的默认策略为每秒钟fsync一次,在
这种配置下,Redis仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据
(fsync会在后台线程执行,所以主线程可以继续努力地处理命令请求)。AOF文件是一个只进行追加
操作的日志文件(append onlylog),因此对AOF文件的写入不需要进行seek,即使日志因为某些原因
而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机,等等),redis-check-aof工具也可
以 轻易地修复这种问题。
Redis可以在AOF文件体积变得过大时,自动地在后台对AOF进行重写:重写后的新AOF文件包含了恢复
当前数据集所需的最小命令集合。整个重写操作是绝对安全的,因为Redis在创建新AOF文件的过程
中,会继续将命令追加到现有的AOF文件里面,即使重写过程中发生停机,现有的AOF文件也不会丢
失。而一旦新AOF文件创建完毕,Redis就会从旧AOF文件切换到新AOF文件,并开始对新AOF文件进行
追加操作。
● 缺点:
对于相同的数据集来说,AOF文件的体积通常要大于RDB文件的体积。根据所使用的fsync策略,AOF的
速度可能会慢于RDB。在一般情况下,每秒fsync的性能依然非常高,而关闭fsync可以让AOF的速度和
RDB一样快,即使在高负荷之下也是如此。不过在处理巨大的写入载入时,RDB可以提供更有保证的最
大延迟时间(latency)。
AOF在过去曾经发生过这样的bug:因为个别命令的原因,导致AOF文件在重新载入时,无法将数据集
恢复成保存时的原样。(举个例子,阻塞命令BRPOPLPUSH就曾经引起过这样的bug。)测试套件里为
这种情况添加了测试:它们会自动生成随机的、复杂的数据集,并通过重新载入这些数据来确保一切正
常。虽然这种bug在AOF文件中并不常见,但是对比来说,RDB几乎是不可能出现这种bug的。
39、说一下go的逃逸分析
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
(举个例子,阻塞命令BRPOPLPUSH就曾经引起过这样的bug。)测试套件里为
这种情况添加了测试:它们会自动生成随机的、复杂的数据集,并通过重新载入这些数据来确保一切正
常。虽然这种bug在AOF文件中并不常见,但是对比来说,RDB几乎是不可能出现这种bug的。
39、说一下go的逃逸分析
[外链图片转存中…(img-tAFQaJjh-1715413754379)]
[外链图片转存中…(img-t3sTGfKd-1715413754380)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 860
860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









